使用Pig进行大规模网络数据挖掘
需积分: 4 15 浏览量
更新于2024-09-18
收藏 430KB PDF 举报
“使用Yahoo Pig进行大规模Web数据挖掘的演示”
在大数据处理领域,Web规模的数据挖掘是一个关键任务,而Yahoo的Pig工具为此提供了有效的解决方案。Pig是一种高级数据流语言,设计用于处理和分析大规模数据集,尤其适合于Web规模的数据。它具有类似SQL的语法,支持选择、连接、分组等操作,使得数据处理变得更加简单和直观。
Pig的核心优势在于其隐藏了MapReduce的底层实现细节,用户无需深入了解分布式计算原理,就能轻松使用。此外,Pig内置了许多函数,并且可以通过用户定义的函数(UDF)和流处理进一步扩展其功能,这极大地提高了灵活性和可定制性。
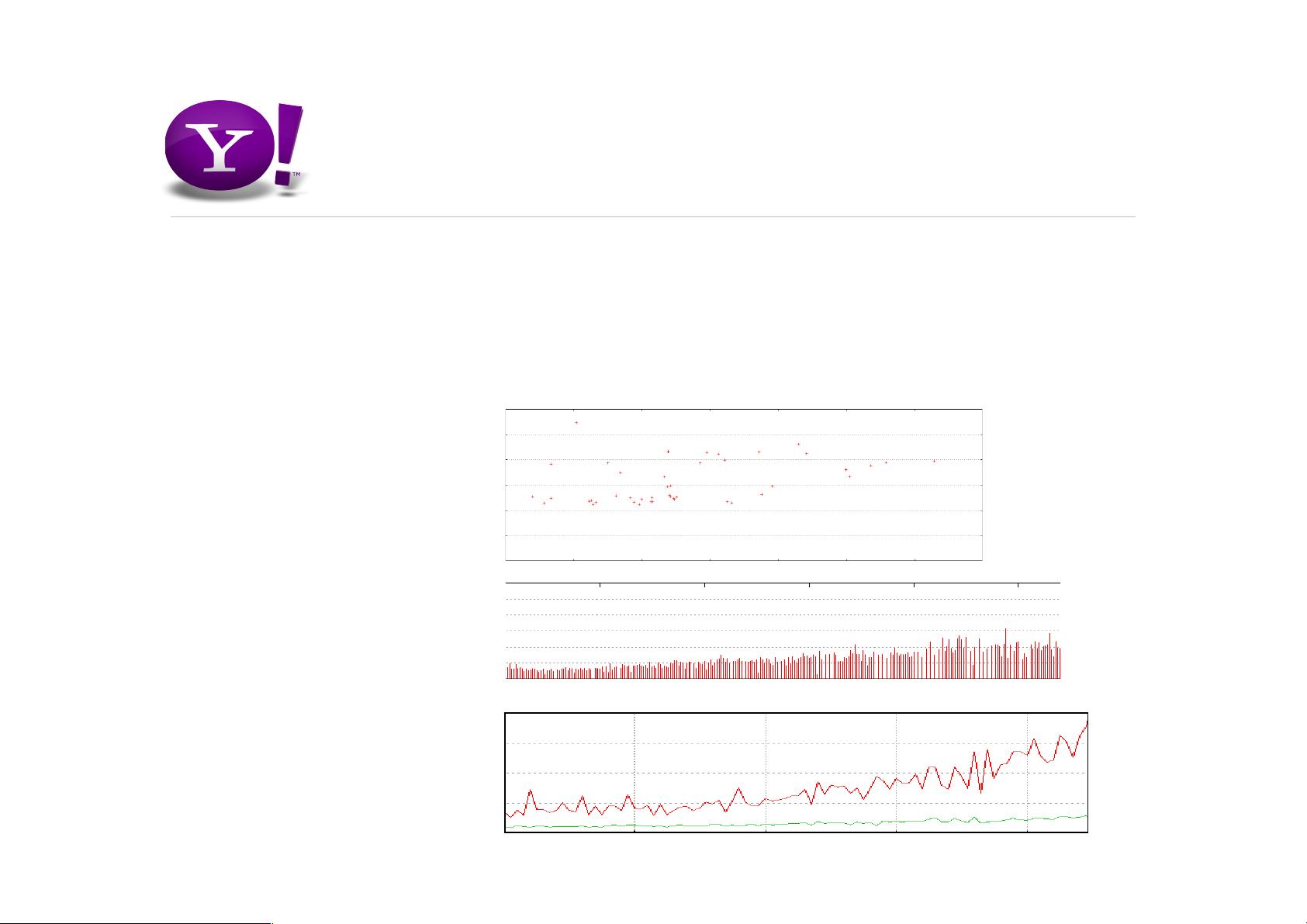
以一个排名模型评估的示例来说明Pig的应用,排名模型是决定哪些广告将被显示的关键部分。我们需要通过比较模型预测的排名与实际点击率(CTR)来评估模型的效果。期望得到的结果包括散点图和相关性分析、排名分布以及CTR与排名的关系。
数据概览显示,我们有两类事件数据:服务于广告展示的“Serve events”和记录用户点击行为的“Click events”。每类事件包含唯一ID、显示的广告信息以及模型给出的每个广告的评分。每天的数据量可能达到数百GB,这是一个典型的Web规模数据挖掘问题。
解决这个问题的关键在于核心数据的提取和结果的生成。我们需要从输入数据中提取出每个<url, ad, score>三元组对应的展示次数和点击次数。这一步骤涉及到如何有效地从原始输入中抽取所需信息,以及如何在分布式环境中生成网格化的结果数据。
在Pig中,可以编写脚本来完成这个转换,例如将<url, ad, score>转化为<impression, click>的形式,以便进行后续的分析。然而,面临的问题是如何高效地从大量数据中提取这些信息,并生成满足分析需求的结构化数据。这通常需要设计合理的数据处理逻辑,利用Pig的函数和操作来完成数据清洗、转换和聚合。
在处理Web规模的数据时,性能优化和资源管理也是重要的考虑因素。Pig提供了优化器来自动调整执行计划,但用户可能还需要手动调整数据分区策略、并行度设置等,以确保处理效率和系统稳定性。
Pig作为一个强大的数据挖掘工具,能够有效地处理Web规模的数据,简化大规模数据处理的复杂性,同时提供足够的灵活性来适应各种数据分析任务。通过掌握Pig,数据科学家和工程师能够在海量数据中发现有价值的信息,支持业务决策和模型优化。
Y! Open Source
Example: ranking model evaluation
Background
• Ranking model decides which ads will be displayed.
• We should evaluate the model by compare rank with real CTR.
Expected result
• Scatter & correlation
• Rank distribution
• CTR vs. Rank
剩余12页未读,继续阅读
2019-10-11 上传
2019-01-30 上传
2019-07-05 上传
2010-11-07 上传
184 浏览量
2021-02-07 上传
2021-05-31 上传

leonyanj
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Linux系统指令大全.pdf
- 深入浅出Struts2.pdf
- Pro Ado.net Data Services
- vim中文用户手册 学习vi
- 基于单片机的智能台灯设计与制作
- Serial Port Complete 2nd 英文版 PDF
- fedora中文版安装及配置常见问题解答
- fedora 10安装指南
- ARM Manual (ARM英文操作手册)2
- The Verilog Hardware Description Language 5th Edition
- vb图书管理系统论文
- more effective C++
- Struts in Action 中文版
- MFC程序中类之间变量的互相访问
- 带串行口通信汉字点阵屏的研究与实现
- 先进算法讲义——中科大
