"介绍K-Means改进算法及基础聚类思想"
需积分: 0 43 浏览量
更新于2024-01-21
收藏 979KB PDF 举报
机器学习中的聚类算法是一种无监督学习方法,其目的是根据数据的内部特征将其划分为不同的类别,使得同一类别内的数据比较相似。本章将介绍三种聚类思想以及对应的聚类算法。
首先,我们需要了解聚类算法的基本思想。聚类算法的核心思想是“物以类聚,人以群分”,即通过计算样本之间的相似度来将数据划分为不同的类别。为了衡量样本之间的相似度,我们可以使用不同的相似度度量方法。
一种常用的相似度度量方法是闵可夫斯基距离(Minkowski距离)。当闵可夫斯基距离的参数p为1时,计算得到的就是曼哈顿距离。闵可夫斯基距离的计算公式如下(以二维空间为例):
d = (|x1 - x2|^p + |y1 - y2|^p)^(1/p)
其中,(x1, y1)和(x2, y2)是两个样本的坐标。通过计算样本之间的闵可夫斯基距离,我们可以得到它们的相似度。
接下来,我们介绍K-Means算法,这是一种经典的聚类算法。K-Means算法的基本原则是在聚类中心的初始化过程中,使得初始的聚类中心之间的相互距离尽可能远,以避免出现一些问题。具体而言,K-Means算法的工作流程如下:
1. 初始化K个聚类中心的位置。
2. 将每个样本分配给离其最近的聚类中心。
3. 更新每个聚类中心的位置,即将每个聚类内的样本的均值作为新的聚类中心。
4. 重复步骤2和步骤3,直到聚类中心的位置不再改变或达到最大迭代次数。
K-Means算法的优化方法有很多种,下面介绍几种常用的优化方法:
1. K-Means++算法:该算法改进了聚类中心的初始化过程,使得初始的聚类中心之间的相互距离更加均匀,从而提高了聚类算法的性能。
2. Mini-Batch K-Means算法:该算法对于大规模数据集的聚类效果更好,它在每次迭代中只使用部分样本来计算聚类中心的更新。
3. 加权K-Means算法:该算法考虑了样本的权重信息,使得不同样本对于聚类中心的贡献不同。
除了K-Means算法,还有一种常用的聚类算法是密度聚类。密度聚类算法的核心思想是基于样本的密度来进行聚类,而不是基于欧氏距离或闵可夫斯基距离。常见的密度聚类算法有DBSCAN算法和OPTICS算法等。
总之,本章介绍了机器学习中的聚类算法,包括K-Means算法及其改进的算法以及密度聚类算法。通过合理选择相似度度量方法和聚类算法,我们可以将数据划分为不同的类别,从而实现无监督学习和数据分析的目标。
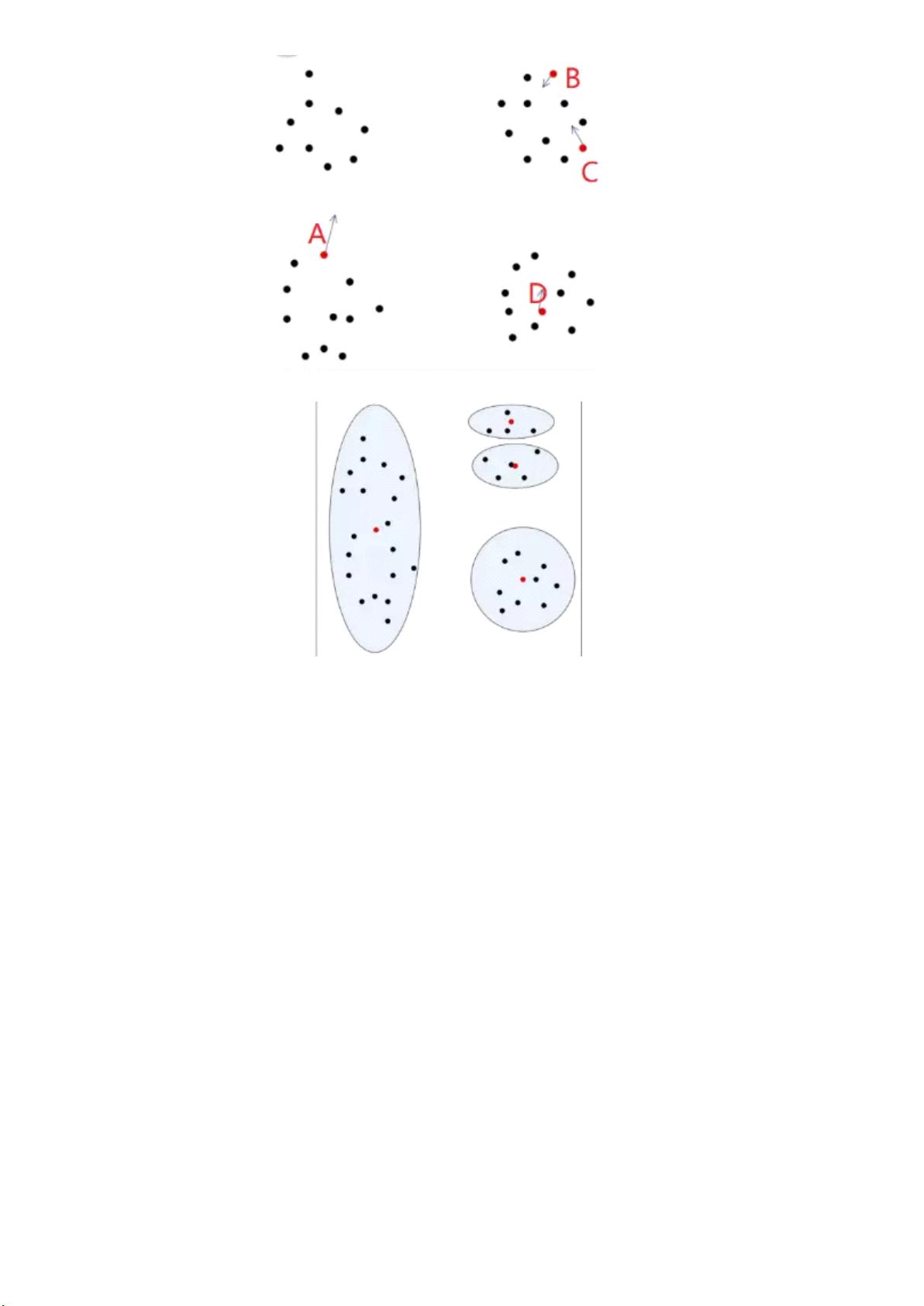
我们按照 K-Means算法划分的结果如图9.4所示:
K-Means例题(略)
K-Means改进的几种算法
前面简单地介绍了一种聚类算法思想K-Means算法,由于K-Means算法的简单且易于实现,因此K-
Means算法得到了很多的应用,但是从K-Means算法的过程中发现,K-Means算法中的聚类中心的
个数k需要事先指定,这一点对于一些未知数据存在很大的局限性。其次,在利用K-Means算法进行
聚类之前,需要初始化k个聚类中心,在上述的K-Means算法的过程中,使用的是在数据集中随机选
择最大值和最小值之间的数作为其初始的聚类中心,但是聚类中心选择不好,对于K-Means算法有
很大的影响。介绍几种K-Means改进的算法。
K-Means++算法
K-Means++算法在聚类中心的初始化过程中的基本原则是使得初始的聚类中心之间的相互距离尽可
能远,这样可以避免出现上述的问题。从而可以解决K- Means算法对初始簇心比较敏感的问题,K-
Means++算法和K- Means算法的区别主要在于初始的K个中心点的选择方面。
q 从数据集中任选一个节点作为第一个聚类中心
1.
q 对数据集中的每个点ⅹ,计算x到所有已有聚类中心点的距离和D(X),基于D(X)采用线性概率
(每个样本被选为下一个中心点的概率)选择出下一个聚类中心点距离较远的一个点成为新增
2.
K- Means算法使用随机给定的方式,K- Means++算法采用下列步骤给定K个初始质点:
分区 计算机专业课 的第
5
页
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-09-01 上传
2023-07-12 上传
2021-09-06 上传
2015-11-04 上传

Unique先森
- 粉丝: 32
- 资源: 327
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
