MyBatis实现读写分离:Spring集成与代码优化
需积分: 49 77 浏览量
更新于2024-09-09
2
收藏 392KB DOCX 举报
在IT行业中,MyBatis作为一种流行的持久层框架,经常被用于Java应用程序的数据访问。当面临高并发且读多写少的应用场景时,实现读写分离是一个有效的优化策略。本文将探讨如何利用MyBatis与Spring集成来实现实时的读写分离,以提升系统的性能和可用性。
首先,为了进行MyBatis的读写分离实验,你需要准备好相应的开发环境,包括Eclipse作为IDE,集成Maven以管理和构建项目,以及至少两台MySQL数据库服务器,用于主从复制。在硬件资源方面,通过增加从库,可以分散主库的读取压力,从而提高整体处理能力。然而,这可能导致从库的响应时间增加,因为它们需要处理部分读请求。
Spring与MyBatis的集成通常是通过Spring的依赖注入和自动扫描机制完成的。主要使用的jar包包括Spring的核心库和MyBatis的mybatis-spring.jar。集成方式有多种,如逐个配置Mapper接口或者通过整包扫描的方式自动识别和管理Mapper接口。其中,MapperScannerConfigurer是Spring对MapperFactoryBean的一种增强,它提供了更便捷的扫描和管理Mapper的能力,比如ClassPathMapperScanner类。
实现读写分离的关键在于修改mybatis-spring.jar中的源码。具体来说,可以考虑在MapperScannerConfigurer中添加逻辑,根据业务需求动态地决定某个操作是发送到主库还是从库。这可能涉及到对AOP(面向切面编程)的使用,通过拦截器来判断执行SQL的上下文,然后决定路由到哪个数据库节点。
在实际操作中,需要关注以下几个主要修改点:
1. 分析MapperScannerConfigurer的工作流程,找出插入读写分离逻辑的合适位置。
2. 编写自定义的拦截器或策略,根据某些条件(如操作类型、数据量等)来选择执行数据库。
3. 配置和测试,确保修改后的代码能够正确地将读写请求导向不同的数据库。
最后,关于参考文献,文章提到的<http://blog.csdn.net/hupanfeng/article/details/21454847> 和 <http://jinnianshilongnian.iteye.com/blog/1720618> 提供了深入的实践指导和技术细节,阅读这些资料可以帮助你更好地理解和实施MyBatis的读写分离策略。
通过定制Spring和MyBatis的集成,结合AOP技术,我们可以灵活地在应用中实现读写分离,优化系统性能,降低锁竞争,同时注意在配置时避免过多主库带来的额外开销。这是一项在高并发环境下提高系统可用性和响应速度的重要技术实践。
三人行科技工作室 QQ 群:476328486 Mail:zfj321@qq.com
MyBatis 做读写分离
一、 实验前准备
1. 能熟练使用 MyBas、Spring
2. 了解读写分离的使用场景、好处
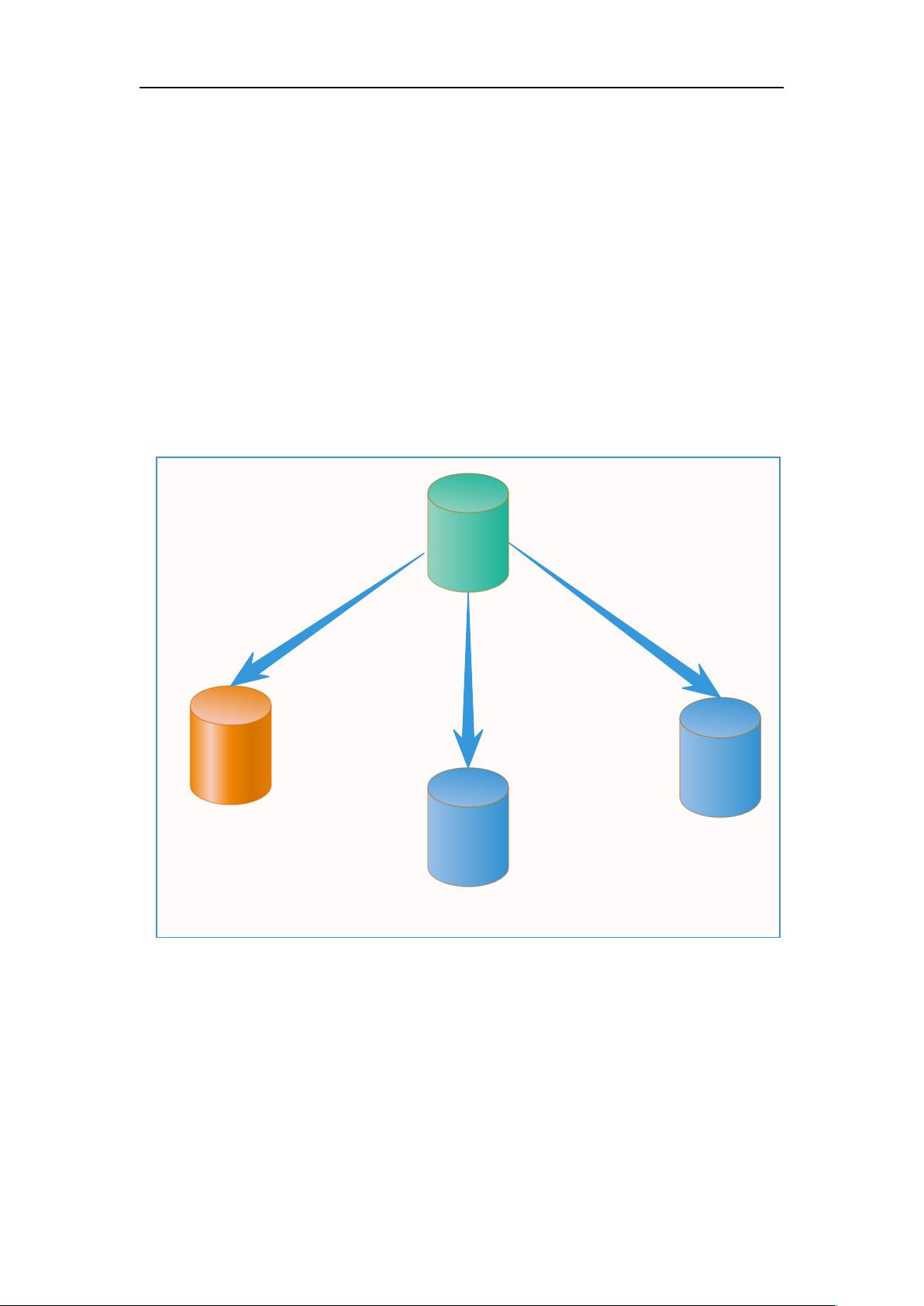
( )主库 读写
( )主备 读写
1( )从库 只读
. . . . .
从库
N
( )只读
a. 读写分离适合读多写少的应用。
b. 增加了硬件资源,主库读压力减少。
c. 从库可能会有一定的延迟。
d. 读写分离会减少一些锁冲突的问题。
e. 基于 MySQL 的读写分离的架构,是一种低成本的方案。
f. 配置 Mysql 的主从时候,要避免多个主库,这样主库间的双向复制会增加系统开销。
下载后可阅读完整内容,剩余4页未读,立即下载
2020-08-31 上传
2017-10-27 上传
2023-09-19 上传
2023-09-13 上传
2023-09-04 上传
2024-11-16 上传
2024-03-22 上传
2023-03-31 上传









