京东深度学习广告算法:LADDER驱动大规模实时拍卖
需积分: 6 44 浏览量
更新于2024-09-11
收藏 1.05MB PDF 举报
京东深度学习广告算法论文提出了一种创新的方法,名为LADDER(Large-Scale Advertiser Deep Reinforcement Learning Agent),这是首个能够直接从原始输入——包含高阶语义信息的实时大规模在线拍卖游戏状态描述中学习控制策略的深度强化学习(Deep Reinforcement Learning, DRL)智能体。LADDER的核心是基于一个异步的随机变体深度Q网络(Asynchronous Stochastic DQN, DASQN),这使得它能够在复杂且信息不完全的环境中做出高效决策。
论文的主要关注点在于如何将这种高级别的智能应用到实际的商业场景中,特别是在京东的在线实时竞标(Real-time Bidding, RTB)广告业务中。与传统的由人类专家精心设计和调优的策略相比,LADDER展示了显著的优势。在京东618大促期间,通过使用LADDER,该公司的广告利润得到了显著提升,证明了深度学习算法在广告投放策略优化中的潜力和价值。
LADDER的设计巧妙地结合了深度学习模型的强大处理能力,能够理解文本描述的状态并从中提取关键信息,与强化学习的试错学习机制相结合,使系统能够在不断与环境交互的过程中逐步优化其决策策略。这种实时的、数据驱动的广告投放策略能够动态适应市场变化,提高广告效果,从而推动业务增长。
论文的重要贡献在于它不仅展示了深度强化学习在广告领域的实际应用,还展示了如何解决大规模、高复杂度问题时,利用深度学习的灵活性和效率来超越人工设计的规则。这不仅对京东自身的广告业务产生了积极影响,也为其他电子商务和广告平台提供了新的思考方向和实践案例,预示着人工智能在广告行业的广泛应用和未来发展可能带来的变革。
LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time
Online Auctions
Yu Wang, Jiayi Liu, Yuxiang Liu, Jun Hao, Yang He, Jinghe Hu, Weipeng Yan, Mantian Li
Business Growth Division. JD.com.
Beijing, China
{wangyu5, liujiayi5, liuyuxiang1, haojun, landy, hujinghe, paul.yan, limantian}@jd.com
Abstract
We present LADDER, the first deep reinforcement learning
agent that can successfully learn control policies for large-
scale real-world problems directly from raw inputs com-
posed of high-level semantic information. The agent is
based on an asynchronous stochastic variant of DQN (Deep
Q Network) named DASQN. The inputs of the agent are
plain-text descriptions of states of a game of incomplete in-
formation, i.e. real-time large scale online auctions, and the
rewards are auction profits of very large scale. We apply the
agent to an essential portion of JD’s online RTB (real-time
bidding) advertising business and find that it easily beats the
former state-of-the-art bidding policy that had been careful-
ly engineered and calibrated by human experts: during
JD.com’s June 18
th
anniversary sale, the agent increased the
company’s ads revenue from the portion by more than 50%,
while the advertisers’ ROI (return on investment) also im-
proved significantly.
Introduction
Researchers have made great progress recently in learning
to control agents directly from raw high-dimensional sen-
sory inputs like vision in domains such as Atari 2600
games (Mnih et al. 2015), where reinforcement learning
(RL) agents have human-level performance. However,
most real-world problems have high-level semantic infor-
mation inputs rather than sensory inputs, where what hu-
man experts usually do is to read and understand inputs in
plain-text form and act after judging by expertise. Real-
world problems are much more challenging than video
games in that they always have a larger solution space and
in that their states can only be partially observed. Such
real-world problems have not been tackled by any state-of-
the-art RL agents until now.
This paper demonstrates an agent named LADDER for
such a problem. Using a deep asynchronous stochastic Q-
network (DASQN), the agent improves the performance of
JD’s real-time bidding (RTB) ad business.
RTB is the most promising field in online advertising
which greatly promotes the effectiveness of the industry
(Yuan, Wang, and Zhao 2013). A typical RTB environ-
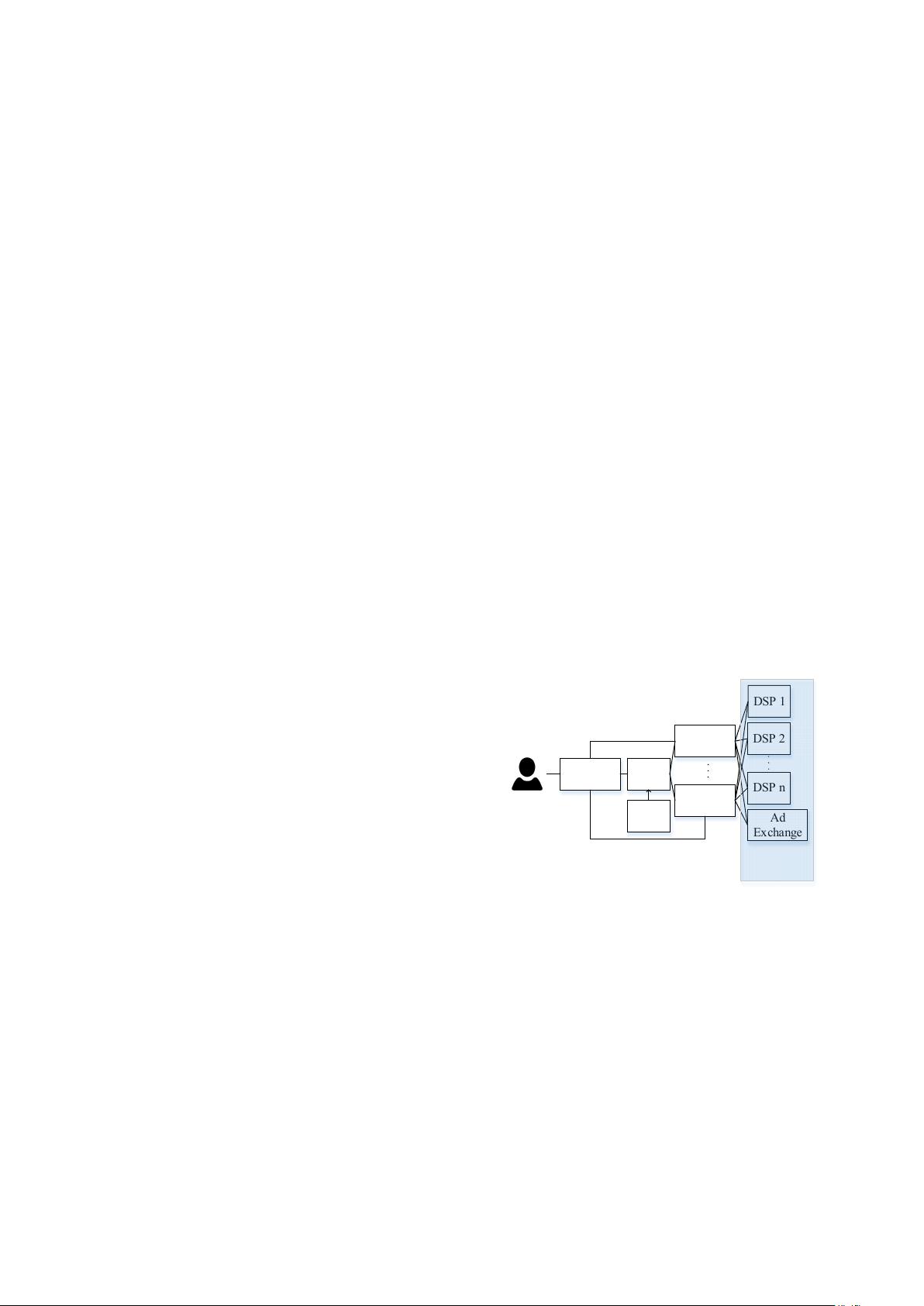
ment (Figure 1) consists of ad exchanges (ADXs), supply
side platforms (SSPs), data management platforms (DMPs)
and demand side platforms (DSPs). ADXs and DSPs uti-
lize algorithms to buy/sell ads in real-time. SSPs integrate
information of publishers (i.e. online media) and offer ads
requests of the publishers to ADXs. An ADX puts the of-
fers out to DSPs for bidding. DSPs target appropriate ads
to the involved user based on information supplied by
DMPs and return the ads with their bids to the ADX which
displays ads of the highest bidder and charges the winner
DSP with general second price (Varian 2007).
Ad
Exchange
DSP 1
DSP 2
DSP n
Ad
Exchange
Ad
Exchange
SSP
DMP
Publisher
intense
competetive
Figure 1: A typical RTB auction environment
Obviously, the process of many DSPs/ADXs bidding for
an ad offer is an auction game (Myerson 1981) of incom-
plete information. However, the online ads industry just
ignores this fact and considers RTB a solved problem: all
existing DSPs model auction games as supervised learning
(SL) problems by predicting the click through rate (CTR)
(McMahan et al. 2013) or conversion rate (CVR) (Yuan,
Wang, and Zhao 2013) of ads and using effective cost per
mille (ECPM) as bids (Chen et al. 2011).
下载后可阅读完整内容,剩余7页未读,立即下载

ghxyydx_biggao
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
