C语言实现的英文词典自动化排版系统
版权申诉
22 浏览量
更新于2024-07-02
收藏 210KB DOC 举报
"C语言课设之英文词典排版系统.doc"
这篇文档详细介绍了用C语言实现的一个英文词典排版系统,旨在解决传统人工排版效率低、易出错的问题。系统通过自动化的方式,读取零散的单词,按照首字母顺序进行存储和排版,提升了工作效率。程序主要由以下几个部分组成:
1. **需求分析**:明确系统需具备输入和显示单词、识别单词、排除重复单词、按字母顺序排列、文本存储结果以及添加新单词并重新排版的功能。
2. **总体设计**:这部分可能涵盖了系统架构的设计,包括如何组织代码,以及选用的数据结构等。
3. **详细设计**:深入到代码层面,如主函数的设计以及各个功能模块的实现。例如,主函数可能负责整个流程的控制,各功能模块可能包括接收用户选项、添加新单词、排序和检查单词等。
- **主函数**:负责程序的流程控制,调用其他功能模块。
- **接收新单词模块**(b(int count)):用于处理用户输入的新单词,确保它们被正确地添加到系统中。
- **排序模块**(c(char* pt[], int count)**:使用指针数组对单词进行排序,但不改变原始数组的位置。
- **检查单词模块**(int check(char arr[], int count)**:检查输入的单词是否合法,同时检查是否存在重复。
- **存储模块**(void storage(char* pt[], int count)**:在程序结束前,将排序后的单词重新写入文件,保持排版。
4. **运行结果展示**:这部分包含了程序运行的截图,直观展示系统的功能和效果。
5. **总结**:对项目实施的总结,可能包括遇到的问题、解决方案以及对未来的改进建议。
6. **参考文献**:可能引用了在开发过程中参考的技术资料或代码片段。
7. **主要符号表**:列出在代码中使用的特定变量和函数原型,便于理解代码逻辑。
在实现上,该系统使用了`stdlib.h`、`string.h`和`ctype.h`等C库,定义了`ROWS`和`COLS`常量来控制字典的大小,使用静态文件指针`fp`和二维字符数组`a[ROWS][COLS]`来存储和处理单词。此外,还有一些自定义的函数,如`get_option()`用于获取用户输入的选项,确保无误操作。
这个C语言课设的英文词典排版系统展示了如何利用编程技术优化传统工作流程,通过结构化数据处理,实现了高效的单词排版和管理。
1 题目要求
. 能输入和显示打入的单词
. 能分辨出单词
. 对重复的单词和已经输入的单词能自动排除
. 能按 4—5 的顺序排版
. 能将运行结果以文本形式存储
. 具有添加新单词并重新排版的能力
6. 数据结构采用指针数组或二维数组。以回车键或者空格键作为单词输入结束标志,
对重复的单词自动排除可选第一张提到的查找方法,数据结构可采用指针和数组
2 需求分析
运行结果以文本形式存储,因而要提供文件的输入输出操作;通过查找操作检查
重复单词;提供排序操作系统实现按 4—5 的顺序排版;提供插入操作添加新单词并重
新排版。另外通过键盘式菜单实现功能选择。
3 总体设计
整个系统呗设计为单词录入模块、文件存储模块和单词浏览模块。其中单词录入
模块要完成输入单词、检查是否重复、排序操作。文件存储模块把存放单词的数组中
的数据写入文件。单词浏览模块完成英文词典的输出,即文件的输出操作。
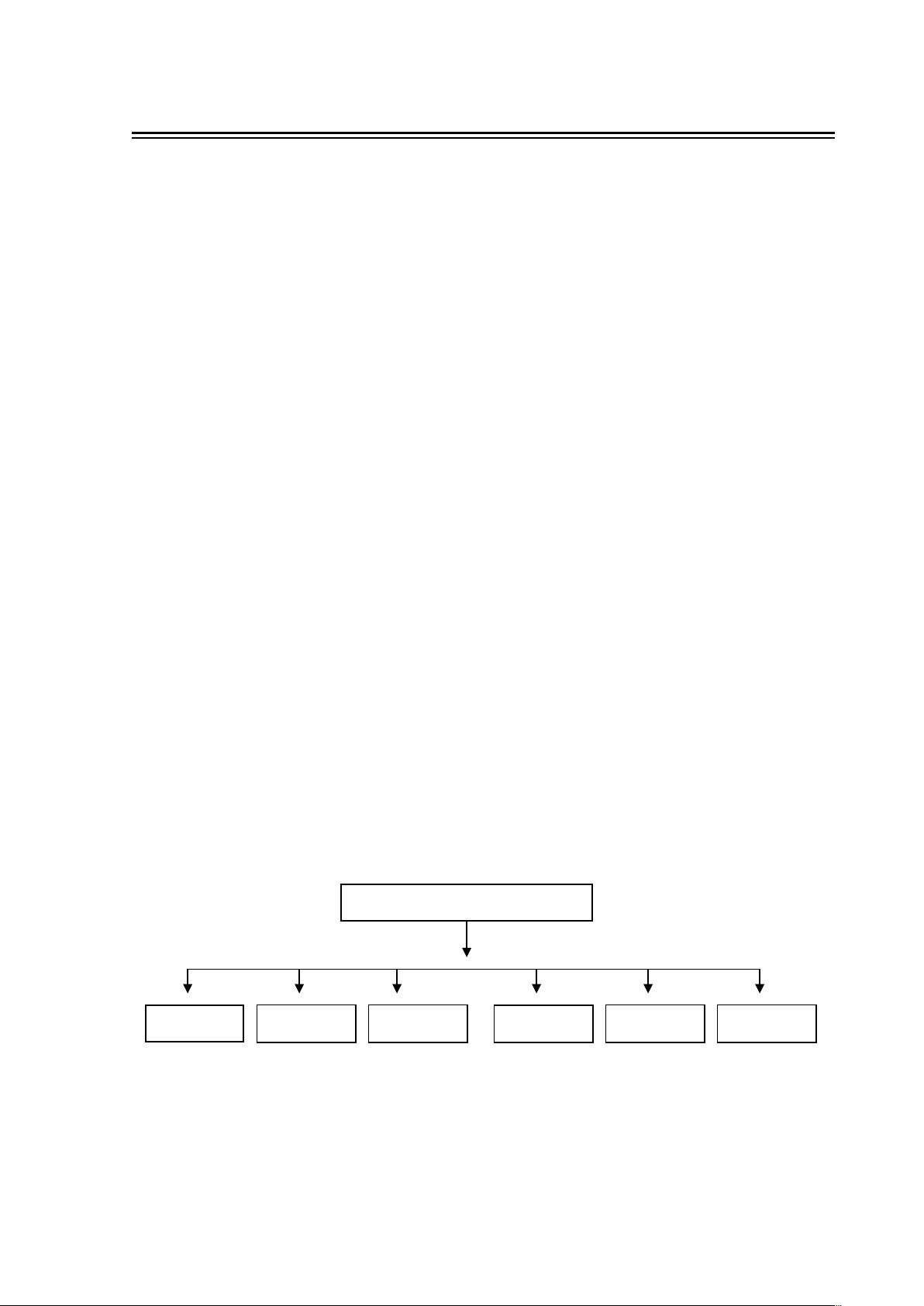
系统功能模块图:
一种简单的英文词典排版系统
单词录入
单词浏览 单词排序
删除单词
单词存储 添加单词
剩余25页未读,继续阅读
2023-06-07 上传
2024-03-08 上传
2024-06-16 上传
2023-12-24 上传
2024-06-17 上传
2024-05-29 上传

智慧安全方案
- 粉丝: 3836
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC++创建和删除快捷方式,添加程序组菜单
- BoltzmannMachinesRPlots
- 4-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- Bluebird.WkBrowser:超级基本的Web浏览器,使用WkWebView和Xamarin.Mac。 旨在作为WkWebView兼容性问题的测试工具
- ReactWebpack
- imageflow-prototype:新 WordPress Image Flow 的工作响应原型 - 不与 WordPress 数据集成
- gfg-coding-problems:解决编码问题
- Mohamed-Bengrich.com
- behrtheme:基于Susty WP的Behr Immobilien的WordPress主题
- symfony-angular-seed:基于API(symfony2)和前端(Angular)的种子项目
- VC++让程序在开机启动时就自动运行
- Gprinter_2020.4_M-2.zip
- AT89S52+AT24C010+DAC0832+MAX7128SLC84-15+按键+LCD+7805组成的原理图和PCB电路
- Frontend-01-模板
- Raw JSON Library:原始JSON库(RJL)是一种高性能JSON(符合RFC 4627)-开源
- 通俗易懂的Go语言教程第4季(含配套资料)
