深度学习入门:从神经元到类神经网络解析
需积分: 12 100 浏览量
更新于2024-09-07
收藏 5.78MB PDF 举报
"这篇文档是为初次接触神经网络和深度学习的人准备的,旨在帮助读者快速理解这些概念。"
深度学习是一种模仿人脑工作原理的计算方法,尤其在处理复杂模式识别和决策任务时表现出色。核心是神经网络,它是通过连接多个简单的计算单元——神经元来构建的模型。神经网络在机器学习领域扮演着重要角色,特别是在图像识别、自然语言处理、语音识别以及许多其他应用中。
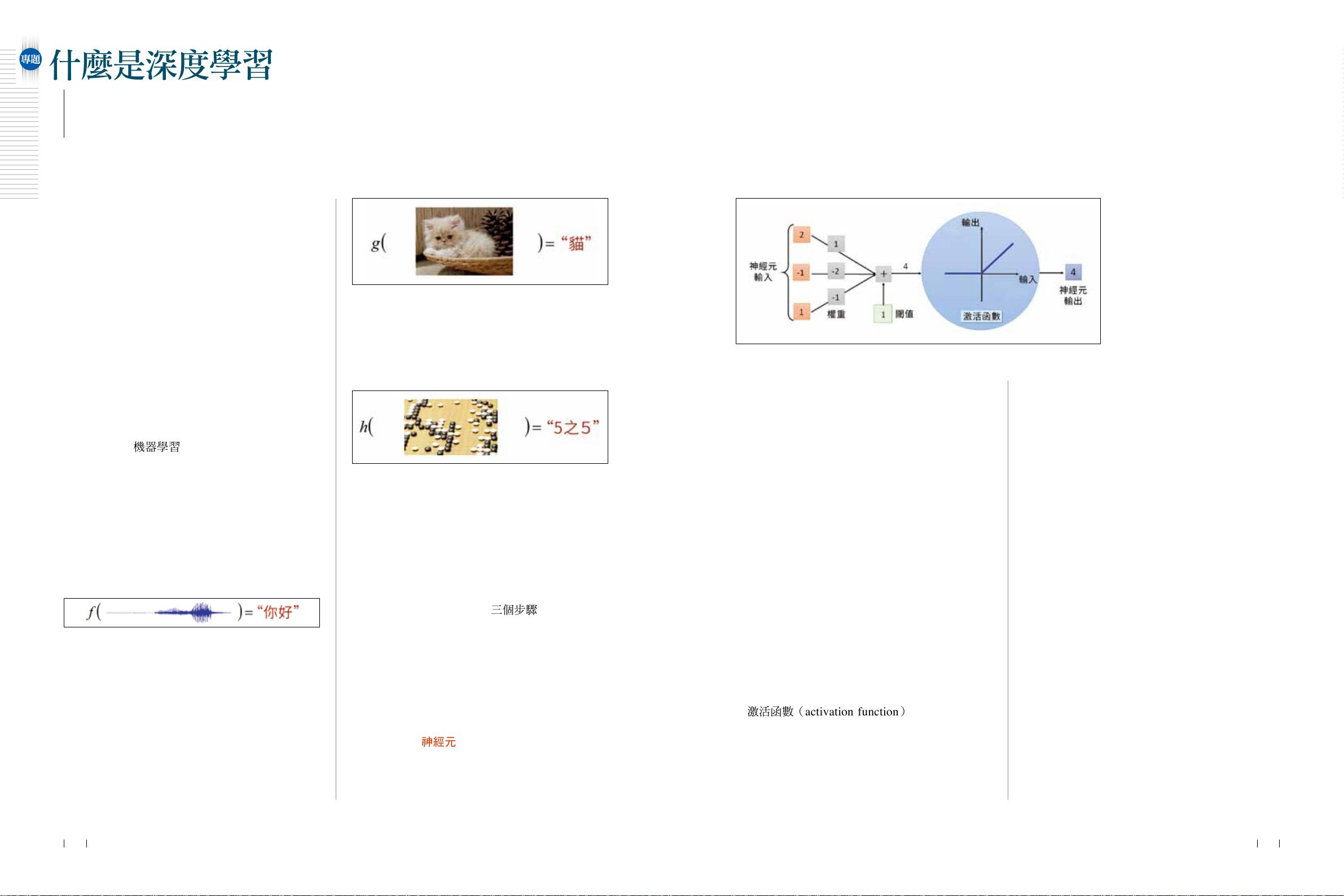
神经元是神经网络的基本构建块。它接收一组输入信号,对每个输入信号乘以其对应的权重,然后加上一个阈值(偏置),最后通过一个激活函数转化为输出。激活函数是神经网络引入非线性的关键,因为它允许神经元对不同强度的输入做出不同的响应。图1中展示的激活函数是整流线性单元(ReLU),当输入小于0时,输出为0,而当输入大于0时,输出等于输入。ReLU因其简单和高效,在现代神经网络中广泛应用。
类神经网络是由多个神经元相互连接形成的网络结构。在图2的例子中,网络由三排神经元组成,每一排的神经元接收前一排的输出作为输入。输入层(上方的橘色方块)接收来自外部环境的数据,例如图像、声音信号或棋盘状态,并将这些数据转化为数值向量。对于28x28像素的黑白图像,其对应的向量维度为784。
网络的训练过程涉及到寻找最优的权重和阈值,以使网络能准确地预测目标变量。这一过程通常通过反向传播算法和梯度下降完成,其中,反向传播用于计算损失函数相对于权重的梯度,梯度下降则用来更新权重以最小化损失。
深度学习之所以被称为“深度”,是因为它可以包含多层神经网络,每一层处理不同级别的特征。随着层数增加,网络可以学习到越来越复杂的表示,从而提升模型的表达能力。这种自动学习和抽象特征的能力是深度学习区别于传统机器学习算法的一大优势。
深度学习和神经网络提供了一种强大的工具,让计算机能够从大量数据中学习并进行预测。虽然初学者可能会被复杂的数学和大量的参数所吓倒,但只要理解了基本的神经元运作机制和网络结构,就能逐步掌握这一领域的知识。这篇文档正是为了简化这个学习过程,帮助那些想要入门的人快速理解和掌握神经网络和深度学习的核心概念。
數 理 人 文
21
數 理 人 文 10
20
輸 出。 圖 1 中 的 激 活 函 數, 其
輸入和輸出的關係如藍色圓域所
示(橫軸代表輸入、縱軸代表輸
出 ), 其 中 當 輸 入 小 於
0 時,
輸出為
0;當輸入大於 0 時,輸
出等於輸入。這種激活函數稱為
整 流 線 性 單 元(
rectified linear
unit
,ReLU), 是 目 前 常 用 的
激活函數。圖
1 中的激活函數輸
入為
4,因為大於 0,故神經元的輸出就是 4。神
經元中的權重和閾值都稱為參數(
parameter),
它們決定了神經元的運作方式。
步驟一:類神經網絡就是函數集
了解神經元後,接著來看類神經網絡。類神經網
絡由很多神經元連接而成,人類只需要決定類神經
網絡的連結方式,機器可以自己根據訓練資料找
出每個神經元的參數。圖
2 是一個類神經網絡的
例子,上方的類神經網絡共有六個神經元,分別排
成三排,橘色方塊代表外界的輸入,外界的輸入可
以是圖片、聲音訊號或棋盤上棋子的位置等等,只
要能以向量(一組數字)表示即可。以圖片為例,
一張
28×28 大小的黑白圖片,可以視為一個 784
(=28×28)維的向量,每一分量對應到圖片中的
一個像素,該分量的值表示像素顏色的深淺,接近
黑色其值就接近
1,反之就接近 0。
來自外界的資訊被輸入給第一排的藍色神經元,
藍色神經元的輸出是第二排黃色神經元的輸入,黃
色神經元的輸出則是下一排綠色神經元的輸入,因
為綠色神經元的輸出沒有再轉給其他神經元,故其
法,相信大家都已耳熟能詳。會有這樣的說法,是
因為深度學習中,人類提供的函數集是由類神經網
絡(
artificial neural network)的結構所定義。
類神經網絡和人腦確實有幾分相似之處,我們都
知道人腦是由神經元(
neuron)所構成,類神經網
絡也是由「神經元」連接而成。類神經網絡中的神
經元構造及其運作方式如圖
1 所示。每個神經元
都是一個簡單的函數,這些函數的輸入是一組數值
(也就是一個向量),輸出是一個數值。以圖
1 的
神經元為例,該神經元的輸入為左側橘色框內的
2、
-1、1 三個數值,輸出為右側藍色框內的數值 4。
那麼,神經元是如何運作的呢?每個輸入都有一
個對應的權重(
weight),圖 1 中每個輸入對應的
權重,分別為灰色框內的
1、-2、-1 三個數值。先
將每個輸入數值和其對應權重相乘後加總,再加上
綠色框內的閾值(
bias)後,其總和便成為神經元
中激活函數(
activation function)的輸入。圖 1 中
激活函數的輸入是
4 ,也就是
2
⇥
1+(
−
1)
⇥
(
−
2)+1
⇥
(
−1)+1=4
激活函數是由人類事先定義好的非線性函數,其
輸入和輸出都是一個數值,而其輸出就是神經元的
輸入一張圖片,輸出是圖片中的物件名稱。
如果要機器下圍棋,就是讓機器根據一堆棋譜找
出「下圍棋的函數」:
輸入是棋盤上所有黑子和白子的位置,輸出是下
一步應該落子的位置。
以上要找的函數,共通點是它們都複雜到人類絕
對沒有能力寫出它們的數學式,只有靠機器才有辦
法找出來。那麼,機器要如何根據訓練資料找到函
數呢?
一般機器學習方法要經過三個步驟:一、人類提
供給機器一個由函數構成的集合(簡稱函數集);
二、人類根據訓練資料定義函數的優劣;三、機器
自動從函數集內找出最佳的函數。深度學習也不例
外。底下我們先介紹深度學習的基本架構,再分別
就這三個步驟來介紹深度學習。
類神經網絡與神經元
「深度學習就是讓機器模擬人腦的運作方式,進
而和人類一樣具備學習的能力。」這個科普的說
自從
2016 年 3 月 AlphaGo 以四比一擊敗李世
乭
以後,
AlphaGo 所使用的深度學習技術引起了各
界的關注。事實上,早在
AlphaGo 問世之前,深
度學習技術即已廣泛應用在各個領域。當我們對
iPhone 的語音助理軟體 Siri 說一句話,Siri 可以將
聲音訊號辨識成文字,用的就是深度學習的技術;
當我們上傳一張相片到
Facebook,Facebook 可以
自動找出相片中的人臉,用的也是深度學習的技
術。其實人們早已享受深度學習所帶來的便利很長
一段時間了。
什麼是深度學習?
深度學習是機器學習的一種方法,「機器學習技
術,就是讓機器可以自我學習的技術。」但實際上
機器是如何學習的呢?一言以蔽之,機器學習就是
讓機器根據一些訓練資料,自動找出有用的函數
(
function)。例如,如果將機器學習技術運用在
語音辨識系統,就是要機器根據一堆聲音訊號和其
對應的文字,找出如下的「語音辨識函數」:
輸入一段聲音訊號,輸出就是該聲音訊號所對應
的文字。
如果機器學習技術應用在影像辨識系統,那就是
要機器根據一堆圖片和圖片中物件名稱的
標註,找
出「影像辨識函數」:
什麼是深度學習
類神經網絡的卷土重來
作者:
李宏毅
李宏毅為臺灣大學電機工程學系助理教授,主要研究領域:機器學習、深度學習、語意理解、語音辨識。
(攝影:ilker)
(圖片來自維基)
圖 1 類神經網絡中單一神經元及其運作方式。
下载后可阅读完整内容,剩余4页未读,立即下载
2021-09-25 上传
3779 浏览量
2022-12-22 上传
2022-07-01 上传
114 浏览量
2022-12-16 上传
2021-12-25 上传
2021-11-18 上传
2023-05-26 上传

三年一班gary
- 粉丝: 443
 我的内容管理
展开
我的内容管理
展开







最新资源
- 轻量级React-TypeScript简历模板下载与使用指南
- 完美解决多浏览器下的表格固定表头问题
- jszmq:实现WebSocket传输的Javascript端口库
- 修改Xcode模板以自定义头文件信息的教程
- 手工绘制浪漫信笺风格PPT模板下载
- C#源码实现波纹特效的全新尝试
- JavaScript打造幽灵行者游戏
- 解决asyncUdpSocket闪退问题的实用方法
- 解析女王VLT1 HTML技术实现
- NixBackup:适用于Nix系统的开源简单备份工具
- Redis与jemalloc内存优化实践分析
- Java实现省市选择联动效果的技术剖析
- 七夕节专属浪漫动画PPT模板设计下载
- 安卓ListView购物车实现功能详解
- C#项目PRT-585开发总结及代码优化
- EasyBuy商城:基于jsp+sql server的完整购物解决方案
