Python爬虫实战:解析下厨房热门菜谱
需积分: 0 91 浏览量
更新于2024-08-03
收藏 1020KB PDF 举报
"Python爬虫(项目实操)"是一个实战导向的教程,主要讲解如何使用Python进行网页数据抓取,特别关注BeautifulSoup库的应用。该课程围绕一个具体的项目——爬取"下厨房"网站的热门菜谱,目标是获取菜名、原材料以及对应菜谱的详细烹饪流程链接。
项目的第一步是分析目标网站,即"下厨房"的robots.txt协议,确保我们的爬虫操作符合网站的规定,避免被封禁。通过查看,我们确认了"本周最受欢迎"栏目是可以爬取的,但需要注意的是,每个具体菜谱的详情页("/recipe/")不在允许爬取的范围内。
获取数据阶段,利用requests库的get()函数来下载页面内容,可能需要添加headers参数以应对反爬策略。一旦获取到HTML数据,就需要用到BeautifulSoup解析。用户将学习如何使用开发者工具定位页面元素,例如找到菜名所在的<a>标签和链接URL,如"/recipe/103646251/",这是后续解析的关键。
解析数据时,BeautifulSoup的强大之处在于它能够根据CSS选择器或标签结构来提取所需信息。通过类名(".page-outer")和标签名("<a>")的组合,用户可以定位到菜名文本和详情页链接。通过这样的方法,学员将深入理解如何在实际项目中应用BeautifulSoup进行数据抽取。
课程不仅教授理论知识,还会分享爬虫项目实战的经验,帮助学员理解爬虫项目的全貌,包括数据获取、数据处理和数据存储等环节。通过这个具体的实例,学员将掌握如何在Python环境中构建和维护一个基本的爬虫系统,并了解在实际项目中遇到问题时的解决策略。整体而言,这是一次结合理论与实践的学习体验,旨在提升学员的网络数据抓取和解析能力。
获取数据是容易的,使⽤requests.get()就能实现。不过由于⽹址反爬策略升级的问题,如果运⾏不成功的话,我们就需要添加headers参数
并在本地运⾏。
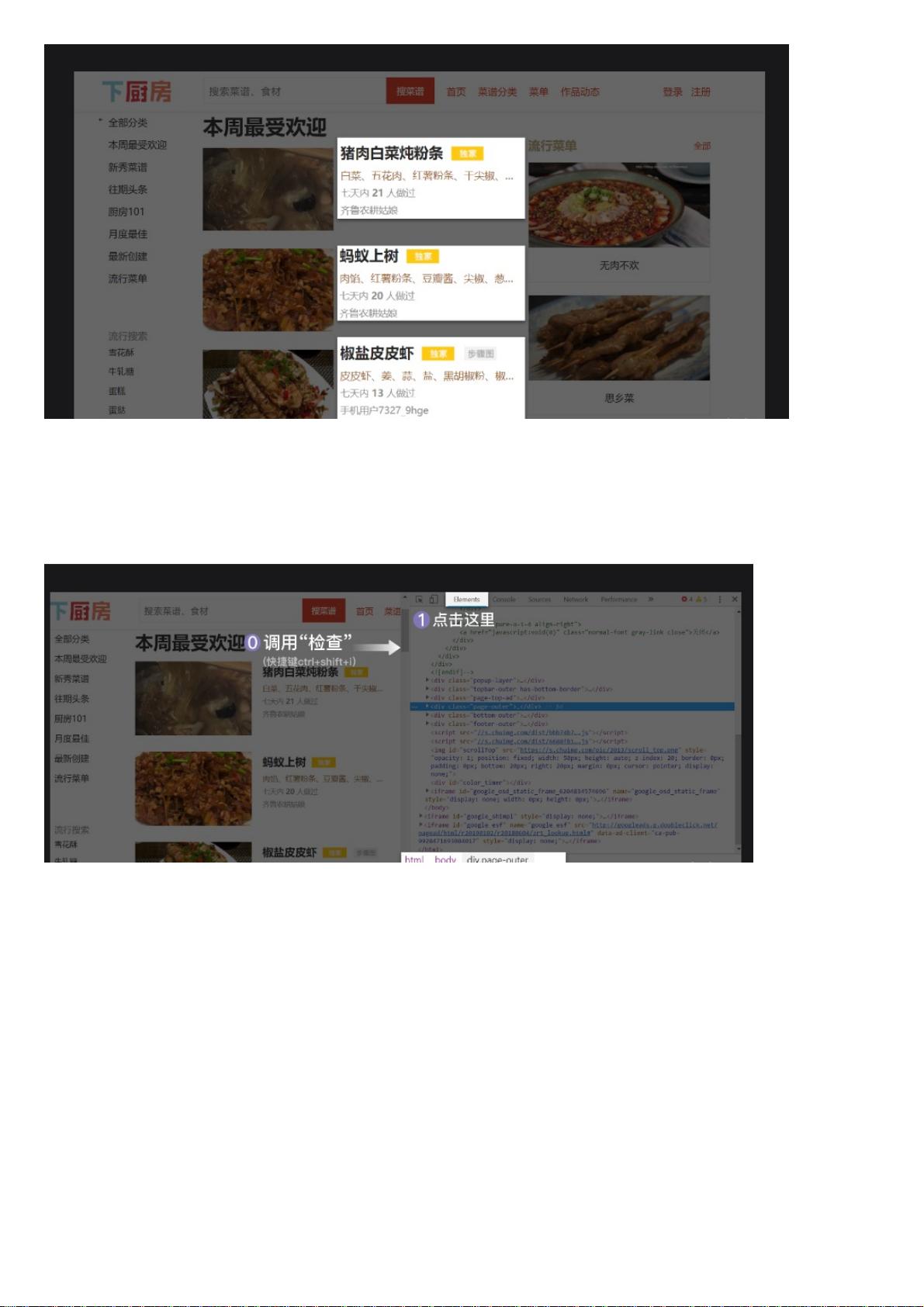
获取完数据后,我们需要⽤BeautifulSoup去解析数据。打开检查⼯具,我们先在Elements⾥查看这个⽹页是怎样的结构。
刚刚打开Elements,它会默认展开body,其余都关闭。我的⿏标悬停在<div class="page-outer">…<div> == $0上,所以你看到下⽅限制的
路径,就是:html > body > div.page-outer。其中.所代表的正是class。
点击开发者⼯具左上⾓的⼩箭头,然后选中⼀个菜名,如我选的就是“猪⾁炖粉条”,那么Elements那边就会⾃动标记出对应的代码。
剩余12页未读,继续阅读
2020-07-21 上传
2023-05-31 上传
2023-08-10 上传
2024-01-16 上传
2024-09-05 上传
2023-12-26 上传
2023-06-01 上传
2023-07-30 上传

sun7bear
- 粉丝: 2
- 资源: 121
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++标准程序库:权威指南
- Java解惑:奇数判断误区与改进方法
- C++编程必读:20种设计模式详解与实战
- LM3S8962微控制器数据手册
- 51单片机C语言实战教程:从入门到精通
- Spring3.0权威指南:JavaEE6实战
- Win32多线程程序设计详解
- Lucene2.9.1开发全攻略:从环境配置到索引创建
- 内存虚拟硬盘技术:提升电脑速度的秘密武器
- Java操作数据库:保存与显示图片到数据库及页面
- ISO14001:2004环境管理体系要求详解
- ShopExV4.8二次开发详解
- 企业形象与产品推广一站式网站建设技术方案揭秘
- Shopex二次开发:触发器与控制器重定向技术详解
- FPGA开发实战指南:创新设计与进阶技巧
- ShopExV4.8二次开发入门:解决升级问题与功能扩展
