Python算法解析与实践指南
"Python算法教程是一本以Python语言为载体,深入浅出地介绍算法分析与设计的书籍。全书包含11章,涵盖了从基础的算法概念到复杂的算法问题解决策略,旨在帮助读者理解并掌握经典算法,提升解决算法问题的能力。书中涉及的主题包括树、图、计数问题、归纳递归、遍历、分解合并、贪心算法、复杂依赖、Dijkstra算法、匹配切割问题以及困难问题及其稀释等。此外,书后还附有加速Python性能、问题与算法列表、图术语词汇表和练习提示等实用资料。"
在这本Python算法教程中,读者将学习到:
1. **第一章:介绍** - 引导读者进入算法的世界,阐述学习算法的重要性,并提供解决问题的一般步骤,包括明确问题和深入思考。
2. **第二章:基础** - 基础知识的学习是关键,本章可能涵盖Python语言的基础语法、数据结构(如列表、字典、栈和队列)以及算法的基本概念。
3. **第三章:计数问题** - 计数是算法中的常见任务,本章将讲解如何有效地计算和处理各种计数问题,可能包括组合计数、排列计数等。
4. **第四章:归纳递归与减少** - 递归是算法设计的重要工具,本章将介绍如何使用归纳法和递归解决复杂问题,以及如何通过问题简化来降低复杂度。
5. **第五章:遍历** - 遍历是许多算法的核心部分,包括深度优先搜索(DFS)和广度优先搜索(BFS),本章将详细介绍这些遍历技术及其在树和图中的应用。
6. **第六章:分解、合并与征服** - 分治策略是一种高效的算法设计方法,本章将讨论如何将大问题拆解为小问题,然后合并解决方案,例如快速排序、归并排序等。
7. **第七章:贪婪算法** - 贪心算法常用于寻找局部最优解以达到全局最优,本章将探讨贪婪策略的原理和应用场景,如霍夫曼编码。
8. **第八章:复杂依赖与记忆化** - 当问题的解决涉及到大量的重复计算时,记忆化技术能提高效率,本章会讲解如何利用动态规划和记忆化技巧来处理复杂依赖问题。
9. **第九章:从A到B,与Edsger和朋友们** - 这一章很可能是关于Dijkstra算法的,Dijkstra是著名的单源最短路径算法,由Edsger Dijkstra提出,用于解决图中的路径查找问题。
10. **第十章:匹配、切割与流** - 匹配和流问题在图论中有广泛的应用,本章可能涵盖最大匹配、网络流等问题。
11. **第十一章:困难问题与有限的粗心** - 对于NP难问题的讨论,可能会介绍如何近似求解以及通过随机化算法处理复杂问题。
除此之外,书中还包括了附录,如A章加速Python性能的技巧,B章列出的问题和算法参考,C章对图论术语的定义,以及D章中对练习题的提示,这些都将有助于读者更好地理解和应用所学的算法知识。这本教程适合Python初学者和有一定经验的开发者,希望提升算法能力的读者。
CHAPTER 2 ■ THE BASICS
13
This is a fairly straightforward and understandable definition, although it may seem a bit foreign at first. Basically,
O(g) is the set of functions that do not grow faster than g. For example, the function n
2
is in the set O(n
2
), or, in set
notation, n
2
∈ O(n
2
). We often simply say that n
2
is O(n
2
).
The fact that n
2
does not grow faster than itself is not particularly interesting. More useful, perhaps, is the fact that
neither 2.4n
2
+ 7 nor the linear function n does. That is, we have both
2.4n
2
+
7 ∈ O(n
2
)
and
n
∈
O(n
2
).
The first example shows us that we are now able to represent a function without all its bells and whistles; we can
drop the 2.4 and the 7 and simply express the function as O(n
2
), which gives us just the information we need. The
second shows us that O can be used to express loose limits as well: Any function that is better (that is, doesn’t grow
faster) than g can be found in O(g).
How does this relate to our original example? Well, the thing is, even though we can’t be sure of the details
(after all, they depend on both the Python version and the hardware you’re using), we can describe the operations
asymptotically: The running time of appending n numbers to a Python list is O(n), while inserting n numbers at its
beginning is O(n
2
).
The other two, W and Q, are just variations of O. W is its complete opposite: A function f is in W(g) if it satisfies the
following condition: There exists a natural number n
0
and a positive constant c such that
f(n)
³
cg(n)
for all n ³ n
0
. So, where O forms a so-called asymptotic upper bound, W forms an asymptotic lower bound.
Note ■ Our first two asymptotic operators, O and W, are each other’s inverses: If f is O(g), then g is W(f ). Exercise 2-3
asks you to show this.
The sets formed by Q are simply intersections of the other two, that is, Q(g) = O(g) ∩ W(g). In other words, a function f is
in Q(g) if it satisfies the following condition: There exists a natural number n
0
and two positive constants c
1
and c
2
such that
c
1
g(n)
£
f(n) £ c
2
g(n)
for all n ³ n
0
. This means that f and g have the same asymptotic growth. For example, 3n
2
+ 2 is Q(n
2
), but we could just
as well write that n
2
is Q(3n
2
+ 2). By supplying an upper bound and a lower bound at the same time, the Q operator is
the most informative of the three, and I will use it when possible.
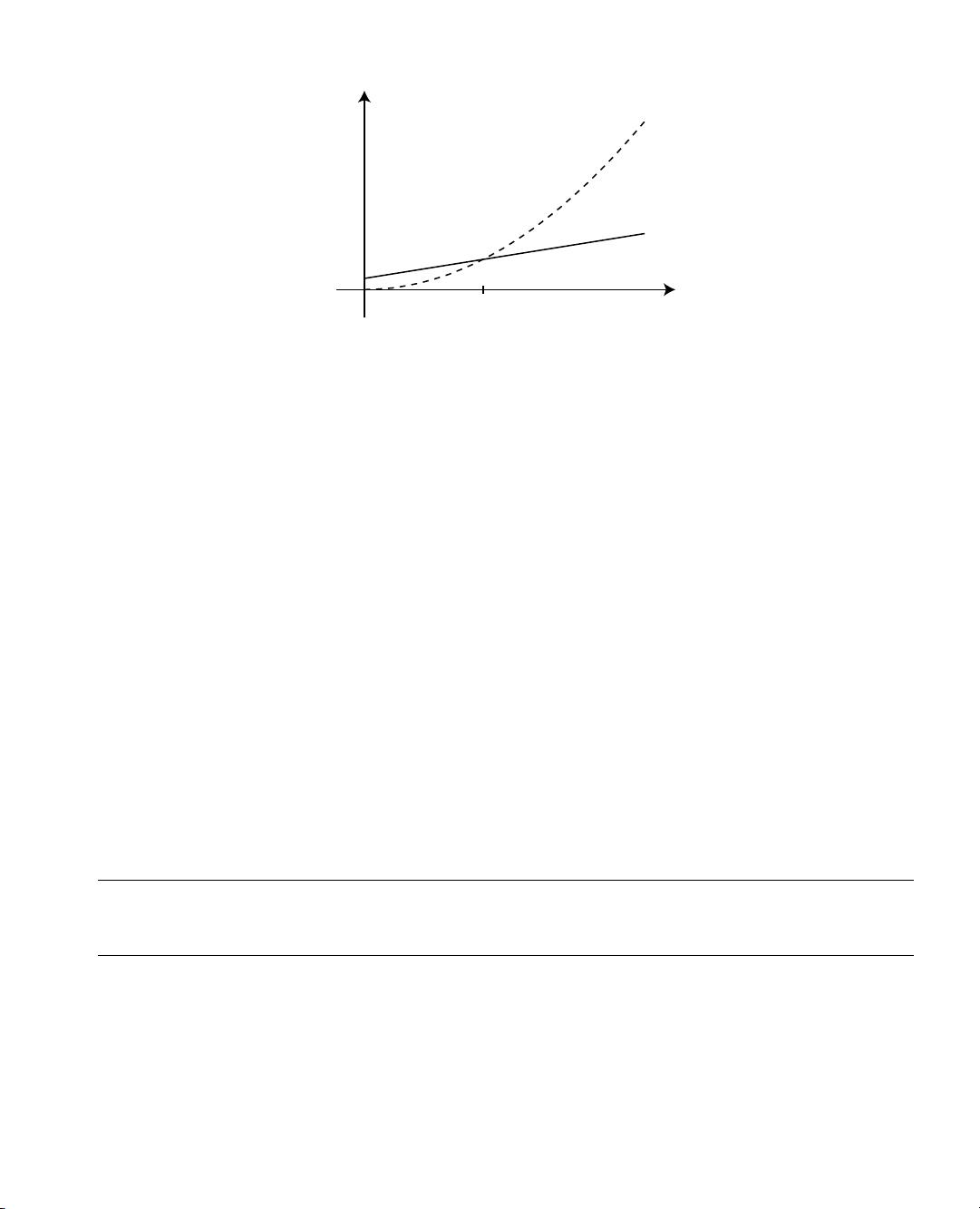
cn
2
T (n )
n
0
Figure 2-1. For values of n greater than n
0
, T(n) is less than cn
2
, so T(n) is O(n
2
)




剩余302页未读,继续阅读
562 浏览量
326 浏览量
257 浏览量
152 浏览量
322 浏览量
103 浏览量
106 浏览量
163 浏览量

yuxi218
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 室内装修官网模板下载:10子页面高端酒店风
- 掌握Vue.js项目:Udemy VueJS教程实战指南
- iOS列表视图下拉效果实现教程
- Java操作MongoDB非关系数据库的实践指南
- 淘宝菜单分类导航的探索与优化方法
- 中科大软件工程考研必备:数据结构资料大全
- 掌握mikes编码博客的创建与发布流程
- 易语言实现清空回收站功能的详细教程
- Whatsmyserp-crx插件:Google搜索关键词研究利器
- PHP开源股票配资源码发布,含完整后台功能
- 内存监控工具展示:深入分析Cool显示技术
- BluePrint2.0: 极坐标系中的点绘制与度量工具
- 实现iOS scrollView的无缝循环滑动效果
- 一键迁移mysql联系人到Google联系人的PHP脚本
- Python实现的HTML文本解析工具介绍
- Chrometana Pro扩展:重定向Cortana到Google Chrome
