改进的语义代码相似度检测方法
167 浏览量
更新于2024-07-14
收藏 974KB PDF 举报
本文主要探讨了"检测语义相似的代码"这一主题,发表在《计算机科学》期刊上,DOI为10.1007/s11704-014-3430-1。作者Tiantian WANG、Kechao WANG、Xiaohong SU和Peijun MA分别来自哈尔滨工业大学计算机科学技术学院和哈尔滨大学软件学院,该研究由高等教育出版社和Springer-Verlag Berlin Heidelberg于2014年联合出版。
传统代码相似性检测方法在识别具有相同功能但实现方式不同的语义相似代码时存在局限性,这限制了它们在实际应用中的效能。为解决这个问题,论文提出了一种结合度量法和图谱法的改进方法。首先,源代码被转换为增强的系统依赖图,这种图能够捕捉代码之间的结构关系。
度量法在此阶段扮演关键角色,通过对代码片段进行比较,筛选出大部分不相似的代码对,从而大大降低了计算复杂性。这种方法着重于代码的功能和结构相似性,而非字面的代码匹配。通过这种方式,研究者可以有效地排除那些表面上看似相似但实际上功能不同的代码。
接着,论文进行了代码规范化步骤,旨在消除代码中的变异性,如变量命名、控制流等,以便能在更高层次上,即语义层面,识别真正的相似代码。这是至关重要的一步,因为它确保了即便代码表面上有所变化,只要其执行逻辑保持一致,也能被正确识别为相似。
最后,程序匹配技术被应用于已筛选和规范化的代码片段上,进一步提升匹配的准确性和效率。整个过程旨在提高代码相似性检测的精确度,使得这项技术能够在软件工程、代码复用、反抄袭等领域发挥更大的作用。
这篇研究论文不仅深入剖析了传统方法的不足,还引入了创新的方法论,以应对语义相似代码的检测问题,为实际应用提供了更为有效和精准的解决方案。这在当前快速发展的软件开发和维护领域具有重要意义。
4 Front. Comput. Sci.
ing facts.
Fact 1 (metrical similar codes) If two code fragments P and
P
are similar under the set of features measured by M,then
the values of M(P)andM(P
) should be proximate [27].
Fact 2 (candidate similar codes) Based on Fact 1, P and P
are cand idate similar codes if the metric sim ilarity between
them is no less than the pr edefined threshold of metric simi-
larity T
m
.
Fact 3 (SDG) SDG is a semantic representation for a pro-
gram. If two programs have the same SDG, they are semanti-
cally equivalent. However, two semantically equivalent pro-
grams may have different SDGs [37,39].
Fact 4 (semantic-preserving transformation) A program
transfor mation is semantic-preserving if it preserves the ex-
ecuting result for the same input. A sufficient sequence of
semantic-pr eserving transformations can normalize semanti-
cally equivalent programs that use the same algorithm into
those having the same SDG [40].
Fact 5 (code normalization) Code normalization is a pro-
cess of performing semantic-preserving transformations on
the SDG of a program according to a set of predefined rules,
so as to transform the semantically equivalent codes to the
same representation.
Fact 6 (semantic similarity) Based on Fact 3, Fact 4 and
Fact 5, the semantic similarity of P and P
can be computed
by matching the normalized SDGs of P and P
.
Fact 7 (semantically similar codes) Based on Fact 2 and Fact
6, P and P
are semantically similar codes if they are candi-
date similar codes and the semantic similar ity between them
is no less than the predefined threshold of semantic similarity
T
s
.
3.3 Model of CMGA
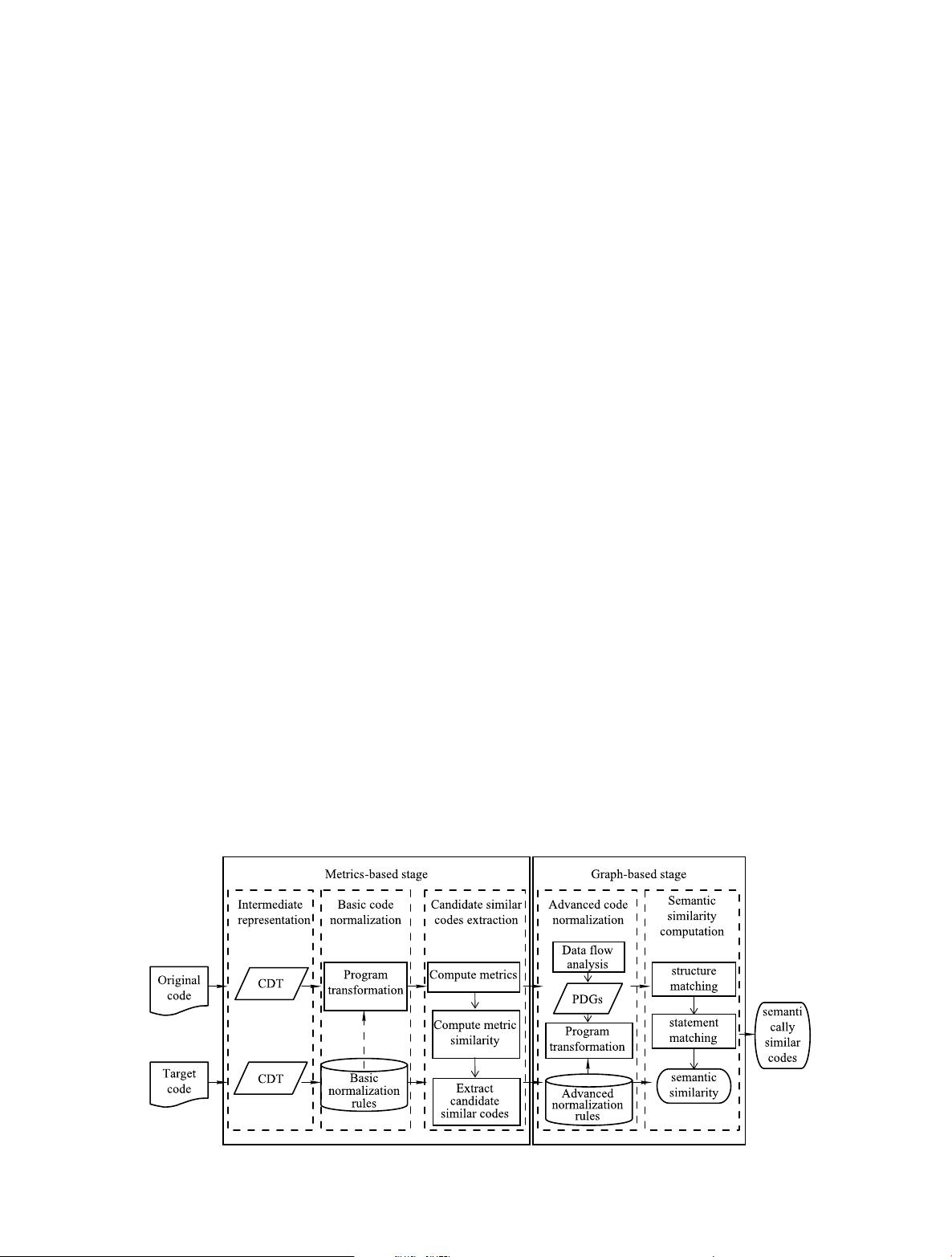
In order to solve the three problems proposed in Section 3 .1,
we develop a model of CMGA as shown in Fig. 1 based on
the facts proposed in Section 3.2.
To solve Problem 1, we improve the traditional SDG. The
structure theorem [41,42] puts forward that any proper pro-
gram, of any complexity, can be represented only by three
basic constructs: sequence, selection and iteration. Based on
this theorem, some control transfer statements such as goto
and break can be eliminated. Therefore, the CDS is repre-
sented as an ordered tree, which is called control dependence
tree (CDT) by us. The data flow analysis is only performed
on the candidate similar codes in the advanced code normal-
ization stage. As the candidate similar codes only account a
small part of the source code, the complexity of representing
SDG is g reatly decreased, so the augmented SDG is scalable
to large programs.
To solve Problem 2, we propose a metrics-based candi-
date similar codes extracting approach based on Fact 1 and
Fact 2 to filter out most of the dissimilar code pairs, so as to
prune the search space. The metrics-based approach has an
advantage that the computational complexity is much lower
than that of graph matching. In order to make CMGA effi-
cient enough for practical applications, we use the m etrics-
base approach for a fast selection of potential similar codes
at a pre-processing stage to prune the search space, when us-
ing the more accurate but more computationally expensive
method of graph matching.
Fig. 1 Model of metric-based and graph-based combined similar codes detection
剩余15页未读,继续阅读
2019-06-05 上传
2024-01-11 上传
2021-06-13 上传
点击了解资源详情
2023-05-16 上传
2024-09-27 上传
2024-04-25 上传
2021-06-06 上传

weixin_38699757
- 粉丝: 4
- 资源: 1026
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
