实时视频超分辨率:时空网络与运动补偿技术
需积分: 50 170 浏览量
更新于2024-09-08
收藏 6.95MB PDF 举报
"VESPCN - 实时视频超分辨率与时空网络和运动补偿"
在计算机视觉领域,视频超分辨率(Video Super-Resolution, VSR)是一个关键的研究方向,它旨在提高低分辨率视频的质量,使其接近或达到高分辨率的效果。VESPCN(即实时视频超分辨率与时空网络和运动补偿)是这一领域的经典之作,它引入了创新的网络结构和算法,不仅提升了视频重建的准确性,还能保持实时处理速度。
论文中,作者们探讨了如何利用神经网络,特别是卷积神经网络(Convolutional Neural Networks, CNNs),在视频超分辨率任务中有效利用时间序列中的关联性。以往的方法通常对这种时间相关性处理不足或者效率低下。而VESPCN则提出了一种时空子像素卷积网络(Spatio-Temporal Sub-Pixel Convolution Networks),这些网络能够巧妙地捕捉和利用相邻帧之间的时空冗余信息,从而提高图像恢复的精确度。
论文提到了三种技术:早期融合(Early Fusion)、慢融合(Slow Fusion)和3D卷积。早期融合是指在较早的网络层就将多帧信息结合,这样可以更早地利用时间信息,但可能会增加计算复杂度。慢融合则是指在较晚的层进行融合,可以减少计算量,但可能牺牲部分时间信息。3D卷积则是对传统2D卷积的扩展,可以同时处理空间和时间维度的数据,从而更好地捕捉动态场景的变化。
此外,VESPCN的一个重要创新是提出了一种新的联合运动补偿和视频超分辨率算法。传统的运动补偿方法往往效率较低,而VESPCN通过引入快速多分辨率空间变换模块,实现了端到端的可训练,极大地提高了效率。这种方法能够准确预测像素级别的运动,减少由于物体运动导致的图像失真,进一步提升超分辨率效果。
VESPCN通过创新的时空网络架构和高效的运动补偿策略,为视频超分辨率设定了新的标准,对于实时视频处理具有重要意义。它不仅在学术界产生了深远影响,也为实际应用如视频流媒体、监控系统和增强现实等领域提供了强大的技术支持。
Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion
Compensation
Jose Caballero, Christian Ledig, Andrew Aitken, Alejandro Acosta,
Johannes Totz, Zehan Wang, Wenzhe Shi
Twitter
{jcaballero, cledig, aaitken, aacostadiaz, johannes, zehanw, wshi}@twitter.com
Abstract
Convolutional neural networks have enabled accurate
image super-resolution in real-time. However, recent at-
tempts to benefit from temporal correlations in video super-
resolution have been limited to naive or inefficient archi-
tectures. In this paper, we introduce spatio-temporal sub-
pixel convolution networks that effectively exploit temporal
redundancies and improve reconstruction accuracy while
maintaining real-time speed. Specifically, we discuss the
use of early fusion, slow fusion and 3D convolutions for
the joint processing of multiple consecutive video frames.
We also propose a novel joint motion compensation and
video super-resolution algorithm that is orders of magni-
tude more efficient than competing methods, relying on a
fast multi-resolution spatial transformer module that is end-
to-end trainable. These contributions provide both higher
accuracy and temporally more consistent videos, which we
confirm qualitatively and quantitatively. Relative to single-
frame models, spatio-temporal networks can either reduce
the computational cost by 30% whilst maintaining the same
quality or provide a 0.2dB gain for a similar computational
cost. Results on publicly available datasets demonstrate
that the proposed algorithms surpass current state-of-the-
art performance in both accuracy and efficiency.
1. Introduction
Image and video super-resolution (SR) are long-standing
challenges of signal processing. SR aims at recovering a
high-resolution (HR) image or video from its low-resolution
(LR) version, and finds direct applications ranging from
medical imaging [38, 34] to satellite imaging [5], as well
as facilitating tasks such as face recognition [13]. The
reconstruction of HR data from a LR input is however a
highly ill-posed problem that requires additional constraints
to be solved. While those constraints are often application-
dependent, they usually rely on data redundancy.
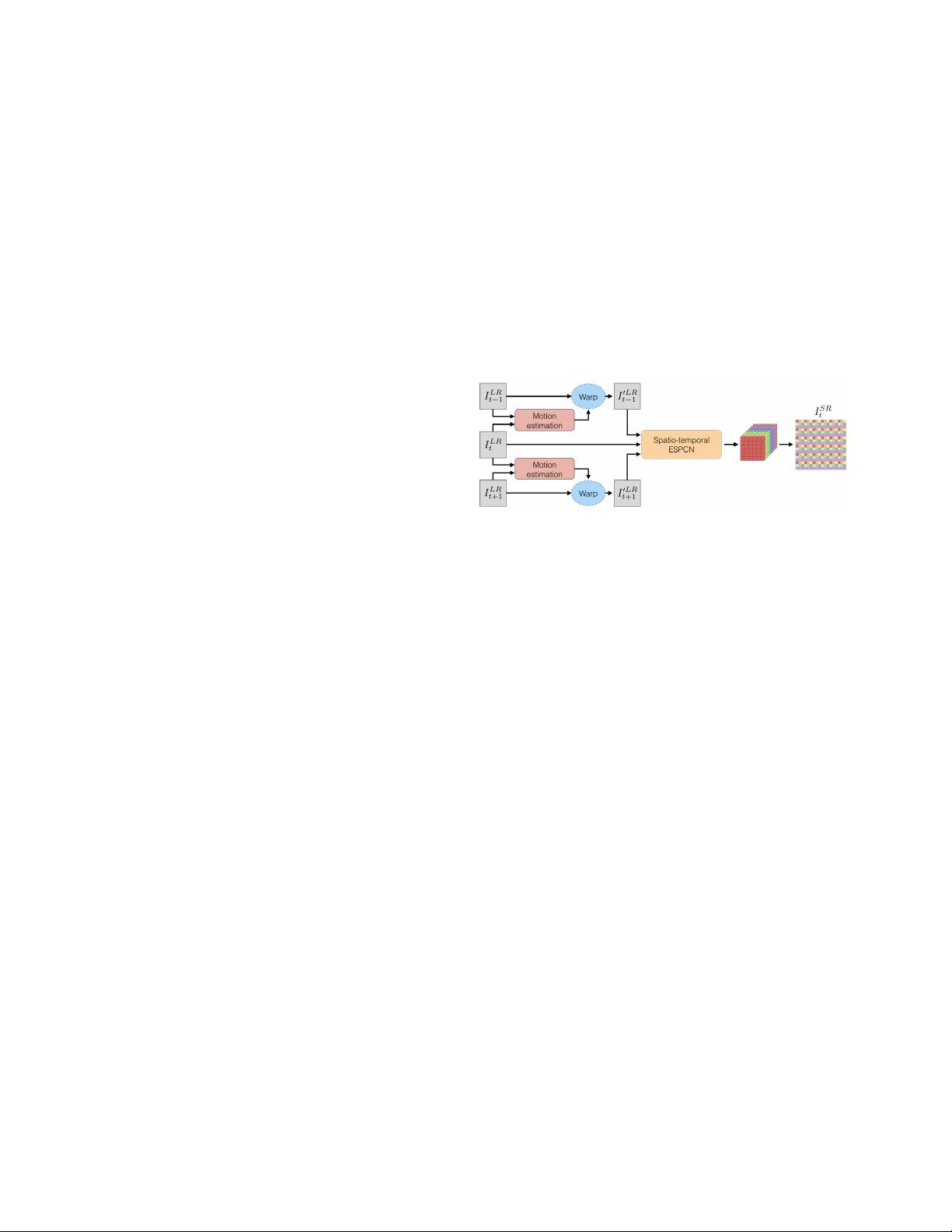
Figure 1: Proposed design for video SR. The motion esti-
mation and ESPCN modules are learnt end-to-end to obtain
a motion compensated and fast algorithm.
In single image SR, where only one LR image is pro-
vided, methods exploit inherent image redundancy in the
form of local correlations to recover lost high-frequency
details by imposing sparsity constraints [39] or assuming
other types of image statistics such as multi-scale patch re-
currence [12]. In multi-image SR [28] it is assumed that
different observations of the same scene are available, hence
the shared explicit redundancy can be used to constrain the
problem and attempt to invert the downscaling process di-
rectly. Transitioning from images to videos implies an ad-
ditional data dimension (time) with a high degree of corre-
lation that can also be exploited to improve performance in
terms of accuracy as well as efficiency.
1.1. Related work
Video SR methods have mainly emerged as adaptations
of image SR techniques. Kernel regression methods [35]
have been shown to be applicable to videos using 3D ker-
nels instead of 2D ones [36]. Dictionary learning ap-
proaches, which define LR images as a sparse linear com-
bination of dictionary atoms coupled to a HR dictionary,
have also been adapted from images [38] to videos [4]. An-
other approach is example-based patch recurrence, which
assumes patches in a single image or video obey multi-scale
relationships, and therefore missing high-frequency content
at a given scale can be inferred from coarser scale patches.
arXiv:1611.05250v2 [cs.CV] 10 Apr 2017
下载后可阅读完整内容,剩余9页未读,立即下载
2019-08-11 上传
2021-05-11 上传
2021-06-16 上传
2020-03-26 上传
2021-05-11 上传

fengfeng11246
- 粉丝: 3
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
