亚马逊产品数据与评论收集流程
需积分: 12 51 浏览量
更新于2024-09-05
收藏 1.31MB DOCX 举报
"该文档详细介绍了在亚马逊网站上进行数据收集的具体流程,主要涉及产品信息和用户评论数据的抓取,这些数据可以通过爬虫技术来获取。"
在数据收集过程中,首要任务是获取产品信息。以亚马逊上的三星Galaxy S9手机为例,以下是需要收集的关键数据点:
1. 产品名称:Samsung Galaxy S9 Unlocked Smartphone
2. 价格:产品的当前售价
3. 颜色:产品可选的颜色选项,如黑色、银色等
4. 尺寸:手机的尺寸规格
5. 样式:可能包括不同的设计或包装样式
6. 模式名称:特定的产品模式或配置,如标准版、特别版等
此外,还应关注以下统计信息:
1. 评论总数量:产品收到的评论总数
2. 产品平均评分:用户给出的平均评分
3. 商品排名:在同类商品中的销售排名
4. 评分分布:各评分(5-1星)所占的比例
5. 特定功能评分:如picturequality、screenquality、soundquality、fingerprintreader、batterylife和facerecognition的用户评分
接下来是获取产品的评论信息,这部分数据对于分析用户反馈至关重要:
1. 评论者姓名:留评用户的昵称
2. 是否有照片:评论者是否上传了个人照片
3. 评论者徽章:用户获得的荣誉或认证标志
4. 评论评分:用户给予产品的具体评分
5. 评论标题:用户总结的评论主题
6. 评论时间:评论发布日期
7. 颜色、尺寸、样式、模式:用户购买的具体型号
8. 是否“Verified Purchase”:确认购买的标记,表示评论者确实购买了该商品
9. 评论文本内容:用户的详细评价
10. 评论图片数量:用户上传的图片数量
11. 评论视频数量:如果有视频,记录其数量
12. 评论有用性投票:多少人认为该评论有帮助
13. 评论comments数量:用户对评论的回复数量,需注意页面加载更多的情况
通过爬虫技术,可以自动化地抓取这些数据,构建一个全面的产品和用户反馈数据库,以便进行市场分析、竞品对比或客户服务改进。在编写爬虫时,要注意遵循亚马逊的robots.txt规则,尊重网站的爬虫政策,并确保数据处理符合隐私法规。同时,要处理好反爬机制,例如IP限制、验证码挑战等,确保爬虫的稳定运行。
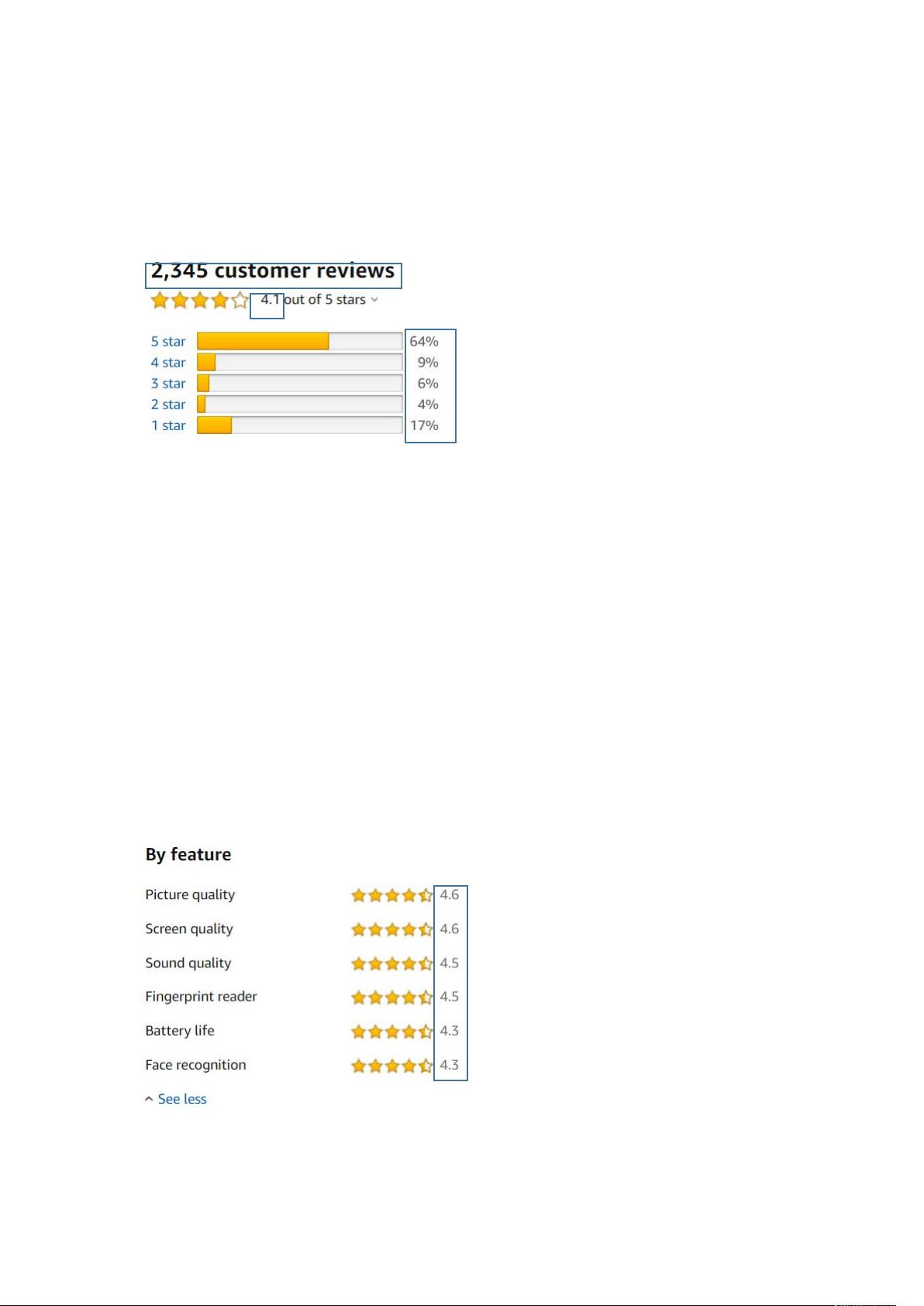
4)2 分占比
5)1 分占比
1)picture quality 评分
2)screen quality 评分
3)sound quality 评分
4)fingerprint reader 评分
5)battery life 评分
6)face recognition 评分
2、获取产品的评论信息
剩余12页未读,继续阅读
2023-08-16 上传
115 浏览量
2021-11-21 上传
2022-11-16 上传
2023-10-14 上传
2023-08-02 上传
2023-09-05 上传
2021-12-20 上传
365 浏览量

「已注销」
- 粉丝: 6
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







