理解交叉熵损失函数:从信息论到深度学习
交叉熵损失函数(Cross Entropy Loss)是人工智能领域中常见的损失函数,尤其在分类任务中被广泛使用。它源自信息论的概念,包括信息量和熵的理论基础。
交叉熵(CrossEntropy)是衡量两个概率分布之间差异的度量。在机器学习中,通常将实际的(或理想的)概率分布与模型预测的概率分布进行比较。它反映了模型预测的准确度,特别是在多分类问题中,用于评估模型预测类别概率的准确性。
1. 信息量(Information)是描述事件发生信息含量的量。一个事件的信息量与其发生的概率成反比,即非常可能发生的事情信息量低,而罕见事件的信息量高。信息量的计算公式为:\( I(x) = -\log_2(P(x)) \),其中 \( P(x) \) 是事件 \( x \) 发生的概率。
2. 熵(Entropy)是对随机变量所有可能取值信息量的平均,它衡量了随机变量不确定性。熵的计算公式为:\( H(X) = -\sum_{x \in \mathcal{X}} P(x) \log_2(P(x)) \),其中 \( H(X) \) 是熵,\( \mathcal{X} \) 是随机变量 \( X \) 的所有可能取值集合,\( P(x) \) 是对应的概率。熵越大,表示随机变量的不确定性越高。
例如,一个有8种等概率取值的随机变量,其熵为 \( \log_2(8) \)。如果这些取值的概率不均等,熵的计算会根据各概率值变化,反映出分布的均匀性。
3. 在分类任务中,交叉熵损失函数通常分为对数似然损失(Log-Likelihood Loss)和对数损失(Log Loss)。当模型需要预测多个类别的概率时,通常采用多类交叉熵损失函数。对于二分类问题,可以使用二元交叉熵损失(Binary Cross-Entropy),而对于多分类问题,则使用多类交叉熵损失(Multiclass Cross-Entropy)。
4. 二元交叉熵损失用于二分类问题,计算公式为:
\[
L = -\left[y \cdot \log(p) + (1-y) \cdot \log(1-p)\right]
\]
其中,\( y \) 是实际标签(0或1),\( p \) 是模型预测该样本属于正类的概率。
5. 多类交叉熵损失则扩展到多个类别的情况,每个类别都有相应的预测概率,计算公式为:
\[
L = -\sum_{c=1}^{C} y_c \cdot \log(p_c)
\]
其中,\( C \) 是类别总数,\( y_c \) 是实际标签向量,\( p_c \) 是模型预测第 \( c \) 类的概率。
6. 交叉熵损失函数在训练神经网络时,作为优化目标,通过反向传播算法更新网络参数,以最小化损失,从而提高模型预测的准确性。它能够有效地指导模型学习,尤其是在深度学习模型中,因为其对错误的敏感性使得模型能够快速调整权重。
交叉熵损失函数在人工智能,尤其是机器学习和深度学习中扮演着核心角色,它不仅提供了衡量模型预测性能的标准,还作为优化目标,驱动模型在训练过程中不断学习和改进。通过理解和正确应用交叉熵损失函数,可以有效地解决各种分类问题,提升模型的预测性能。
基础不牢,地动山摇基础不牢,地动山摇,读研到现在有一年多了,发现自己对很多经常打交道的知识并不了解,仅仅是会
改一改别人的代码,这使我感到非常焦虑,自此开始我的打基础之路。如果博客中有错误的地方,欢迎
大家评论指出,我们互相监督,一起学习进步。
交叉熵损失函数(Cross Entropy Loss)在分类任务中出镜率很高,在代码中也很容易实现,调用一条命
令就可以了,那交叉熵是什么东西呢?为什么它可以用来作为损失函数?本文将会循序渐进地解答这些
问题,希望能对大家有所帮助。
1. 交叉熵(交叉熵(Cross Entropy))
交叉熵是信息论中的概念,想要理解交叉熵,首先需要了解一些与之相关的信息论基础。
1.1 信息量(本节内容参考《深度学习花书》和《模式识别与机器学习》)信息量(本节内容参考《深度学习花书》和《模式识别与机器学习》)
信息量的基本想法是:一个不太可能发生的事件居然发生了,我们收到的信息要多于一个非常可能发生
的事件发生。
用一个例子来理解一下,假设我们收到了以下两条消息:
A:今天早上太阳升起
B:今天早上有日食
我们认为消息A的信息量是如此之少,甚至于没有必要发送,而消息B的信息量就很丰富。利用这个例
子,我们来细化一下信息量的基本想法:①非常可能发生的事件信息量要比较少,在极端情况下,确保
能够发生的事件应该没有信息量;②不太可能发生的事件要具有更高的信息量。事件包含的信息量应与
其发生的概率负相关。
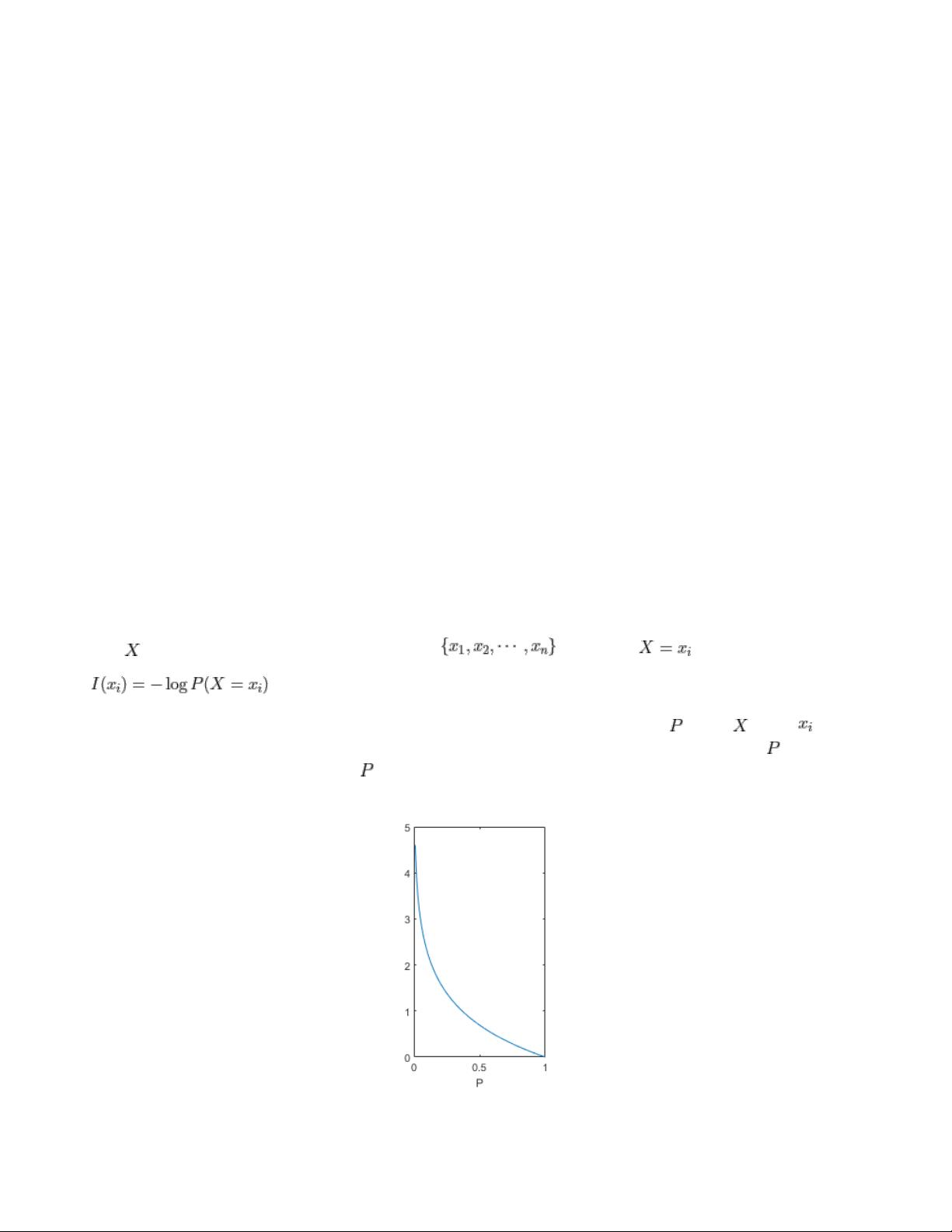
假设 是一个离散型随机变量,它的取值集合为 ,定义事件 的信息量为:
其中,log表示自然对数,底数为e(也有资料使用底数为2的对数)。公式中, 为变量 取值为 的概
率,这个概率值应该落在0到1之间,画出上面函数在P为0-1时的取值,图像如下。在概率值 趋向于0
时,信息量趋向于正无穷,在概率值 趋向于1时,信息量趋向于0,这个函数能够满足信息量的基本想
法,可以用来描述信息量。
1.2 熵(本节内容参考《模式识别与机器学习》)熵(本节内容参考《模式识别与机器学习》)
下载后可阅读完整内容,剩余4页未读,立即下载
1210 浏览量
2684 浏览量
151 浏览量
203 浏览量
176 浏览量
131 浏览量
2023-05-29 上传
201 浏览量
270 浏览量

快乐无限出发
- 粉丝: 1218
 我的内容管理
展开
我的内容管理
展开







最新资源
- Linux系统下ELK-7.2.1全套组件安装教程
- 32x32与16x16图标合集,Winform与Web开发精选必备
- Go语言开发的PBFT算法在Ubuntu上的应用
- Matlab实现离散数据两样本卡方检验
- 周期均值法中长期预报VB代码下载
- 微型计算机原理与应用课件精讲
- MATLAB求解线性矩阵不等式(LMI)方法解析
- QT实现Echarts数据可视化教程
- Next.js构建Markdown技术博客实现与细节
- Oracle 11.2.0.4关键补丁更新指南
- Dev_PP2: 探索JavaScript编程核心
- MATLAB中三次样条曲线的fsplinem开发
- 国产Linux SSH连接工具FinalShell安装使用教程
- 科大研究生算法课程PPT及作业汇总
- STM32F系列微控制器的电子设计与编码基础
- 知名外企开源Verilog视频处理控制代码
