Spark上的K-means与随机森林算法优化及应用框架
版权申诉
"本文主要研究了基于Spark的机器学习应用框架,针对K-means和随机森林算法的局限性进行了分析,并提出改进方案,设计出一套能够自动预处理数据、优化算法和选择参数的框架,降低了用户使用的复杂性。在交通物流云计算平台建设项目中,这一框架得到了验证,并具有自适应K-means(AKM)和自适应随机森林(ARF)两大特点,能够有效处理数据集中的问题,提升算法性能。"
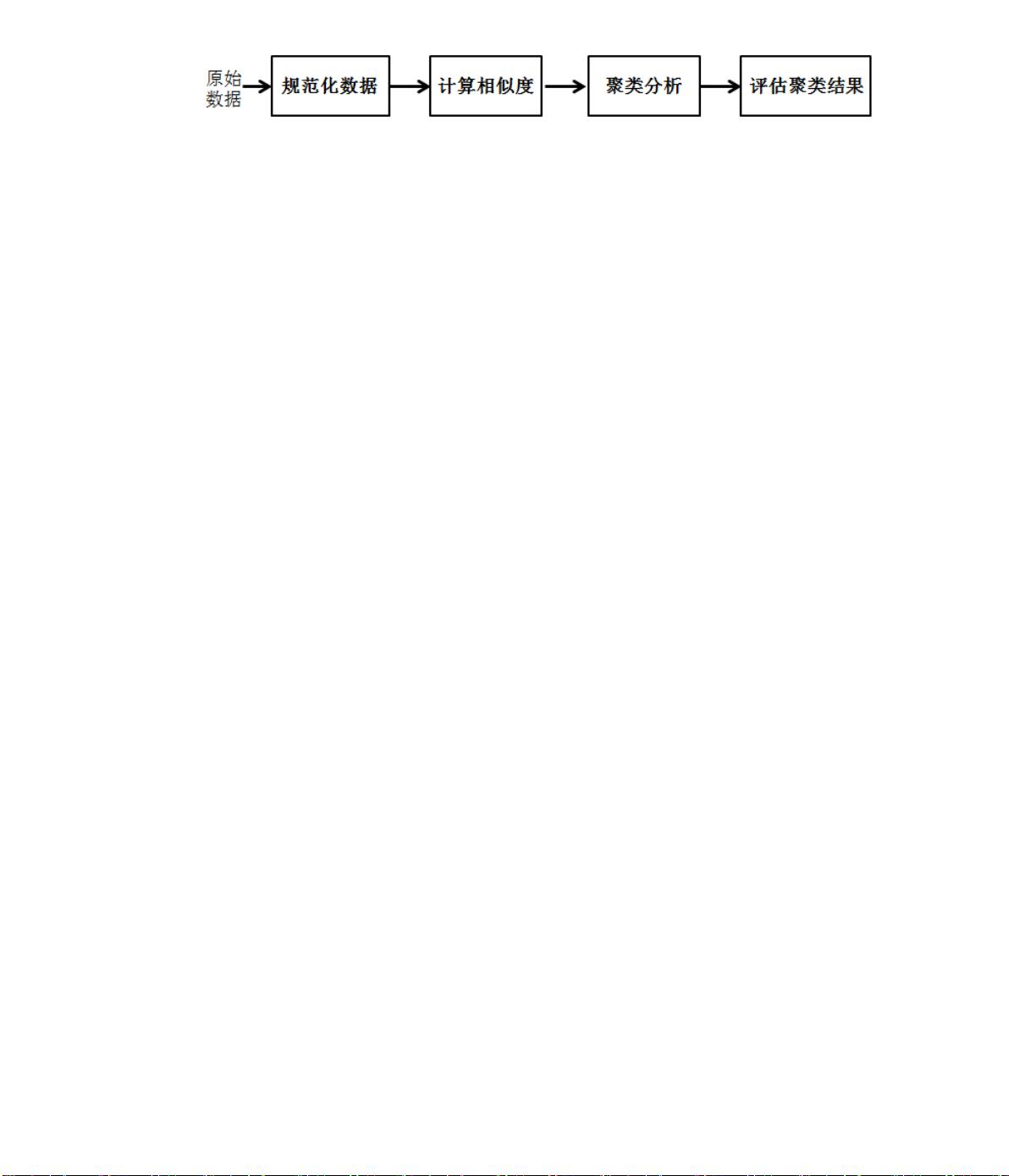
在机器学习领域,聚类分析和分类分析是非常关键的技术,其中K-means和随机森林是最常见的工具。然而,K-means算法要求用户预先设定群组数目K值,这对缺乏经验的用户来说是个挑战,可能导致K值设定不准确。而随机森林算法在分类决策时,所有决策树的权重相同,可能使准确性较差的决策树影响整体结果。
K-means算法在处理含有大量孤立点的数据集时,会增加迭代次数,提高复杂度,影响其准确性。同样,随机森林在面对包含噪声特征和冗余特征的数据集时,其分类准确性会下降。这些问题增加了用户使用这两种算法的难度。
为了克服这些挑战,分布式计算的机器学习框架如Spark得到了广泛应用。然而,现有的框架要求用户具备深厚的机器学习算法知识,这成为应用的一大障碍。针对这些问题,本文提出了一种基于Spark的机器学习应用框架,它包含了自适应的数据预处理、算法优化和参数选择功能,使得用户无需深入理解算法细节即可使用。
具体改进上,本文引入了AKM算法,解决了K-means的三个主要问题:特征权重不一致、孤立点干扰和K值设定。AKM算法能够自动规范化数据,检测并移除孤立点,还能自适应地确定最佳的K值,增强了聚类效果。
另一方面,ARF算法被用来改善随机森林的性能。ARF算法可以识别并删除噪声特征和冗余特征,同时改进了分类决策投票策略,提高了分类的准确性和鲁棒性。
通过交通物流领域的实际案例,这个框架的效能得到了验证,显示了在处理复杂数据集时的优越性能。相较于其他系统,本文提出的工作在自动化处理和算法适应性方面有显著优势,为机器学习在大数据环境下的应用提供了更便捷、高效的解决方案。

上海交通大学硕士学位论文 第一章 绪论
第 8 页
1.4 论文结构
本章首先介绍了机器学习和分布式计算框架的结合,提出了现有机器学习框架
使用门槛过高的问题,阐述了 K-means 算法和随机森林算法在实际使用中存在的限
制和缺点,分析了对于 K-means 算法和随机森林算法现有问题的国内外研究现状。
最后,提出了本文的研究目标和内容。
本文的后续章节概述如下:
第二章,相关技术分析。介绍了聚类分析技术、分类分析技术和 Spark 框架
的相关技术和研究。
第三章,AMLF 框架的需求分析与架构设计。详细介绍了 AMLF 框架的需
求、方案设计、设计目标和技术架构等。
第四章,关键技术的研究与实现。详细介绍了 AMLF 框架的关键技术的研
究与实现,包括 K-means 聚类算法的优化与实现、随机森林分类算法的优化
与实现和 AMLF 框架核心模块的设计与实现等。
第五章,实验验证。通过设计实验,对 AMLF 框架提出的改进算法进行验
证;通过面向交通物流的应用例子,对 AMLF 框架的可行性和有效性进行
验证。
第六章,总结与展望。总结了本文的主要内容,并对之后的工作进行展望。



剩余104页未读,继续阅读
2018-05-10 上传
2023-08-03 上传
2022-06-29 上传
2023-09-16 上传
2024-03-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-14 上传

「已注销」
- 粉丝: 841
- 资源: 3602
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
