HBase:从起源到逻辑视图详解
需积分: 10 8 浏览量
更新于2024-07-20
收藏 1.32MB PDF 举报
HBase详细讲解
HBase是Apache Hadoop项目下的一个分布式、面向列的NoSQL数据库,其设计灵感源于Google的Bigtable论文。起源于2006年,HBase在2010年正式成为Apache顶级项目,旨在提供类似Bigtable的数据存储能力,但专为非结构化数据设计,区别于传统的行式数据库。
HBase的特点主要体现在以下几个方面:
1. 大规模扩展性:HBase支持处理大规模数据,一张表可拥有上亿行和上百万列,非常适合大数据处理场景。
2. 面向列架构:HBase采用列族(Column Family)的概念,提供列级别的存储和权限管理,允许独立查询特定列族,这使得数据存储更为灵活且节省存储空间,特别是对于数据稀疏的情况。
3. 稀疏存储:HBase不为不存在的列分配存储空间,只有实际存在的数据才会占用空间,这使得表设计可以非常高效,尤其对于数据更新频繁、存在大量空值的情况。
在逻辑视图方面,HBase的存储结构主要包括:
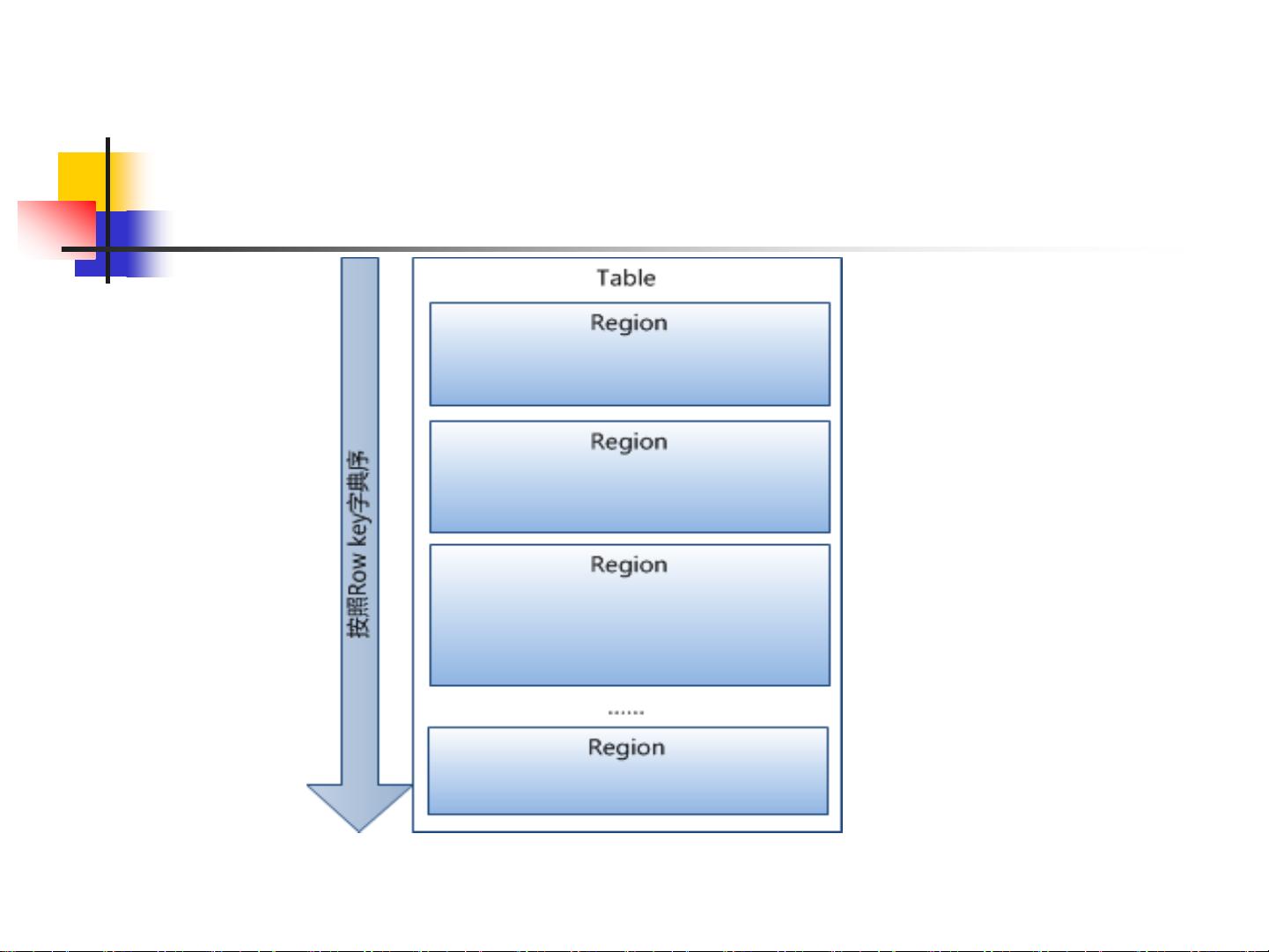
- 表:HBase以表格形式组织数据,由行和列族组成,列族是列的集合,定义在创建表时确定。
- Rowkey:作为记录的主键,Rowkey对数据的检索至关重要。HBase支持三种访问方式:单行、范围查询或全表扫描。Rowkey通常使用字符串表示,长度不超过64KB,设计时需考虑字典序排序以优化性能。
- ColumnFamily:列簇是表的元数据部分,每个列都属于特定的列簇,列名会包含列簇前缀。例如,在"courses"表中,"courses:history"和"courses:math"都属于"courses"列簇。
理解HBase的关键在于掌握其分布式架构、数据模型以及如何利用其特性进行高效的存储和查询,这对于在大数据环境下进行Hadoop高级开发非常关键。学习者在实际操作中,需要熟悉如何设计Rowkey、选择合适的列族结构,以及如何执行高效的读写操作,以充分利用HBase的性能优势。

117 浏览量
1874 浏览量
135 浏览量
2011-12-14 上传
2018-02-26 上传
143 浏览量
261 浏览量
2014-08-22 上传
190 浏览量

no_代码
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于VB开发的学生评语生成系统论文(源代码+论文).rar
- 基于单片机的简易门铃制作方案+资料-电路方案
- ember-attacher:Ember.js的本机工具提示和弹出窗口
- 西门子 28_SDT功率继电器产品说明书.zip
- ember-express:一个测试应用程序,可试用具有快速后端的ember.js
- 开发运维精华pdf下载地址.rar
- jquery-ui-rails:Rails资产管道的jQuery UI
- json_spec:在RSpec和Cucumber中轻松处理JSON
- layui-exce.zip
- eureka
- lead-generator-webapp:潜在客户生成器Webapp
- ember-stargate:Ember的现代轻型门户
- 富士通 ftr-f4系列功率继电器产品说明书.zip
- 基于HTML实现的非响应式外国银行亮黄企业站(含HTML源代码+使用说明).zip
- 100个矢量插画元素illlustrations .eps .svg .png素材下载
- 2021成长型企业IPO数字化白皮书.rar
