R语言判别分析与聚类分析实战:Fisher判别法解析
版权申诉
该资源是一个关于R语言中判别分析和聚类分析的演示文稿,包含实际案例和R代码,旨在帮助用户理解和应用这两种数据分析技术。内容涵盖了一般性的判别分析问题介绍,如疾病分类和天气预测,以及具体的统计方法,如距离判别法和Fisher判别分析。
在数据分析领域,判别分析是一种用于预测未知数据类别的统计方法。它基于历史数据,通过找出最佳判别准则,来确定新样本所属的类别。例如,医疗诊断系统可能利用判别分析根据病人的症状来预测疾病类型。同样,在气象学中,可以利用过去的气象记录预测未来的天气状况。
距离判别法是判别分析的一种形式,它利用样本之间的距离来决定它们的分类。马氏距离(Mahalanobis Distance)在这种方法中特别重要,因为它考虑了变量之间的相关性。对于两类总体,我们可以寻找使得两类样本间距离最大的方向;而对于多类总体,我们需要找到最能区分所有类别的方向。
Fisher判别分析是一种常用的技术,由Ronald Fisher提出,目的是通过降维来最大化类别间的方差并最小化类别内的方差。它构造线性判别函数,使各类别的投影尽可能分离,从而简化分类任务。线性判别函数的定义涉及协方差矩阵和类均值,通过求解最大类间方差与最小类内方差的比例来确定这个方向。在实际操作中,这一过程包括计算某些矩阵和向量,最后得到判别函数的表达式,用于新样本的分类。
Fisher判别分析的步骤通常包括以下几步:
1. 计算各类别的中心(均值)。
2. 构建协方差矩阵。
3. 解决特征值问题,找到最大特征值对应的特征向量。
4. 使用找到的特征向量构建线性判别函数。
5. 将新样本投影到这个低维空间中,并根据投影值判断其所属类别。
此外,聚类分析是另一种无监督学习方法,旨在发现数据集中的自然群体或类别,而无需先验类别信息。虽然在这个摘要中没有详细介绍聚类分析,但通常会用到的方法包括层次聚类和K-means聚类等。
这份资源提供了R语言中判别分析和聚类分析的基础知识和实践示例,对于想要掌握这两种分析技术的R语言用户非常有价值。
第五章 判别分析与聚类分析
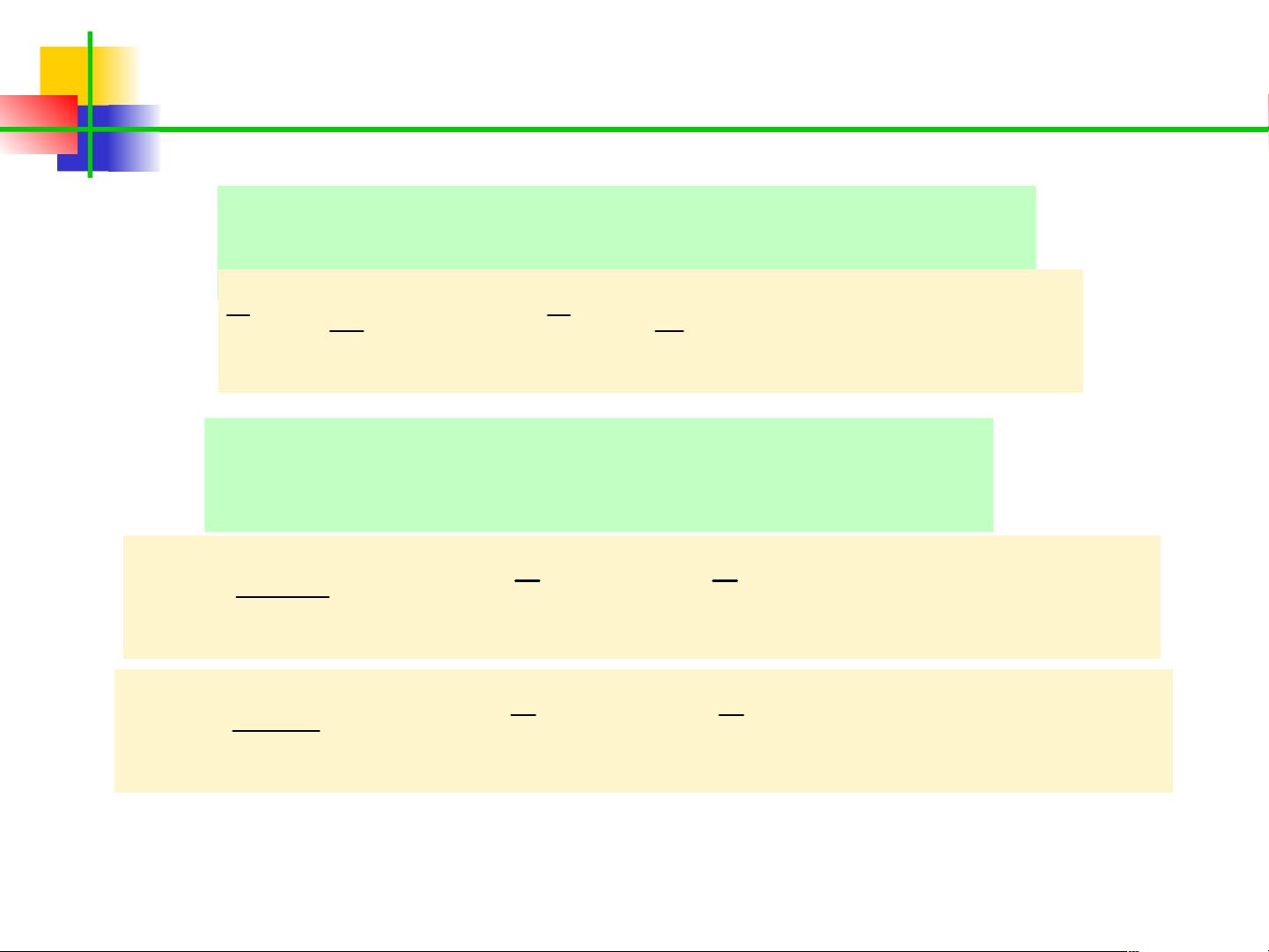
的总体均值根据样本均值估计得
到:
分别求出 的协方差矩阵
:
1 2
G G、
(1) (1) (2) (2)
1 1
1 1
1, 2, ,
p q
i ki i ki
k k
x x x x i n
p q
1 2
G G、
(1) (2)
S S、
(1) (1) (1) (1) (1)
1
1
( )( ) , 1, 2, ,
1
p
ij ki i kj j
k
s x x x x i j n
p
(2) (2) (2) (2) (2)
1
1
( )( ) , 1, 2, ,
1
q
ij ki i kj j
k
s x x x x i j n
q

剩余40页未读,继续阅读
相关推荐



博士僧小星
- 粉丝: 2517
 我的内容管理
展开
我的内容管理
展开








最新资源
- 掌握Cypress: 实现赛普拉斯REST API的自动化测试
- 使用grunt-module-dep实现JavaScript模块依赖注入
- SymNets: PyTorch官方实现深度学习项目
- Paintbrush:Mac OS X专用开源绘图工具
- NodeJS认证中间件实战:快速搭建与应用
- Paxion:Java实现的Büchi自动机图形编辑器
- Go Nested Set: GORM嵌套集模型的Go语言实现
- 用Pinboard-Sync管理Pinboard书签,提升效率与同步体验
- 腾讯云人脸识别demo:快速上手与人脸属性检测
- ceph_fly:简化ceph集群部署流程
- MMX-PromiseKit:Objective-C中Promise的强大封装
- 深入探讨延迟微分方程的数值分析研究
- Medroid客户端:与Medroid服务器交互的前端解决方案
- mia库:评估机器学习模型的成员资格推断攻击
- 深度强化学习解决多目标TSP问题的Matlab代码实现
- RepeatMasker输出的转座元件代码分析
