数据结构期末复习:如何构建概率哈夫曼树
需积分: 30 151 浏览量
更新于2024-08-02
收藏 241KB DOC 举报
"《数据结构(本)》期末复习指导,重点讲解如何根据概率构建哈夫曼树,适用于成人教育本科计算机科学与技术专业。"
哈夫曼树,也称为最优二叉树或最小带权路径长度树,是一种特殊的二叉树,常用于数据压缩和编码。在构建哈夫曼树时,我们通常根据各字符出现的概率来构造树的结构,以达到最小化数据传输或存储的总成本。
构建哈夫曼树的过程通常包括以下几个步骤:
1. **创建初始节点**:为每个字符创建一个哈夫曼节点,该节点包含字符及其出现的概率。这些节点称为叶子节点。
2. **合并最小节点**:选取概率最小的两个节点,合并成一个新的节点,新节点的权值是两个子节点权值之和,即它们的概率之和。这个新节点成为内部节点,并没有对应的字符。
3. **重复合并**:将新节点放入节点集合中,再次选取概率最小的两个节点进行合并。重复此过程,直到只剩下一个节点,这个节点就是哈夫曼树的根节点。
4. **构建编码**:从根节点到每个叶子节点的路径可以形成一个独特的编码,左分支代表0,右分支代表1。每个字符的编码就是从根到对应叶子节点路径上的0和1序列。
哈夫曼编码的优势在于,频繁出现的字符会有较短的编码,而较少出现的字符则有较长的编码,这样可以平均减少编码的平均长度,从而提高数据传输或存储的效率。
在复习《数据结构(本)》时,考生应重点理解逻辑结构和物理结构的概念,以及它们之间的关系。逻辑结构关注数据元素间的抽象关系,如集合、线性结构、树形结构和图。物理结构则是数据在计算机内存或磁盘上的实际存储方式,它受到硬件限制并影响数据的访问效率。
在课程的考核中,可能会遇到如下类型的题目:
- 单项选择题:测试对基本概念的理解,如哈夫曼树的定义、特性等。
- 填空题:可能要求填写哈夫曼树的构建步骤或者特定数据结构的特征。
- 程序填空题:可能需要完成一段关于哈夫曼树构建或编码的代码。
- 综合题:可能需要设计算法,根据给定的字符频率表构建哈夫曼树,并给出相应的编码。
考生应充分利用教材、作业和复习资料,尤其是综合练习题,因为历年试题可能来源于其中。对于考试大纲要求的前四章,特别是关于数据结构的基本概念和哈夫曼树的部分,需要深入理解和实践,以应对可能的考核要求。
""" 串变量和其它类型的变量一样,其取值是可以改变的。
()串常量
"""串常量和整常数、实常数一样,在程序中只能被引用但不能改变其值。即只能读不能写。
①串常量由直接量来表示的:
"""【例】/(9ABC9)中9ABC9是直接量。
②串常量命名
"""有的语言允许对串常量命名,以使程序易读、易写。
"""【例】 中,可定义串常量 %
""""""""%)09&1D1%%9E
第 5 章 数组和广义表
1.数组(向量)——常用数据类型
"""一维数组(向量)是存储于计算机的连续存储空间中的多个具有统一类型的数据元素。同一数组的不
同元素通过不同的下标标识。
""""""(
3
343
2.二维数组
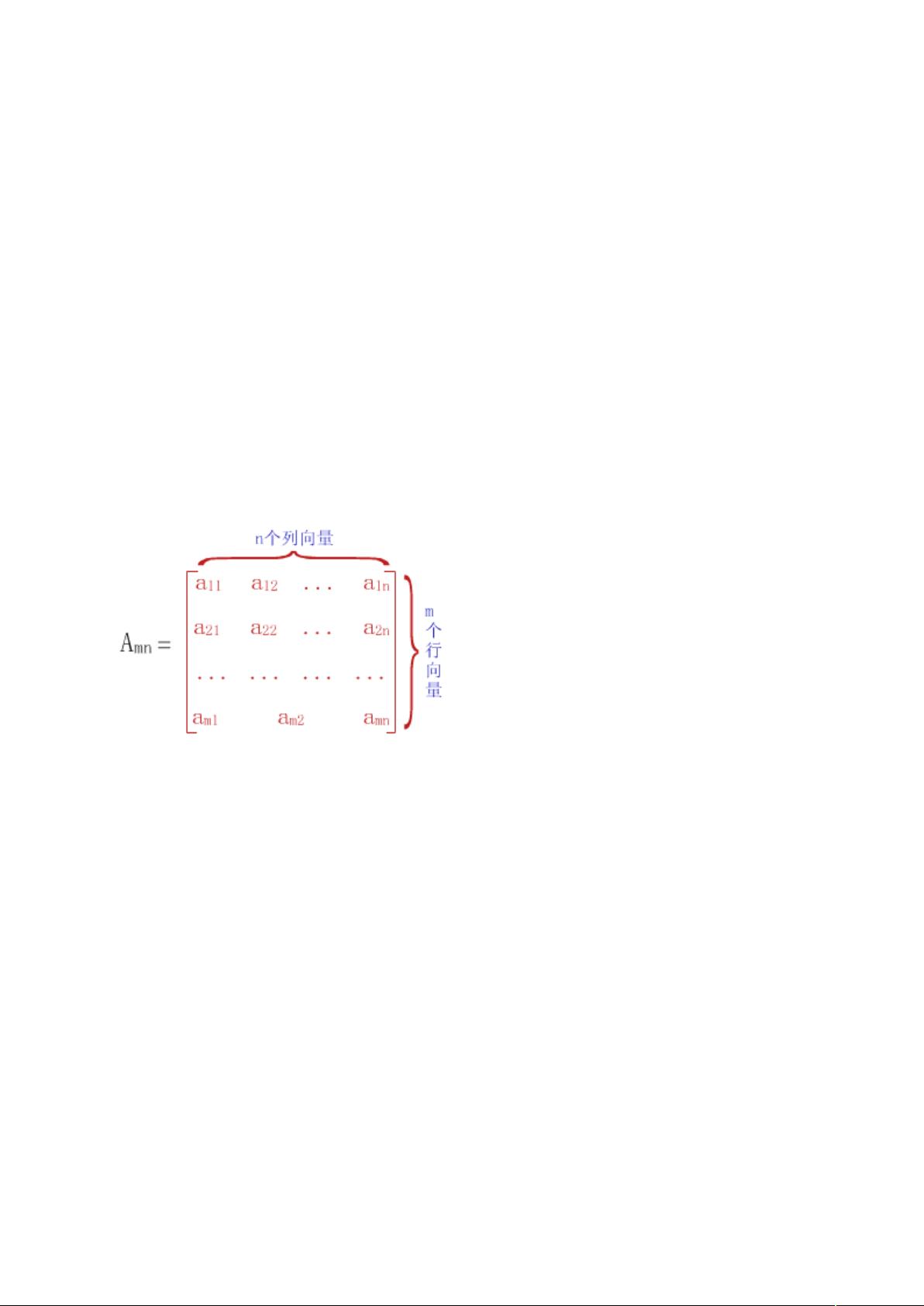
"""二维数组 +
可视为由 个行向量组成的向量,或由 个列向量组成的向量。
"""二维数组中的每个元素
F
既属于第 行的行向量,又属于第 F 列的列向量。
3.多维数组
"""三维数组 +
%
可视为以二维数组为数据元素的向量。四维数组可视为以三维数组为数据元素的向量…
… 三维数组中的每个元素
F?
都属于三个向量。四维数组中的每个元素都属于四个向量……
4.数组的顺序存储方式
"""由于计算机内存是一维的,多维数组的元素应排成线性序列后存人存储器。
数组一般不做插入和删除操作,即结构中元素个数和元素间关系不变化。一般采用顺序存储方法表示数
组。
()行优先顺序
"""将数组元素按行向量排列,第 个行向量紧接在第 个行向量后面
5、广义表
广义表(Lists,又称列表)是线性表的推广。即广义表中放松对表元素的原子限制,容许它们具有其自
身结构。
第 5 页 共 25 页
剩余24页未读,继续阅读
2013-12-17 上传
2023-12-29 上传
2009-12-30 上传
2023-06-11 上传
2023-06-07 上传

mujiang770419151
- 粉丝: 12
- 资源: 84
 我的内容管理
展开
我的内容管理
展开







最新资源
- transformers:收集资源以深入研究《变形金刚》
- Shopify spy - shopify store parser & scraper-crx插件
- node-friendly-response:进行JSON响应的简单方法
- 致敬页面
- brazilian-flags:显示 ListActivity 和 TypedArrays 的简单 Android 代码。 旧代码迁移至顶级 Android Studio
- chat-test
- 使用Temboo通过Amazon实现简单,健壮的M2M消息传递-项目开发
- 格塔回购
- pg-error-enum:没有运行时相关性的Postgres错误的TypeScript枚举。 还与纯JavaScript兼容
- textbelt:用于发送文本消息的Node.js模块
- SaltStack自动化运维基础教程
- FreeCodeCamp
- BurnSoft.Applications.MGC:My Gun Collection应用程序的主库,其中包含与数据库交互的大多数功能
- CoreFramework:实施全球照明技术的通用核心框架
- 数据库mysql基本操作合集.zip
- auto-decoding-plugin:以OWASP ModSecurity Core Rule Set插件的形式自动解码有效载荷参数
