Kafka架构详解:工作流程与文件存储机制
100 浏览量
更新于2024-08-29
收藏 743KB PDF 举报
本章节深入探讨了Kafka架构的各个方面,首先聚焦于Kafka的工作流程和文件存储机制。Kafka的核心是基于topic的消息传递系统,其中topic是逻辑上的分类,用于组织生产者产生的数据流。每个topic被划分为多个物理分区(partition),每个分区对应一个log文件,存储生产者(producer)生成的数据,这些数据按照顺序追加,并且每个消息都有唯一的offset,用于跟踪消息的位置。
为了保持高效的数据处理和故障恢复,Kafka采用了分片(segment)和索引机制。每个partition被划分为多个segment,每个segment包含一个.index文件和一个.log文件。这些文件存储在特定的文件夹中,文件夹名遵循topic名加上分区序号的形式。索引文件记录元数据,指向.log文件中消息的物理偏移位置,这样即使数据量大,也能快速定位到所需消息。
在生产者方面,分区策略是关键。分区的主要原因有两个:一是为了支持集群扩展,通过调整单个partition,适应不同规模的硬件;二是提高并发性能,通过以分区为单位进行读写操作。生产者在发送数据时,可以选择指定分区,或者根据某种策略自动决定分区,如基于哈希、round-robin等。
3.2.1 部分章节内容还可能介绍了生产者的配置选项,比如acks(确认模式)、retries(重试次数)、batch size(批量发送大小)等,这些配置会影响消息的可靠性与性能。同时,生产者还需要处理消息的序列化和压缩,确保数据在传输过程中的一致性。
此外,章节还会讨论消费者如何订阅topic、处理offset管理,以及Kafka的高可用性和容错机制,如leader选举、故障转移和数据备份。通过理解这些细节,学习者能够全面掌握Kafka如何在分布式环境中实现高效、可靠的消息传递。
第3章"Kafka架构深入"不仅涵盖了Kafka的基本工作原理,还包括了生产和消费端的配置、分区策略以及关键的内部机制,是快速学习Kafka并深入理解其设计思想和技术细节的重要章节。
快速学习快速学习-Kafka架构深入架构深入
第第 3 章章 Kafka 架构深入架构深入
3.1 Kafka 工作流程及文件存储机制工作流程及文件存储机制
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该log
文件末端,且每条数据都有自己的 offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment
对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic 名称+分区序号。例如,first 这个 topic 有三个分区,则其对应的文件夹为
first-0,first-1,first-2。
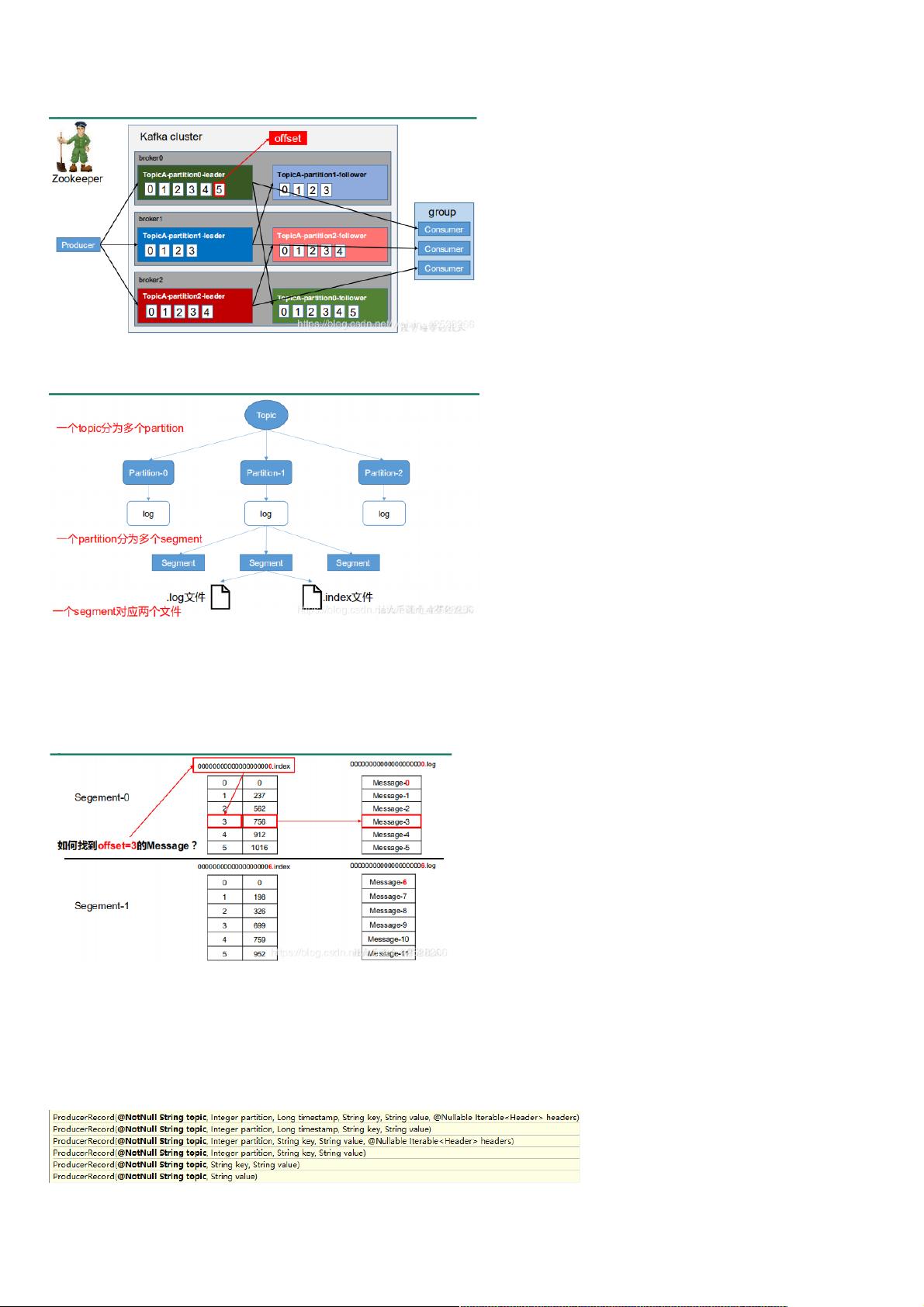
00000000000000000000.index
00000000000000000000.log
00000000000000170410.index
00000000000000170410.log
00000000000000239430.index
00000000000000239430.log
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。下图为 index 文件和 log文件的结构示意图。
“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
3.2 Kafka 生产者生产者
3.2.1 分区策略分区策略
1)分区的原因
(1)方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 topic
又可以有多个 Partition 组成,因此整个集群就可以适应任意大小的数据了;
(2)可以提高并发,因为可以以 Partition 为单位读写了。
2)分区的原则
我们需要将 producer 发送的数据封装成一个 ProducerRecord 对象。
(1)指明 partition 的情况下,直接将指明的值直接作为 partiton 值;
(2)没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值;
(3)既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,
也就是常说的 round-robin 算法。
3.2.2 数据可靠性保证数据可靠性保证
下载后可阅读完整内容,剩余4页未读,立即下载
2024-04-18 上传
2024-03-09 上传
2021-02-09 上传
2021-04-03 上传
2021-05-18 上传
2021-06-27 上传
2021-05-30 上传
点击了解资源详情
点击了解资源详情

weixin_38674675
- 粉丝: 3
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
