STATA面板数据模型:估计与检验命令详解
版权申诉
"STATA面板数据模型操作命令文档主要涵盖了STATA软件中处理面板数据模型的常用命令,包括固定效应模型和随机效应模型的构建、检验与比较。文档旨在帮助用户理解和应用这些命令来分析经济或社会科学中的面板数据。"
在STATA中,面板数据模型的处理对于理解长期关系和控制不可观测的个体特征至关重要。以下是详细的操作步骤和知识点:
1. 定义面板数据结构
使用`tsset code year`命令将数据设置为面板数据格式,其中`code`是识别个体的变量,`year`是时间变量。
2. 数据探索
`xtdes`用于查看面板数据的结构和基本信息,而`summarize`命令用于计算各变量的描述性统计,如均值、标准差、最小值、最大值等。
3. 变量构造
- `gen lag_y = L.y` 创建一个滞后一期的变量。
- `gen F_y = F.y` 生成一个超前项变量。
- `gen D_y = D.y` 和 `gen D2_y = D2.y` 分别创建一阶差分和二阶差分的变量,常用于消除趋势或季节性。
4. 模型筛选与检验
- 个体效应检验:使用`xtreg y x1 x2 ..., fe`估计固定效应模型,然后查看F统计量判断固定效应是否显著。
- 时间效应检验:通过`quixtreg y x1 x2 ..., re`估计随机效应模型,并使用`xttest0`执行LM检验,若P值小于显著性水平,说明时间效应显著。
- Hausman检验:当固定效应模型和随机效应模型都可能适用时,进行Hausman检验来决定选用哪种模型。首先分别存储固定效应和随机效应模型的估计结果,然后运行`hausman fe re`来执行检验,根据P值选择更合适的模型。
5. 模型比较
在固定效应模型和随机效应模型之间,Hausman检验的结果能帮助确定哪个模型的参数估计更有效。如果P值很小,通常选择固定效应模型;反之,则选择随机效应模型。
6. 其他考虑
在实际操作中,还应注意选择适当的工具变量(IVs)以解决内生性问题,以及使用`xtivreg`或`xtivreg2`命令处理工具变量回归。此外,可能需要对异方差性、自相关等问题进行调整,如使用`robust`或`cluster`选项。
STATA面板数据模型的操作涉及多个命令和检验,通过这些步骤,研究人员能够有效地分析面板数据,提取出有价值的信息,并做出科学的决策。在学习和应用这些命令时,理解其背后的统计理论是至关重要的。
3 / 14
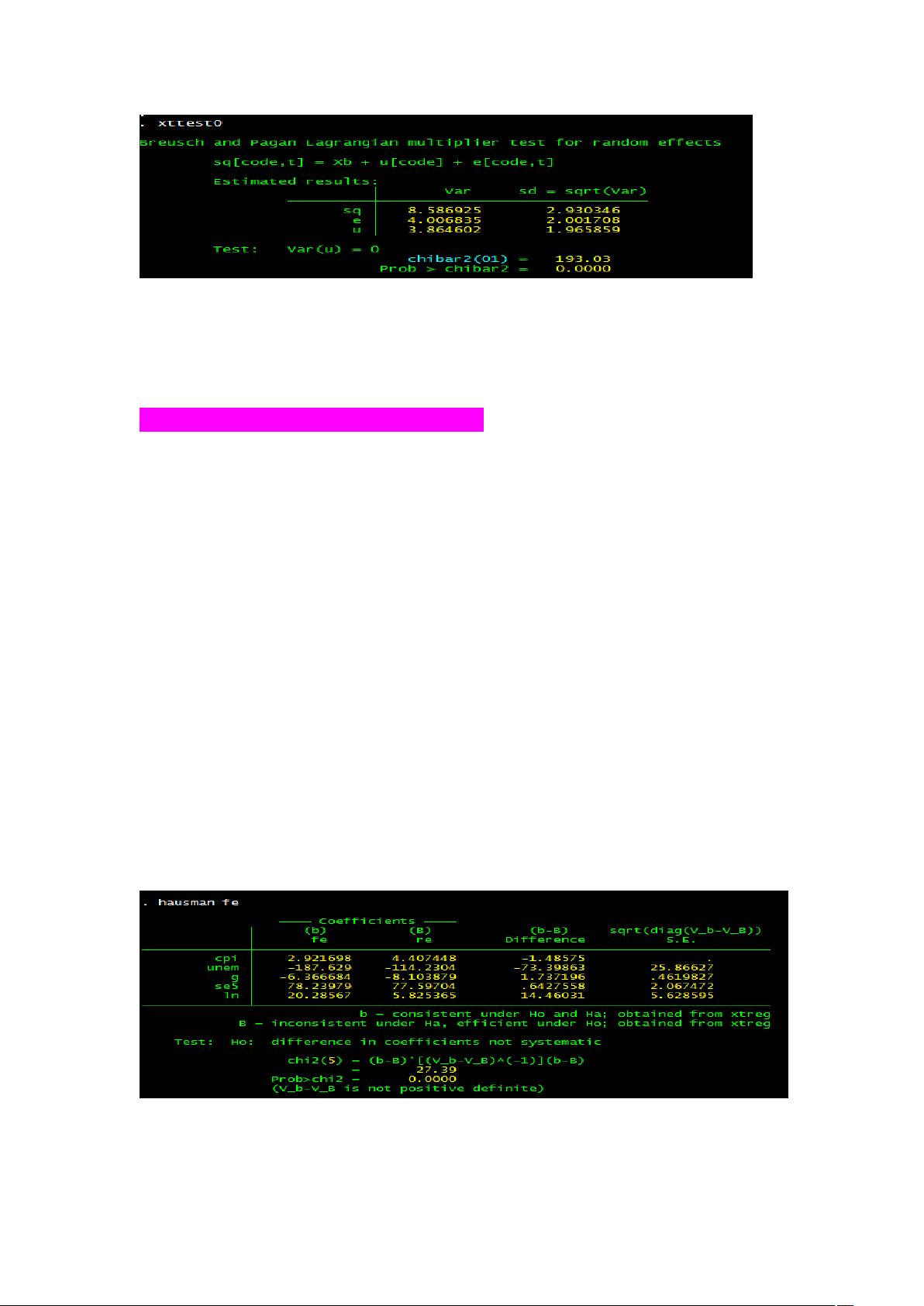
可以看出,LM 检验得到的 P 值为 0.0000,表明随机效应非常显著。可见,
随机效应模型也优于混合 OLS 模型。
●3、检验固定效应模型 or 随机效应模型 (检验方法:Hausman 检验)
原假设:使用随机效应模型(个体效应及解释变量无关)
通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项
为常数假设条件下的混合 OLS 模型。但是无法明确区分 FE or RE 的优劣,这需要
进行接下来的检验,如下:
Step1:估计固定效应模型,存储估计结果
Step2:估计随机效应模型,存储估计结果
Step3:进行 Hausman 检验
●qui xtreg sq cpi unem g se5 ln,fe
est store fe
qui xtreg sq cpi unem g se5 ln,re
est store re
hausman fe (或者更优的是 hausman fe,sigmamore/ sigmaless)
可以看出,hausman 检验的 P 值为 0.0000,拒绝了原假设,认为随机效应模
型的基本假设得不到满足。此时,需要采用工具变量法和是使用固定效应模型。
剩余13页未读,继续阅读
2022-12-18 上传
2021-11-18 上传
2022-05-10 上传
2022-05-10 上传
2022-12-24 上传
2008-10-29 上传
2024-10-31 上传
2024-10-31 上传
2008-10-29 上传

celkhn5460
- 粉丝: 0
- 资源: 4万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- markTwo:此存储库包含我的第一个CLI应用程序,该应用程序是我作为第一周的作业而制作的
- L380L383L385L485清零软件原版
- 安卓Android源码——安卓Android重力感应跑步测速.zip
- AccessControl-4.0b7-cp37-cp37m-win_amd64.whl.zip
- todos_app:todos_app对于初学者使用HTML,CSS和JavaScript
- DynamicMethodDispatchDemo,java游戏源码,企业java
- 【黑苹果EFI】联想昭阳E40-80的自制EFI,Opencore 0.8.8
- Spring-Excel-to-Object-Binding-Validation:Spring Excel 上传文件到对象绑定
- authority (1)-源码.rar
- ArdWeighno:将称重传感器秤连接到Arduino的简单方法。-开源
- 基于ssm+vue毕业生学历证明系统.zip
- binary-search-tree-exercises
- honotify:Honotify是一个简单的应用程序,当有人扫描您的端口时,通过侦听用户指定的端口,它会使用libnotify向您显示通知
- reports,java源码怎么看,javavector
- STM32F429 FreeRTOS实战:实现FreeRTOS任务通知模拟消息邮箱【支持STM32F42X系列单片机】.zip
- L360打印机废墨清零、故障恢复软件
