SPSS多元线性回归分析:汽车特征与销量关系探索
版权申诉
61 浏览量
更新于2024-08-20
收藏 677KB DOCX 举报
"该文档是关于多元线性回归的实例分析,主要讲解了如何使用SPSS软件进行操作,以分析汽车特征与汽车销售量之间的关系。文档内容包括多元线性回归的基本概念、方程矩阵形式以及随机误差的四个基本假设,并通过实际数据展示了在SPSS中设置回归分析的过程。"
在统计学中,多元线性回归是一种广泛应用的分析方法,用于研究一个或多个自变量(预测变量)与一个因变量(响应变量)之间的线性关系。与一元线性回归不同,多元线性回归考虑了多个可能影响因变量的因素,这使得模型能够更全面地捕捉变量间的复杂关联。
多元线性回归模型可以表示为:
\[ Y = \beta_0 + \beta_1X_1 + \beta_2X_2 + \ldots + \beta_pX_p + \epsilon \]
其中,\( Y \) 是因变量,\( X_1, X_2, \ldots, X_p \) 是自变量,\( \beta_0 \) 是截距项,\( \beta_1, \beta_2, \ldots, \beta_p \) 是自变量的系数,而 \( \epsilon \) 是随机误差项。当有 \( N \) 组样本时,这些变量构成一个矩阵,模型以矩阵形式表示:
\[ \mathbf{Y} = \mathbf{X\Beta} + \mathbf{\epsilon} \]
其中,\( \mathbf{Y} \) 是因变量的向量,\( \mathbf{X} \) 是自变量的矩阵(包含1作为列的截距),\( \mathbf{\Beta} \) 是系数向量,\( \mathbf{\epsilon} \) 是误差项的向量。
随机误差 \( \epsilon \) 需要满足以下四个关键假设,以保证多元线性回归的合理性:
1. 正态性:误差项服从正态分布。
2. 无偏性:误差项的期望值为0。
3. 同方差性:所有误差项的方差相等。
4. 独立性:误差项之间相互独立。
在SPSS软件中,执行多元线性回归分析通常包括以下步骤:
1. 打开数据文件,将因变量和自变量分别标记。
2. 进入“分析”菜单,选择“回归” -> “线性”。
3. 在弹出的对话框中,将因变量拖入“因变量”框,将自变量拖入“自变量”框。
4. 可以选择不同的方法,如“逐步”或“进入”,来决定自变量进入模型的方式。
5. 设置统计选项,比如选择“回归系数”、“模型拟合度”和“共线性诊断”,以便检查模型的性能和潜在问题。
6. 检查输出结果,分析自变量对因变量的影响程度,以及模型的解释力。
例如,如果选择“逐步”方法,SPSS会基于预设的显著性水平筛选自变量,保留与因变量关系最密切的变量。同时,可以设置额外的筛选规则,对特定自变量进行条件筛选。
通过这些步骤,我们可以得出汽车特征(如车长、车宽、耗油率、车净重等)如何影响汽车销售量的结论,从而建立一个有效的多元线性回归模型,用于预测或解释销售趋势。共线性诊断则有助于识别自变量之间是否存在高度相关性,这可能会影响模型的稳定性。
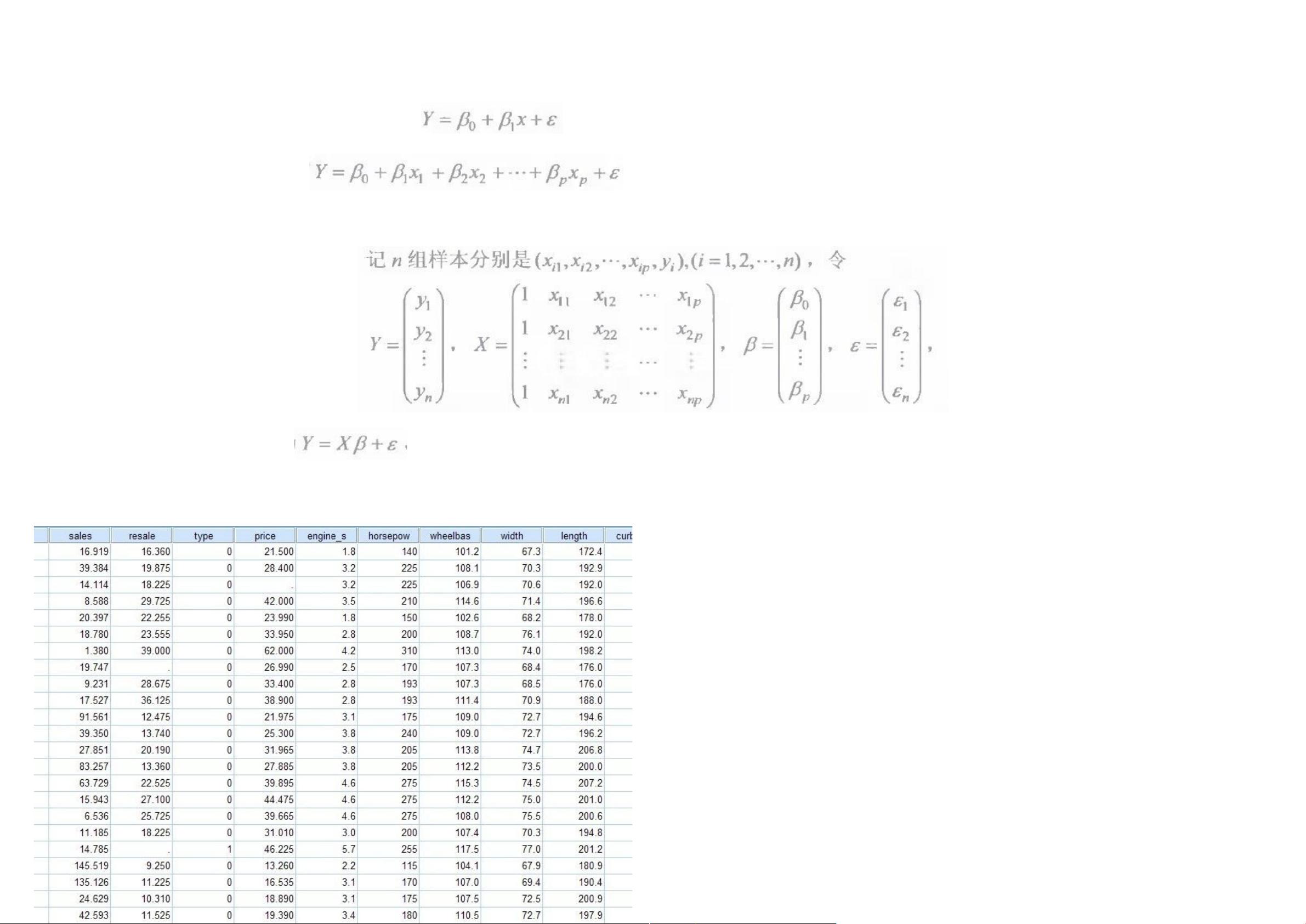
多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于
影响因素(自变量)更多些而已,例如:一元线性回归方程为:
毫无疑问,多元线性回归方程应该为:
上图中的 x1, x2, xp 分别代表“自变量”Xp 截止,代表有 P 个自变量,如果有“N 组样本,那么这个多元线
性回归,将会组成一个矩阵,如下图所示:
那么,多元线性回归方程矩阵形式为:
其中: 代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下
四个条件,多元线性方程才有意义(一元线性方程也一样)
1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。
2:无偏性假设,即指:期望值为 0
3:同共方差性假设,即指,所有的 随机误差变量方差都相等
4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车
特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据
如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-22 上传
2022-06-23 上传
2022-06-23 上传
2022-06-23 上传
2022-06-24 上传
2023-05-25 上传

lulusuhua
- 粉丝: 0
- 资源: 11万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于ASP.NET技术的企业办公自动化系统的设计
- java方面的好的学习资料
- 电机故障特征值的倍频小波分析
- TMS320LF2407A矢量控制变频器的开发经验.
- TI的实时操作系统DSP BIOS介绍.pdf
- C++primer笔记
- Paper writeing
- 数据库代码---删除、查看、插入、修改数据库和表的代码
- 面向对象软件构造.pdf
- 51单片机教程 51单片机教程
- MCS-51单片机与GPS—OEM板串行通信系统设计
- 基于ASP1NET+ Castle 框架的旅游管理系统的设计
- NI电路设计套件快速入门
- Bezier C语言描述
- Jmeter性能测试中文手册
- C++设计模式精解C++设计模式精解
