实时数仓实战:Amazon Redshift与Flink在大数据存储中的架构构建
版权申诉
135 浏览量
更新于2024-07-03
收藏 4.22MB PDF 举报
本篇文档深入探讨了大数据存储及分层实践中的关键环节——实时数仓的场景剖析与架构搭建。首先,提到了亚马逊的Serverless技术在实时数据处理中的应用,如Amazon MSK(托管的Kafka服务),它简化了数据实时传输过程,同时指出RDS(关系型数据库服务)通过Change Data Capture (CDC)工具将数据变更日志实时推送到Kafka,如Flink CDC,以实现高效数据流转。
在实时处理层,Flink被用来消费Kafka的数据,并将其写入存储层,如Hudi或Iceberg。这两种选择都倾向于利用S3(对象存储)进行存算分离,以支持多层OLAP查询。此外,文档还提到了Amazon EMR,作为Hadoop生态系统的服务,为实时湖仓提供弹性的计算能力,确保数据处理的灵活性和扩展性。
数仓架构方面,文章关注了实时计算的轻量化选项,比如Amazon Analytics Serverless,这是一种无服务器服务,旨在降低实时分析的资源开销。同时,文中提及了数据湖(Datalake)的重要性,以及通过JDBC/ODBC接口、Data API进行数据访问的灵活性。对于传统的查询服务,如Redshift,它是Amazon云原生的高性能数仓,适合大规模数据分析。
在计算资源管理上,文档强调了集群架构的动态扩展,包括Leader Node和Compute Nodes,特别是Amazon Nitro Compute提供高性能计算能力。此外,还涉及了Amazon SageMaker用于机器学习任务,以及Redshift的Managed Storage和AQUA等高级功能,这些都能提升数据处理的性能和效率。
为了支持数据共享和自动伸缩,文档介绍了Data sharing clusters和Auto-scaling clusters的概念,以及Amazon S3的全球缓存(Global Cache)功能。此外,还提到了诸如Incremental Materialized Views(增量视图)和QueryLiveData这样的高级查询优化技术,以及Compilation Service等工具,以提高查询性能。
最后,文章简要触及了Parallelexecution节点和Amazon设计的处理器节点,如Spectrum Node,这些技术用于处理复杂的并行计算任务,以及Amazon-designed processor Node,进一步增强了实时数仓的处理能力。
本文提供了实时数仓构建的关键要素,从数据流到存储选择,再到计算资源管理和优化策略,涵盖了从数据收集、实时处理到高级分析的全过程,为构建高效、灵活的大数据处理架构提供了全面的指导。
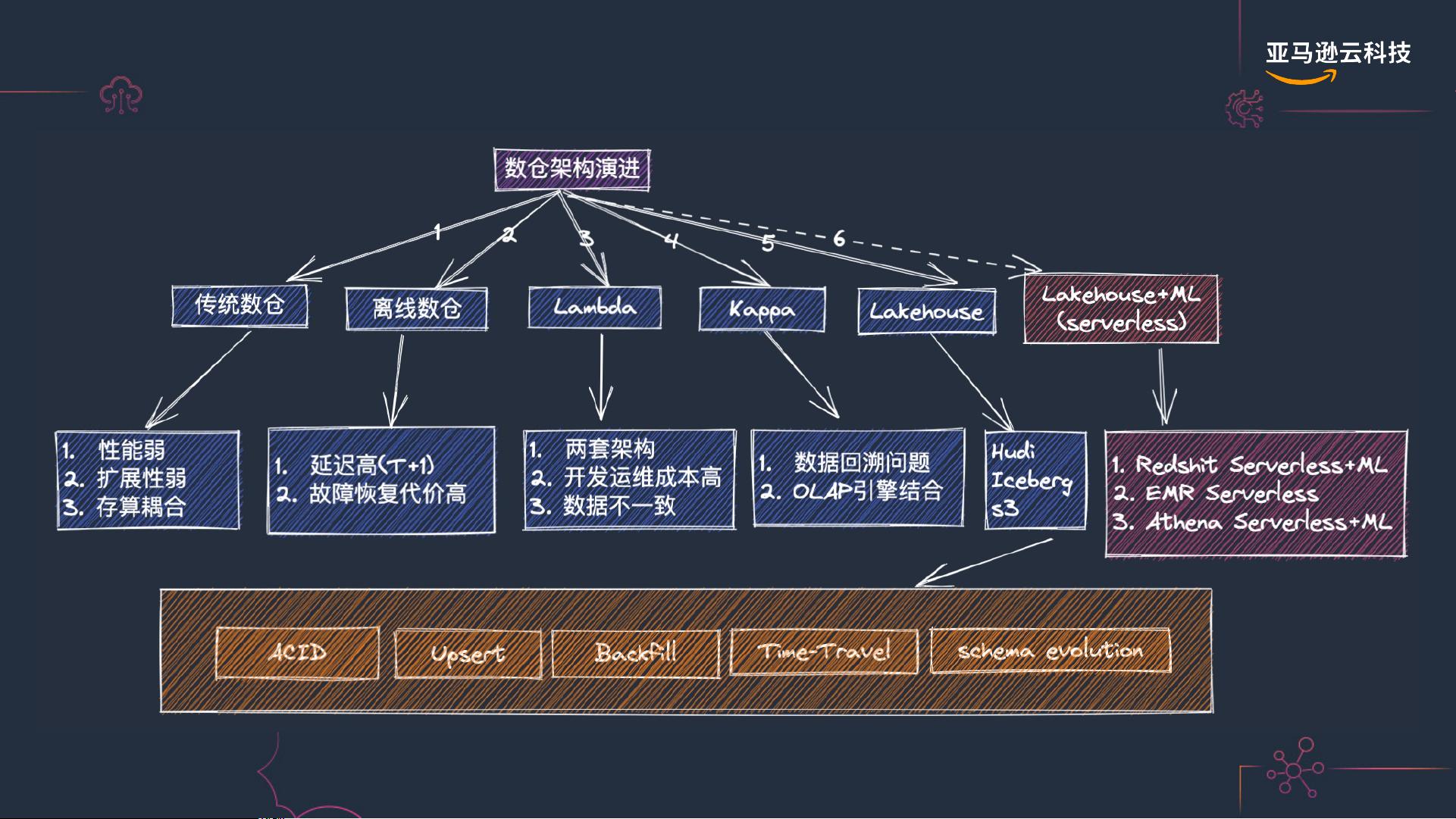
数仓架构演进
剩余19页未读,继续阅读
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传

普通网友
- 粉丝: 12w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
