Python3数据分析:CSV读取与基础统计操作详解
182 浏览量
更新于2024-09-01
收藏 342KB PDF 举报
本篇博客主要介绍如何在Python 3环境下进行数据的读取与基本计算,特别关注于数据分析与挖掘建模实战中的常用统计方法。作者首先强调了数据处理的第一步——使用pandas库的`pd.read_csv()`函数来读取CSV文件,例如通过`df = pd.read_csv('./data/HR.csv')`命令加载名为"HR.csv"的数据集,将数据存储到DataFrame对象df中。
文章详细探讨了数据预览和类型检查,如通过`print(df)`和`print(type(df))`展示数据的结构和类型,以及特定列(如`satisfaction_level`)的数据性质。对于数值型数据,博主重点讲解了以下几类基本统计计算:
1. **平均值**:`mean()`函数用于计算整体数据的平均值,如`df.mean()`或针对单列的平均值`df["satisfaction_level"].mean()`。
2. **中位数**:`median()`函数用来找出中间值,表示数据集的50%数据小于这个值,如`df.median()`获取所有列的中位数,`df["satisfaction_level"].median()`获取指定列的中位数。
3. **四分位数**:`quantile()`函数计算数据的分位数,如`df.quantile(q=0.25)`获取四分之一分位数,也就是Q1,有助于了解数据的分布情况。
此外,博主还提到了计算偏态(skewness)和峰态(kurtosis),这些是衡量数据分布形态的指标,通过`skew()`和`kurt()`函数实现。对于正态分布的分析,博主介绍了`ss.norm.stats()`函数,它能够计算均值、方差、偏态和峰态等参数,而`ss.norm.pdf()`则是概率密度函数,`ss.norm.cdf()`则提供了累积分布函数,用于计算给定值的累计概率。
最后,博主演示了如何使用`ss.norm.rvs()`生成符合正态分布的随机数,并提及了其他分布,如卡方分布(`ss.chi2`)、t分布(`ss.t`)、F分布(`ss.f`),以及如何从样本中抽取特定数量的样本来创建分布(如`ss.fsample(num)`)。
这篇博客深入浅出地展示了Python 3中数据处理的基本操作,包括数据读取、探索性分析和统计描述,适合对数据分析感兴趣的初学者和进阶者参考和实践。
数据的读取与基本计算数据的读取与基本计算
python3数据分析与挖掘建模实战学习目录
代码实例下载
说明:本博客来源于网络整理,部分个人解释说明:本博客来源于网络整理,部分个人解释本文的csv文件数据部分截图pd.read_csv() 读取csv文件mean() # 求平均值median() 求中位数quantile() 求四分位数mode() 求众数
sum() 求和std() 求标准差var() 求方差skew() 求偏态kurt() 求峰态ss.norm.stats() 求均值、方差、偏态、峰态ss.norm.pdf() 概率密度函数ss.norm.cdf() 分位值函数ss.norm.cdf(2))
累积分布函数ss.norm.rvs() 分布随机值生成卡方分布 ss.chi2 ,t分布 ss.t ,F分布 ss.fsample(num) 从样本中抽 num 个样本
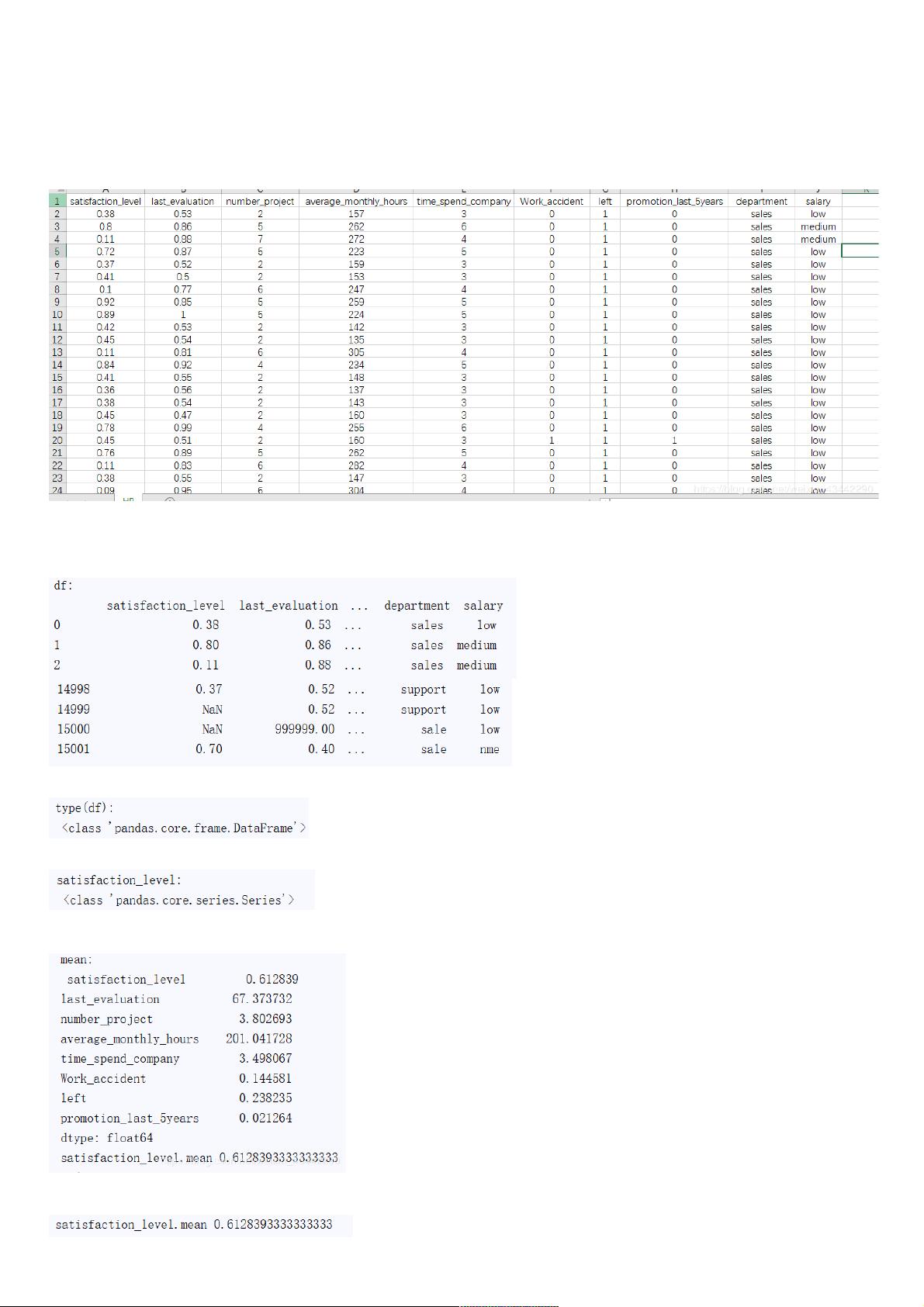
本文的本文的csv文件数据部分截图文件数据部分截图
pd.read_csv() 读取读取csv文件文件
df = pd.read_csv('./data/HR.csv') # 读取csv文件的所有数据,存储在df中
#查看数据梗概
print("df:",df) # 打印所读的csv文件
print("type(df):",type(df)) # 打印类型[15002 rows x 10 columns]
print("satisfaction_level:",type(df["satisfaction_level"]))
mean() # 求平均值求平均值
print("mean:",df.mean())#平均值
# satisfaction_level 列的平均数
print("satisfaction_level.mean",df["satisfaction_level"].mean())
median() 求中位数求中位数
下载后可阅读完整内容,剩余4页未读,立即下载
1203 浏览量
189 浏览量
667 浏览量
703 浏览量
142 浏览量
310 浏览量
2024-05-27 上传
3952 浏览量
2024-11-03 上传

weixin_38537541
- 粉丝: 6
- 资源: 892
 我的内容管理
展开
我的内容管理
展开







