Ubuntu上完全分布式Hadoop安装教程:图文详解与步骤
需积分: 1 21 浏览量
更新于2024-06-16
收藏 32.38MB DOCX 举报
本篇文章是一份详细的Ubuntu上Hadoop完全分布式安装教程,涵盖了从准备工具到配置过程的每一个步骤。以下是主要内容概要:
**一、准备工作**
1. 安装必要的软件:包括Xshell和Xftp7远程管理工具,以及Ubuntu、Java、Hadoop和Eclipse等软件包的Linux版本。
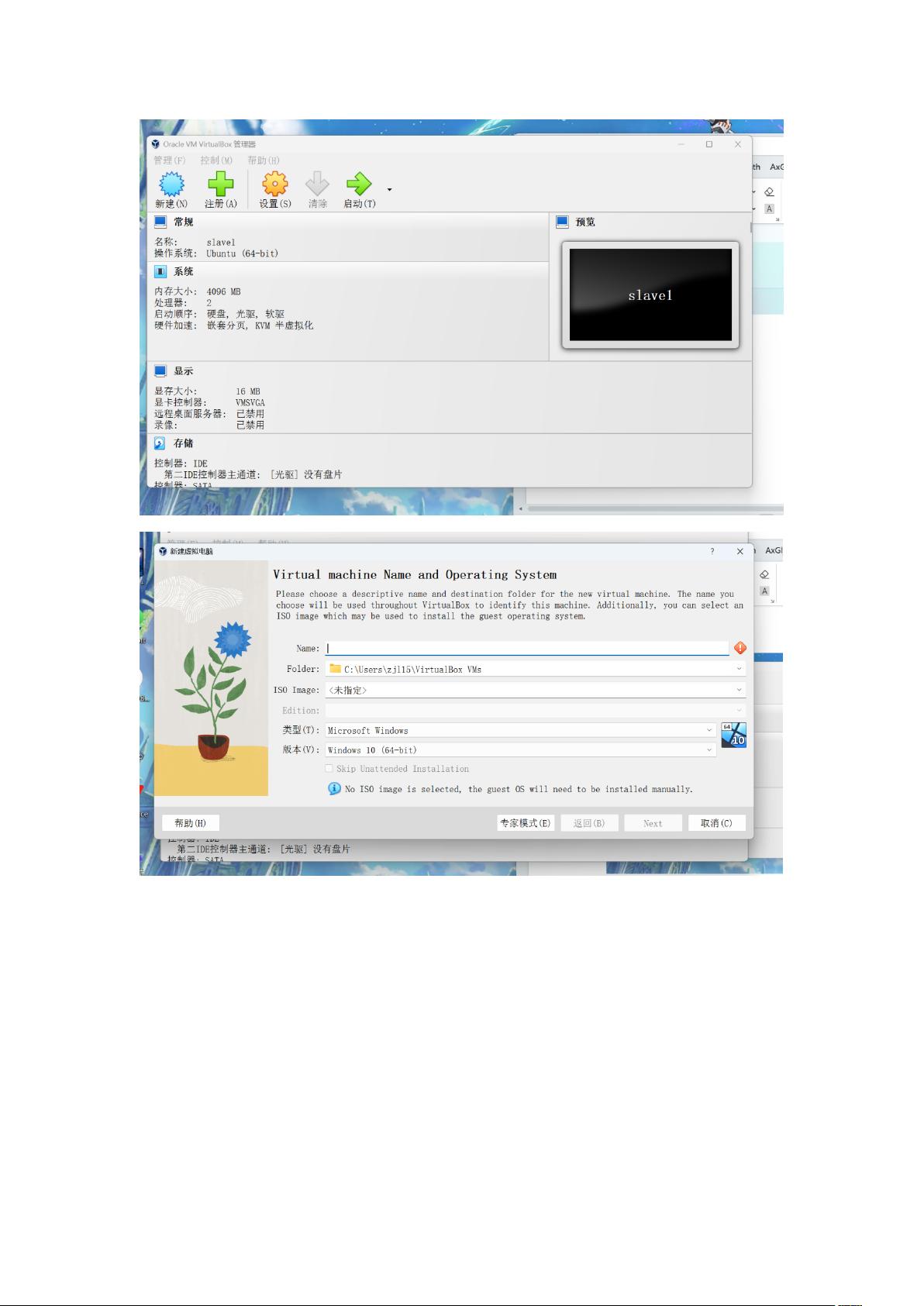
**二、安装虚拟机**
1. 创建一个新的Ubuntu系统,并在启动时进入命令行界面。
2. 修改locale文件,确保支持中文环境(LC_ALL=zh_CN.UTF-8)。
3. 重启虚拟机并进入图形界面。
**三、配置网络结构**
1. 在Ubuntu系统中,通过设置菜单修改网络配置,确保网络畅通。
2. 关闭虚拟机后再次打开,检查网络配置是否生效。
**四、连接Xshell和Xftp**
1. 使用预先安装好的Xshell和Xftp进行远程管理,可能需要处理中断情况。
**五、传输软件包**
1. 将从Windows环境传输至虚拟机的JDK、Hadoop、Eclipse等软件包。
**六、设置主机名和切换用户权限**
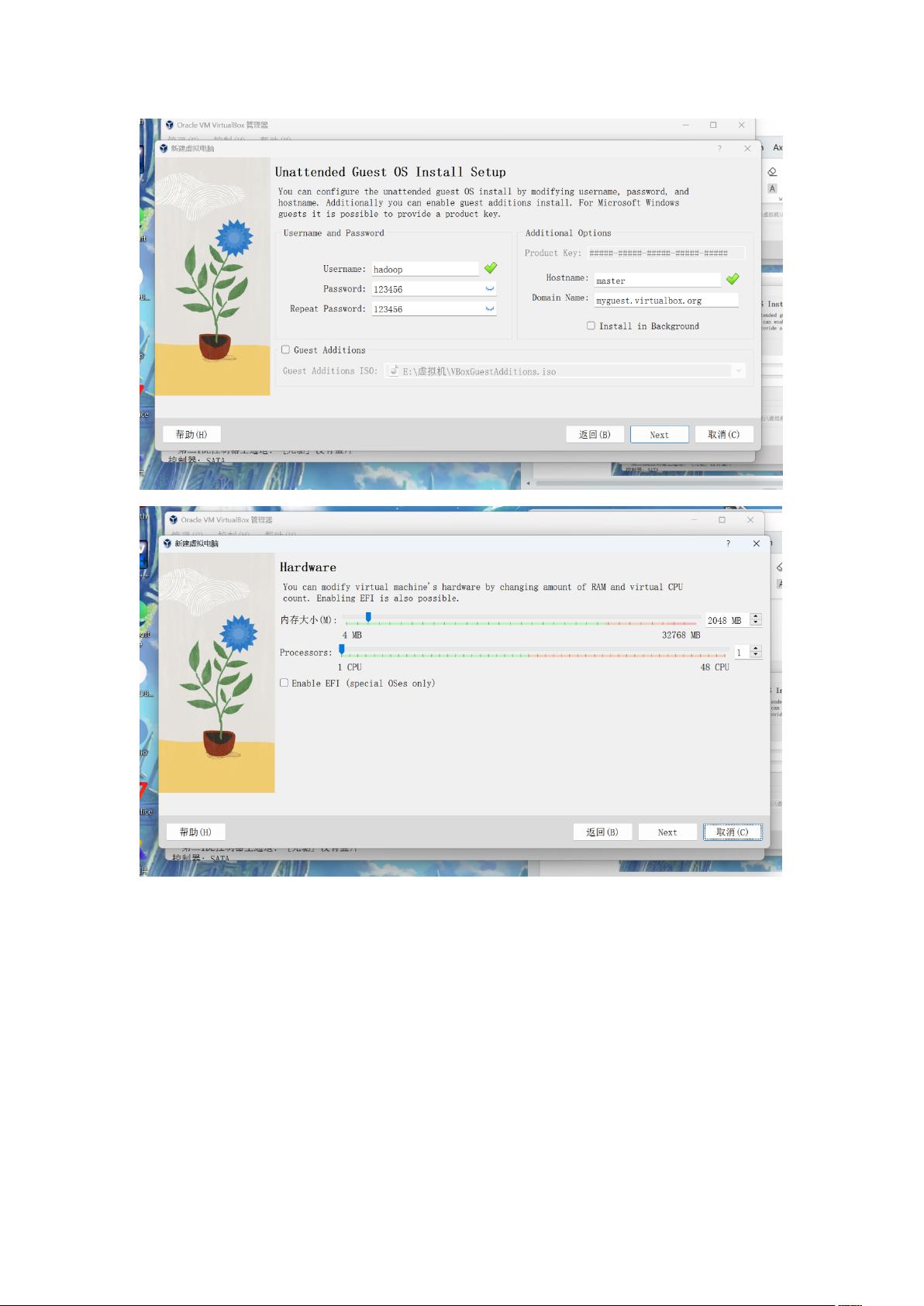
1. 设置三个虚拟机的hostname,主节点为master,从节点分别为slave1和slave2。
2. 以root权限切换到root用户,修改hostname为master。
3. 添加当前用户到sudoers文件,允许使用超级权限。
**七、配置Hadoop**
1. 切换回hadoop用户,因为Hadoop通常运行在该用户下。
2. 由于Hadoop的权限限制,需要添加hadoop用户到sudoers文件,使其能执行超级权限操作。
**八、关闭防火墙**
1. 关闭Ubuntu系统的防火墙,以便Hadoop服务能够正常通信。
在整个过程中,作者提供了详尽的步骤和命令行输入示例,确保读者可以按照这个指南在Ubuntu环境中成功安装和配置Hadoop的分布式环境。这份文档对于那些希望在云计算或大数据处理领域深入学习和实践的开发者来说,是一份宝贵的参考资料。

2014-08-18 上传
2022-09-01 上传
2018-04-20 上传
2022-03-20 上传
2022-03-27 上传
2018-10-10 上传
2019-07-23 上传
2018-07-05 上传

张謹礧
- 粉丝: 2w+
- 资源: 266
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
