深度解析:从FM到AFM,优化推荐系统中的交互特征与高阶模型
需积分: 0 26 浏览量
更新于2024-08-05
收藏 1.2MB PDF 举报
推荐算法是一类重要的机器学习方法,在大规模数据驱动的个性化推荐系统中扮演着关键角色。本文主要探讨了从手动特征提取到深度学习模型的发展,特别是针对FM系列模型和其变体的分析。
首先,手动提取特征的缺点主要在于其专业性和效率问题。挖掘高质量的交互特征需要深厚的专业领域知识,而且需要大量的试错过程,这在数据庞大的推荐系统中几乎是不可能完成的任务。手动特征无法捕捉到肉眼难以察觉的潜在交互模式,限制了模型性能的提升。
FM系列模型,如Factorization Machine (FM) 和 DeepFM,通过将用户和物品的隐向量进行内积,有效地捕捉低阶特征交互。然而,这些模型存在一个问题,那就是它们倾向于学习所有可能的交叉特征,包括一些无效的组合,这会引入噪声,影响模型表现。因此,前期的特征选择显得尤为重要。
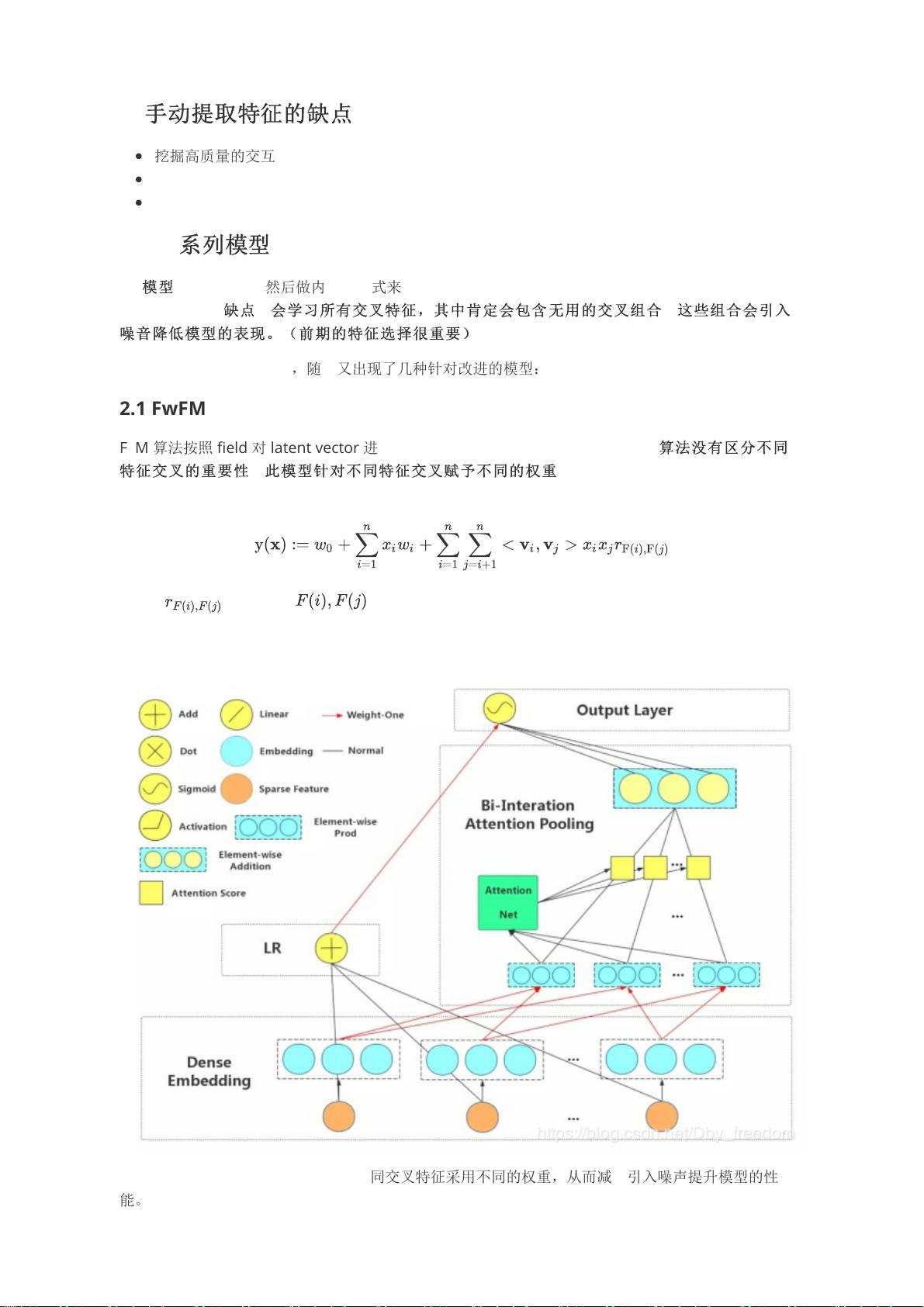
为了改进FM模型,文中提到了FwFM和AFM。FwFM通过根据字段区分隐向量,提高了模型的性能,但未能有效处理不同特征交叉的重要性。相比之下,AFM进一步引入了注意力机制,通过对交叉特征赋予不同的权重,减轻了噪声的影响,实现了更精细的特征融合。AFM模型中,Attention-based Pooling Layer用于计算伪权重并归一化为真实权重,通过加权累加的方式提升了模型的表达能力。
另外,文中还介绍了两种深度学习模型:Field-aware Neural Networks (FNN) 和 Probabilistic Matrix Factorization Network (PNN)。FNN在DNN结构中采用串联方式嵌入字段,利用FM预训练来初始化参数,降低了训练成本,有利于快速收敛。而PNN则在embedding层和DNN输入之间增加了一个product layer,它不依赖于预训练的FM模型,允许更灵活的学习。
总结来说,推荐算法的发展是从原始的手动特征提取,发展到FM系列模型解决低阶特征交互的问题,再到AFM等模型引入注意力机制以优化特征权重,最后通过FNN和PNN这样的深度学习架构,实现了更高级别的特征交互和更精确的模型训练。这些模型的进步不断推动着推荐系统的精度和效率提升。
1.
手
动
提
取
特
征
的
缺
点
挖掘高质量的交互特征需要非常专业的领域知识并且需要做大量尝试,耗费时间和精力。
在大型推荐系统中,原生特征非常庞大,手动挖掘交叉特征几乎不可能。
挖掘不出肉眼不可见的交叉特征。
2. FM
系
列
模
型
FM
模
型
:提取隐向量然后做内积的形式来提取交叉特征,扩展的FM模型更是可以提取随机的高维特征
(DeepFM),
缺
点
:
会
学
习
所
有
交
叉
特
征
,
其
中
肯
定
会
包
含
无
用
的
交
叉
组
合
,
这
些
组
合
会
引
入
噪
音
降
低
模
型
的
表
现
。
(
前
期
的
特
征
选
择
很
重
要
)
针对FM、FFM模型的缺点,随后又出现了几种针对改进的模型:
2.1 FwFM
FFM 算法按照 field 对 latent vector 进行区分,从而提升模型的效果。但是 FFM
算
法
没
有
区
分
不
同
特
征
交
叉
的
重
要
性
,
此
模
型
针
对
不
同
特
征
交
叉
赋
予不
同
的
权
重
,从而达到更精细的计算交叉特征的
目的。
其中, 表示 field 交叉特征的重要性。
2.2 AFM
AFM 和 FwFM 类似,目标是希望对不同交叉特征采用不同的权重,从而减少引入噪声提升模型的性
能。
下载后可阅读完整内容,剩余7页未读,立即下载
1811 浏览量
1920 浏览量
1444 浏览量

马李灵珊
- 粉丝: 41
- 资源: 297
 我的内容管理
展开
我的内容管理
展开







最新资源
- ADO.NET 2.0高级编程
- 一个项目经理的经验总结(网络工程)
- 代码大全是一本成就多少程序员的书啊。
- 芯片sp3232中文介绍
- oracle9i dataguard
- 李亚非老师的神经网络教程
- 无损失”数据格式,对于500万像素的数码相机,一个RAW文件保存了500万个点的感光数据。而TIFF格式在相机内部就处理过,就好比说SONY相机以色彩艳丽著称,富士相机在人像上色彩把握很稳重等,这些都是影像处理器对色彩特别处理的结果。
- 局域网IP冲突问题的探讨
- 深入编程内幕(VC++)
- 上网速度太慢怎么办 21个全面提速技巧
- 深入浅出之正则表达式
- Weblogic管理员手册
- C++ Professional Programmer's Handbook
- MATLAB编程风格指南
- linux 进程间通信
- DHTMLandJavaScript
