Eclipse中配置并运行WordCount MapReduce项目的步骤
需积分: 0 172 浏览量
更新于2024-08-04
收藏 636KB DOCX 举报
在Eclipse中运行MapReduce程序,特别是"WordCount"项目,是一个涉及Hadoop和Java编程的关键步骤。首先,你需要熟悉Eclipse的工作环境并设置好Hadoop配置。以下是如何在Eclipse中实现这一过程的详细步骤:
1. 创建MapReduce项目:
在Eclipse中,通过`File`菜单选择`New` -> `Project...`,然后选择`Map/Reduce Project`,这会启动一个向导来创建新的MapReduce项目。命名该项目为`MyWordCount`,并点击`Finish`来创建。
2. 添加Hadoop配置:
配置是MapReduce程序的基础,包括log4j.properties文件。你需要将其复制到`MyWordCount`项目中,确保日志管理正确。Hadoop配置文件在这里起到连接应用程序与Hadoop集群的作用。
3. 定义Mapper和Reducer类:
创建名为`WordCountTest`的新类,它是Java类的一部分,负责执行MapReduce任务。这个类包含Mapper和Reducer接口的实现,例如处理输入数据(Map阶段),以及对数据进行汇总(Reduce阶段)。这里使用了`IntWritable`和`Text`作为键值对类型,以及`Job`、`Mapper`、`Reducer`等Apache Hadoop库中的核心类。
4. 主方法的设置:
在`WordCountTest`的`main`方法中,创建一个`Configuration`对象,并使用`GenericOptionsParser`解析命令行参数。这些参数用于指定输入和输出文件路径,以及其他配置选项。`FileInputFormat`和`FileOutputFormat`用于指定输入和输出的文件系统操作。
5. 运行MapReduce程序:
使用`Job`类来提交作业到Hadoop集群。调用`Job.getInstance(conf)`初始化一个新的MapReduce作业,设置好输入和输出路径,然后调用`job.waitForCompletion(true)`等待作业完成。
6. 调试和监控:
在Eclipse中,你可以使用调试工具来检查Map和Reduce任务的执行过程,以及查看输出结果。同时,Hadoop提供的Web界面(如Hue或YARN UI)可以用来监控作业的进度和性能。
通过Eclipse的集成开发环境,你可以方便地创建、编译和运行MapReduce程序,如WordCount,从而利用Hadoop分布式计算框架进行大规模数据处理。这一步骤不仅有助于理解和实践MapReduce编程模型,也为后续的大数据分析项目打下了坚实的基础。
8. 在 Eclipse 中运行“Word Count” MapReduce 程序
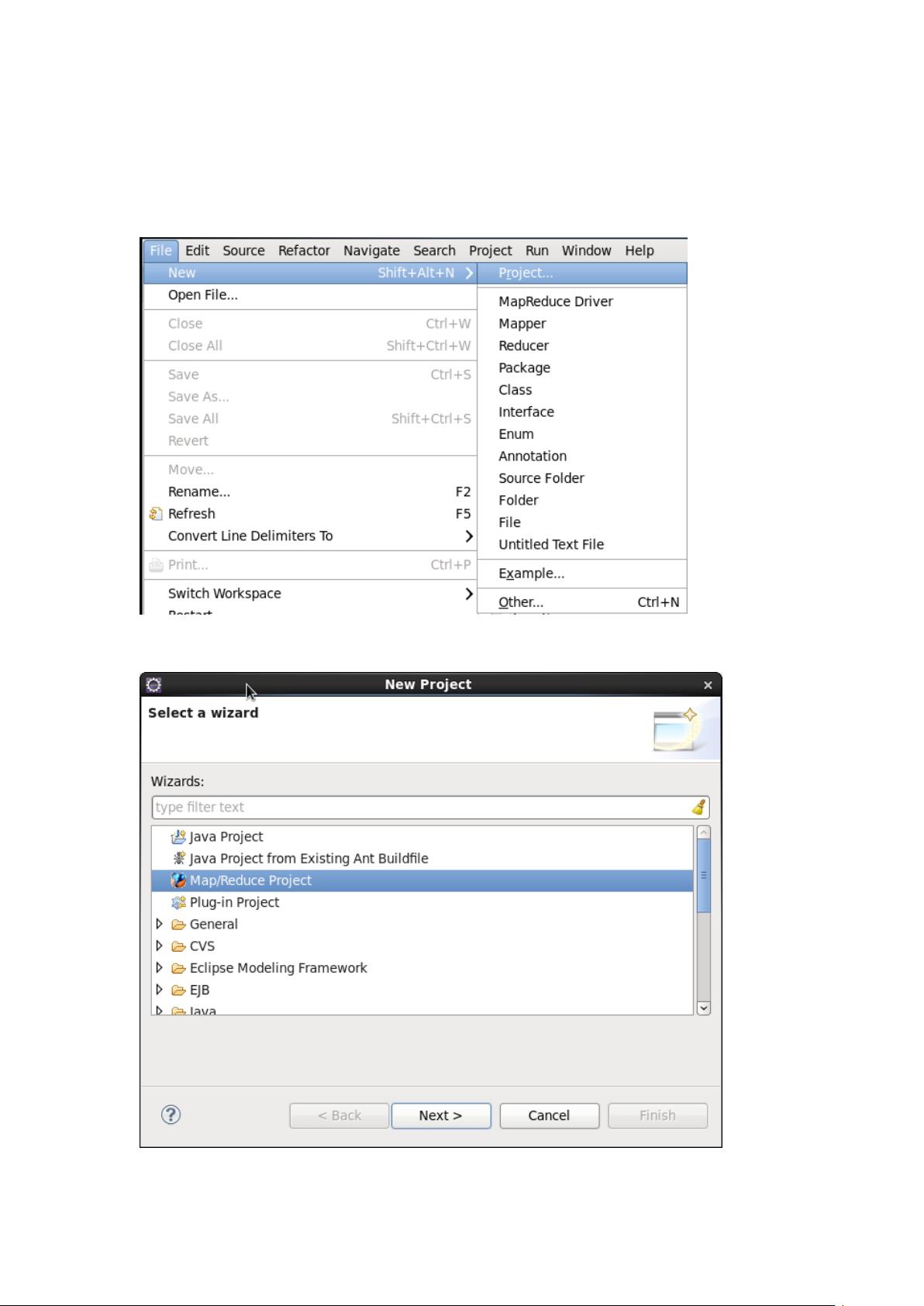
(1)在 Eclipse 中创建 “WordCount” MapReduce 项目
点击 File 菜单,选择 New -> Project…:
选择 Map/Reduce Project,点击 Next:
下载后可阅读完整内容,剩余6页未读,立即下载
198 浏览量
324 浏览量
点击了解资源详情
324 浏览量
1057 浏览量
1362 浏览量
238 浏览量
181 浏览量
173 浏览量

家的要素
- 粉丝: 30
- 资源: 298
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高质量C/C++编程指南(作者:林锐博士,PDF完整版)
- PHP中的代码安全和SQL Injection防范3
- PHP中的代码安全和SQL Injection防范2
- PHP中的代码安全和SQL Injection防范1
- 51单片机指令系统,方便查阅
- 高级Bash脚本编程指南
- 升级PHP5的理由:PHP4和PHP5性能大对比
- oracle常用命令
- PHP上传文件涉及到的参数
- SymtemC user guide
- 联想内部独家资料windows XP 各个文件夹详细介绍.pdf
- VFP的功能及特点.ppt
- Windows 2008中文版安装实录.doc
- Spring开发指南
- Java Script 高端程序设计(精华).pdf
- 第6章 ASP.NET与XML讲解 C#
