算法复杂度详解:O(1)与常数级效率的比较
需积分: 0 82 浏览量
更新于2024-08-05
收藏 646KB PDF 举报
算法脑图1主要探讨了计算机科学中的核心概念——算法复杂度,特别是时间复杂度和空间复杂度。时间复杂度是衡量算法执行效率的重要指标,分为不同级别:
1. **O(1)**:最佳常数复杂度,如哈希表(HashTable)和Cache,这类算法的执行时间与输入数据规模无关,始终在固定时间内完成,是理想的时间复杂度。
2. **O(log n)**:次于常数复杂度,如二分查找(Binary Search)和二叉搜索树,这类算法的运行时间随着输入大小呈对数增长,效率较高。
3. **O(n)**:线性复杂度,适用于大多数遍历操作,如树的深度优先搜索(DFS)和广度优先搜索(BFS),这类操作的执行次数与输入规模成正比。
4. **O(n^2)**:双层循环,例如嵌套循环,这类算法性能较差,当数据量增大时,运行时间急剧增加。
5. **O(2^n)**:递归操作,如果递归没有优化,可能导致指数级的时间复杂度,效率极其低下。
空间复杂度涉及算法所需的存储空间:
- **O(1)**:原地操作,算法只需要常数级别的额外空间,如栈和队列。
- **O(n)**:开辟线性辅助空间,比如在数组或链表中进行查找、插入或删除操作时,可能需要额外的存储空间与输入规模成正比。
数据结构的选择影响了这些复杂度,例如:
- 数组(连续空间):查找快但插入和删除慢。
- 链表(离散空间):查找慢但插入和删除快。
- 哈希表(HashTable)、Cache和LRU:支持快速查找,get和set操作常数时间复杂度。
- 并查集(用于解决站队问题):包含初始化、查询合并和路径压缩等操作,用于维护集合的连通性。
- 字典树(Trie):空间换时间的思想,用于高效存储字符串集合。
- 图的遍历:递归和分治策略,需记录访问节点,动态规划可能用到。
算法设计时要考虑终止状态、递归处理、状态管理和优化结构,如贪心算法、动态规划(包括递推公式和缓存技术)以及位运算。在某些场景下,还需要关注数据结构的有序性、边界条件和随机访问能力。
理解算法复杂度和选择合适的数据结构是提高程序效率的关键,而不同的算法和数据结构各有其适用场景和性能特点。在实际编程中,根据具体需求灵活运用这些知识是提升代码质量和效率的有效途径。
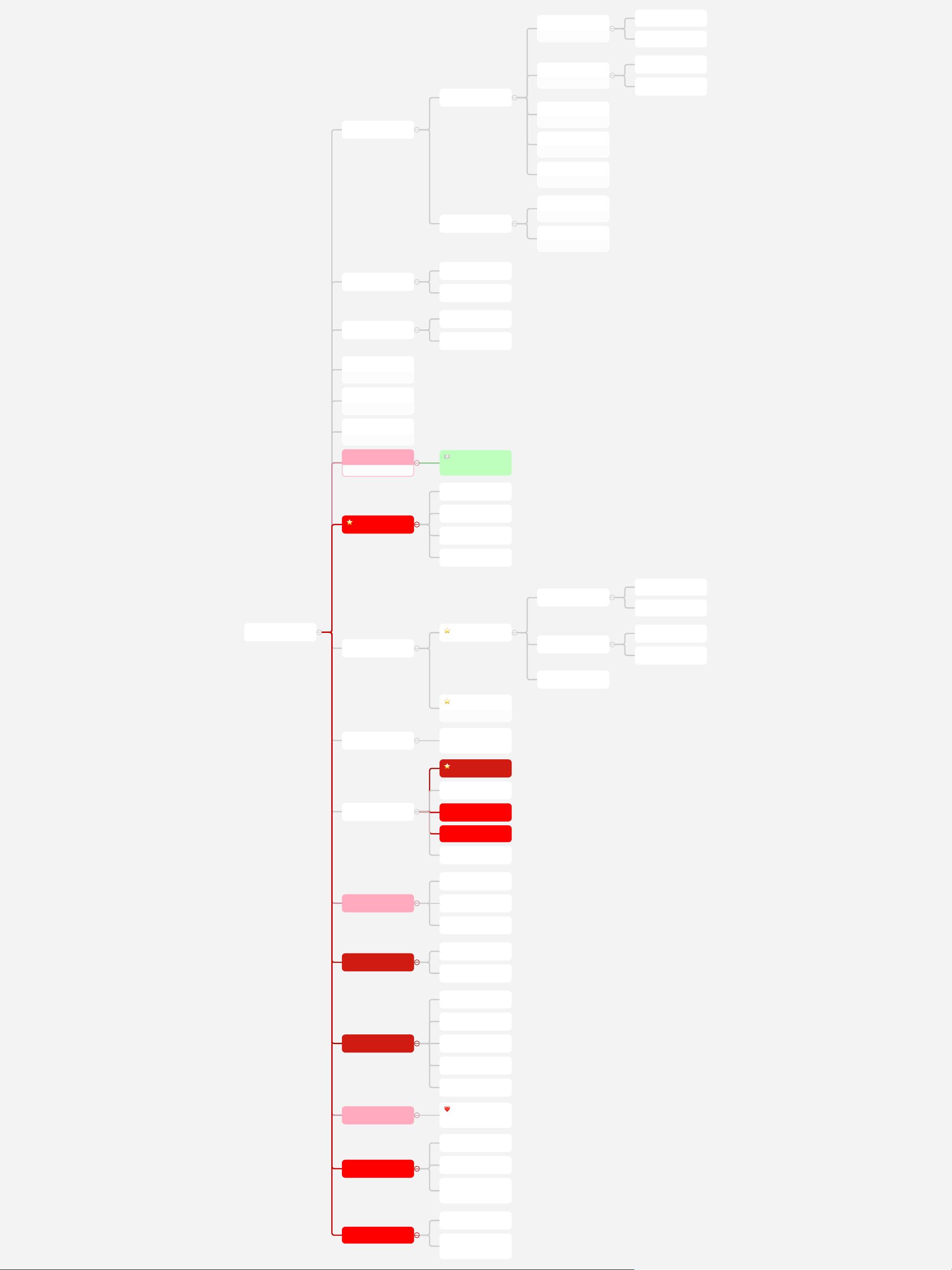
算法
复杂度
时间复杂度
O(1) 最佳
常数复杂度
Hash Table
Cache
O(Log n)
仅次常数复杂度
⼆分查找
⼆叉搜索树
O(n)
线性复杂度, 如⼤多数遍历操作
O(n^2)
双重 for 循环
O(2 ^ n)
递归的时间复杂度
空间复杂度
O(1)
原地操作
O(n)
开辟线性辅助空间
数组
连续空间
查找快、插⼊/删除结点慢
链表
离散空间
查找慢、插⼊删除结点快
栈
先进后出
队列
先进先出
映射
K/V
集合
Key 不重复
🏳
集合内的元素不重复,
不存在Key的概念
⭐
并查集
站队问题
初始化
查询合并
路径压缩
树
⭐
⼆叉树
遍历
DFS
BFS
平衡⼆叉树
AVL 树
红⿊树
剪枝
⭐
字典树
空间换时间
图
遍历时需要记录访问过的
结点
递归、分治
⭐
盗梦空间
终⽌状态
本层处理
Drill Down
分层状态清理
⼆分查找
有序
有界
能够通过索引随机访问
贪⼼算法
判断能不能贪⼼
弱化版的动态规划
动态规划
⾼级版本是递推公式
简单版本是递归+缓存
状态的定义
最优化结构
状态转移⽅程
位运算
❤
常⻅的位运算公式, 记
忆
布隆过滤器
判断不存在 100% 准确
判断存在误差
利⽤Hash函数将判断
Kewy 对应到多个位上
LRU
HashTable + 双向链表
get 和 set 都是 O(1) 复杂
度
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
2023-03-25 上传
2023-08-25 上传
2023-11-19 上传
2023-11-19 上传
2023-09-17 上传
2023-05-29 上传

明儿去打球
- 粉丝: 17
- 资源: 327
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
