"国科大人工智能学院大数据课程笔记总结:结构化与非结构化数据处理及数据挖掘分析"
需积分: 0 161 浏览量
更新于2023-12-18
收藏 3.06MB DOCX 举报
国科大人工智能学院的大数据课程笔记总结了课程的核心内容,重点强调了结构化数据和非结构化数据的概念以及大数据的预处理工作。根据课程ppt中的重要部分进行了高亮,并详细阐述了一些关键概念和方法。
首先,在第一章中,学院介绍了结构化数据和非结构化数据的区别。结构化数据是可以用二维表结构来逻辑表达实现,并可存储在数据库中的数据。而非结构化数据则是指那些无法通过预先定义的数据模型表述或无法存入关系型数据库表中的数据。这个概念的理解对于后续的数据处理工作非常重要。
接下来,学院强调了大数据的预处理的重要性。在进行数据挖掘之前,需要对原始数据进行清洗、集成和变换的一系列处理工作。大数据挖掘分析往往容易受到噪声、缺失值和不一致数据的干扰,因此对于缺失数据的处理是一个关键步骤。课程笔记给出了三种常见的缺失数据处理方法:使用常量填充缺失值、使用属性的中心度量填充缺失值和使用最可能的值填充缺失值。此外,还介绍了使用给定元组属于同一类的所有样本的属性均值或中位数来填充缺失值的方法。
此外,学院还介绍了数据集成和数据变换的概念和作用。数据集成是将数据由多个数据源合并成一个一致的数据存储的过程,它有助于减少结果数据集的冗余和不一致,提高挖掘的准确性和速度。而数据变换的目的是将数据变换或统一成适合挖掘的形式。这些步骤对于后续的数据分析和挖掘工作起到了关键作用。
此外,课程还介绍了布尔检索模型和评价指标。布尔检索模型是一种最早的信息检索模型,通过逻辑表达式来检索相关的文档。而评价指标中,正确率和召回率是两个非常重要的指标。正确率是返回结果中真正和信息需求相关的文档所占的百分比,召回率是所有和信息需求真正相关的文档中被检索系统返回的百分比。这些指标对于评价检索系统的性能非常重要。
最后,课程还介绍了倒排索引的概念和作用。倒排索引是一种用于加快文本搜索速度的数据结构。它由词项词典和倒排记录表组成,可以根据关键词快速找到包含该关键词的文档。倒排索引在信息检索和搜索引擎等领域有着广泛的应用。
综上所述,国科大人工智能学院的大数据课程笔记主要讲解了大数据的预处理工作,包括缺失数据处理、数据集成和数据变换等概念和方法。课程还介绍了布尔检索模型、评价指标和倒排索引等相关内容。这些内容对于理解和应用大数据分析和挖掘技术非常有帮助。
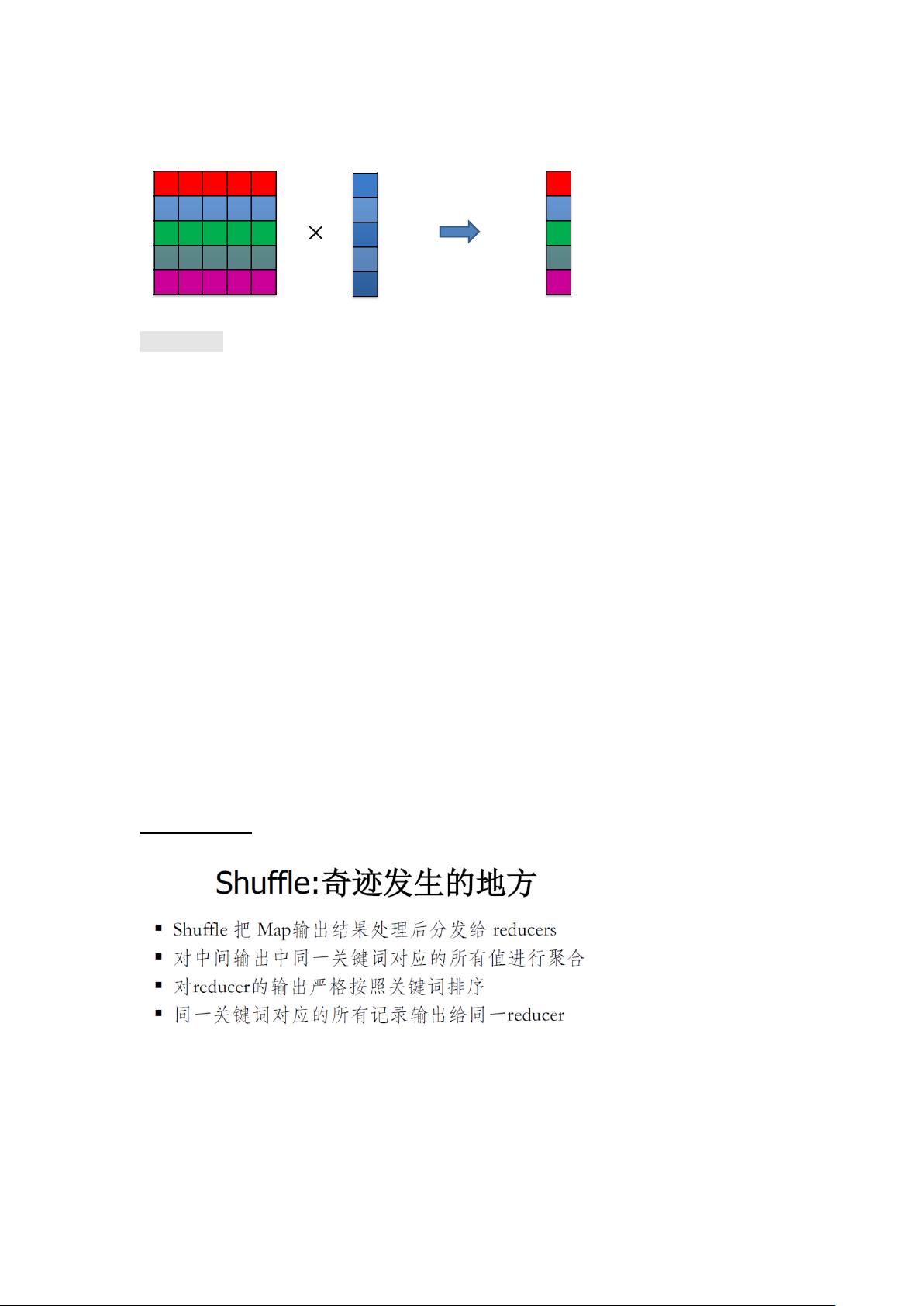
解决大矩阵相乘:拆分
存储:M 存储为稀疏矩阵
MapReduce 主要设计为面向顺序式大规模数据的磁盘访问处理:一次写入,多次读取。每
次分析都将涉及该数据集的大部分数据甚至全部
把计算向数据迁移,而不是把数据向计算迁移
HDFS 是一个高度容错性的分布式文件系统,适合部署在廉价的机器上,能提供高吞吐量的
数据访问,非常适合大规模数据集上的应用,一次写入,多次读取。
HDFS 以块作为存储单位,一个文件被分成多个块,默认一个块 64MB,可以最小化寻址开
销
HDFS 抽象块概优势:①支持大规模文件存储;②简化系统设计;③适合数据备。
Map 任务将文件块转换成 key,value 对,将按照 key 大小排序
这些 key 又被分区到不同的 Reduce 任务中,并且具有相同 key 的 key,value 对被分组归到同
一 Reduce 任务中。
Reduce 任务每次作用于一个 key,并将与此 key 关联的所有 value 值以某种方式组合起来
Hadoop 将 MapReduce 的输入数据划分为等长的小数据块(inputsplit),简称“分片
数据本地化原则:Hadoop 在存储有输入数据(HDFS 中的数据)的节点上运行 map 任务,可以
获得最佳性能
Reduce 函数收集 Mapreduce 框架发送过来的键值对
遍历分组列表,找到最大的读数,输出键值对
剩余14页未读,继续阅读
1563 浏览量
2024-05-29 上传
237 浏览量

UreisenL
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 普天身份证阅读器新版二次开发包发布
- C# 实现文件的数据库保存与导出操作
- CkEditor增强功能:轻松实现图片上传
- 掌握DLL注入技术:测试工具使用与探索
- 实现带节假日农历功能的jQuery日历选择器
- Spring循环依赖示例:深入理解与Git代码仓库实践
- ABB PLC液压阀门控制程序开发指南
- 揭秘4核旋风密版626象棋引擎的超牛实力
- HTML5实现的经典游戏:小霸王坦克大战源码分享
- 让Visual Studio兼容APM硬件信息的方法
- Kotlin入门:创建我的第一个应用
- Android语音识别技术研究报告与应用分析
- 掌握JavaScript基础:第8版教程源代码解析
- jQuery制作动态侧面浮动图片广告特效教程
- Android PinView仿支付宝密码输入框源码分析
- HTML5 Canvas制作的围住神经猫游戏源码分享
