深入理解Kafka:Broker、Producer与Consumer解析
需积分: 10 2 浏览量
更新于2024-07-15
收藏 5.96MB PDF 举报
"kafka资料,懂的来!"
Kafka是一种分布式流处理平台,由Apache软件基金会开发。它最初由LinkedIn设计并开源,现在已成为大数据领域的重要组件。Kafka主要用作实时数据管道,用于在系统或应用之间高效地发布和订阅数据流。
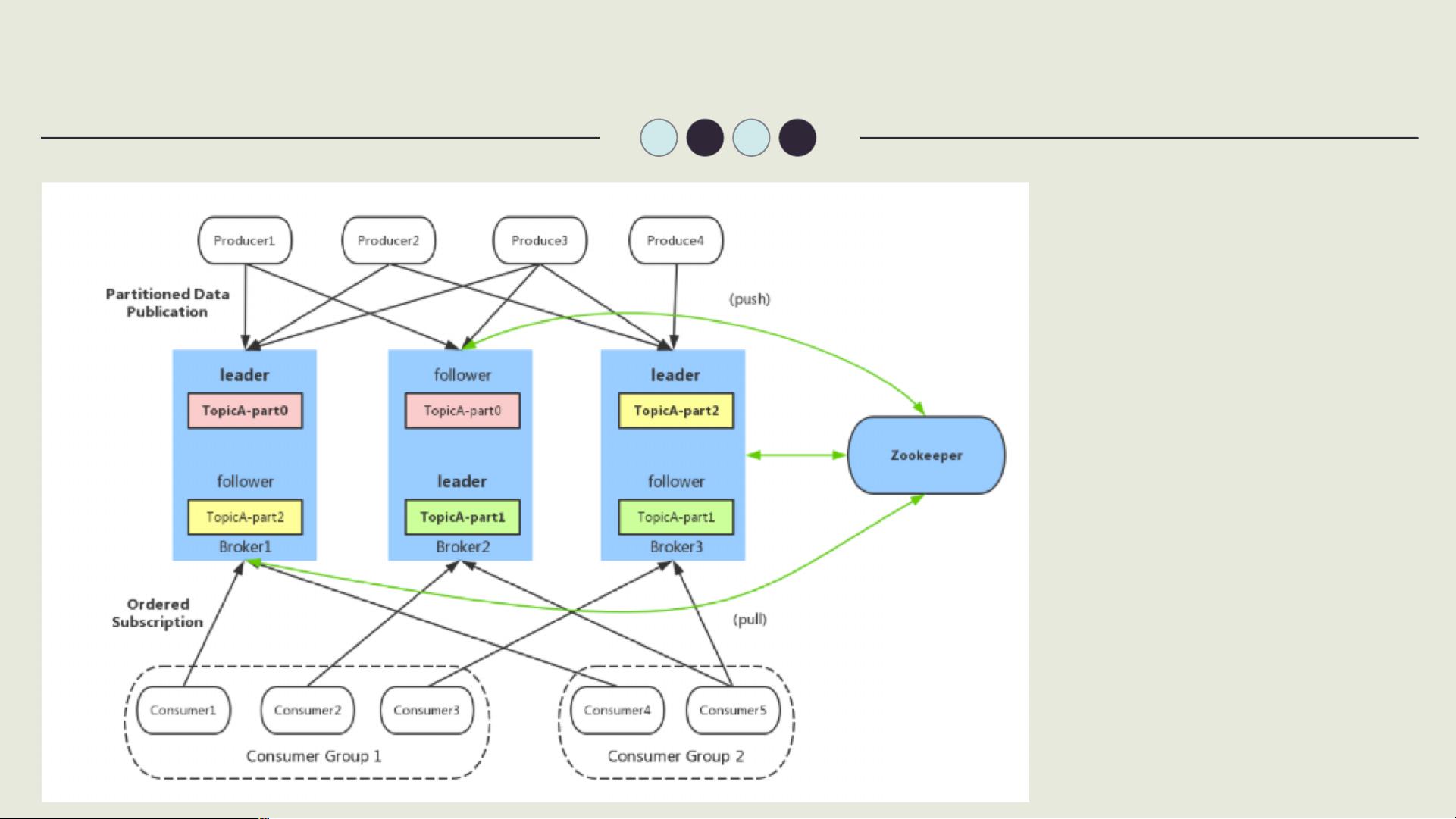
**1. Broker**
Kafka的核心组件是Broker,它是一个服务器节点,负责存储和转发消息。多个Broker组成一个Kafka集群,提供冗余和容错能力。每个Broker包含多个Partition(分区),Partition是数据存储的基本单位,确保了消息的有序性和可扩展性。
**2. Producer**
Producer是Kafka系统中的数据发布者,它负责将消息发送到指定的Topic(主题)。Producer可以将数据推送到Brokers,同时可以选择消息的分区策略,例如轮询或者基于键的哈希分区,以实现数据分布的均衡。
**3. Consumer**
Consumer是消息的消费者,可以从一个或多个Topic中拉取数据。Kafka支持两种消费模式:单消费者和消费者组。在消费者组模式下,一组消费者会共同订阅一个Topic,消息会被分发给组内的不同消费者,从而实现负载均衡和高可用。
**4. Topic**
Topic是Kafka中消息的分类,类似于数据库的主题或表。每个Topic可以被分为多个Partition,Partition在物理上是有序的消息序列,每个Partition在集群中的一个Broker上存储。
**5. Partition**
Partition是Kafka的逻辑存储单元,每个Partition包含一系列有序且不可变的消息。Partition的特性使得Kafka能够实现高吞吐量的数据处理。Partition的Leader副本负责接收和处理Producer的数据,而Follower副本则同步Leader的数据,以提供容错能力。
**6. Offset**
Offset是Kafka中用来跟踪消息位置的唯一标识,它是一个递增的整数,表示消息在Partition中的位置。Consumer通过Offset来记录其在Partition中的读取进度,从而实现消息的顺序消费或重复消费。
在实际使用中,Kafka还提供了其他关键功能,如消息保留策略(可以设置消息的存活时间)、幂等性生产者(防止重复消息)以及事务支持等。Kafka通常与其他大数据工具(如Hadoop、Spark)集成,构建实时数据处理和分析的解决方案。它的高性能、可扩展性和容错性使其成为大数据领域不可或缺的一部分。
剩余26页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-12-23 上传
299 浏览量
2021-06-12 上传
109 浏览量
107 浏览量
440 浏览量

phpstory
- 粉丝: 356
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现DataGridView过滤功能的源码分享
- Python开发者必备:VisDrone数据集工具包
- 解决ESXi5.x安装无网络适配器问题的第三方工具使用指南
- GPRS模块串口通讯实现与配置指南
- WinCvs客户端安装使用指南及服务端资源
- PCF8591T AD实验源代码与使用指南
- SwiftForms:Swift实现的表单创建神器
- 精选9+1个网站前台模板下载
- React与BaiduMapNodejs打造上海小区房价信息平台
- 全面解析手机软件测试的实战技巧与方案
- 探索汇编语言:实验三之英文填字游戏解析
- Eclipse VSS插件版本1.6.2发布
- 建站之星去版权补丁介绍与下载
- AAInfographics: Swift语言打造的AAChartKit图表绘制库
- STM32高频电子线路实验完整项目资料下载
- 51单片机实现多功能计算器的原理与代码解析
