随机森林模型详解:从决策树到森林
版权申诉
"通俗易懂的随机森林模型讲解"
随机森林是一种集成学习方法,它通过构建并结合多个决策树来进行预测。在这个模型中,“森林”是由众多“大树”组成,即由许多决策树构成。每棵决策树都是独立训练的,它们在训练过程中引入了随机性,比如在每个节点分裂时,不是考虑所有特征,而是随机选取一部分特征进行最优分割。这样做的目的是增加模型的多样性和降低过拟合的风险。
决策树是随机森林的基础单元,它是一种结构化的分类或回归模型,以树状结构来表示输入变量与输出变量之间的关系。在小木的例子中,决策树用于帮助小木决定是否与中介公司介绍的女孩见面。决策树通过一系列问题(特征)来逐步划分数据集,直到达到预设的终止条件,如最小节点样本数或最大深度。在这个过程中,选择最优特征的准则通常是信息增益或基尼不纯度,这些指标有助于评估特征对数据纯度的改善程度。
熵是衡量数据集纯度的一个概念,信息熵公式为 H(D) = -∑(p_i * log2(p_i)),其中 p_i 是类别 i 出现的概率。在小木的例子中,熵用来评估见面与否的不确定性。较低的熵意味着数据集更纯,决策边界更清晰。
在构建决策树时,我们通常寻找能最大化信息增益或最小化基尼不纯度的特征进行划分。当特征较多时,随机森林会在构建每棵树时只考虑一部分特征,这被称为特征袋ging(bootstrap aggregating),使得每棵树都有自己的特点,从而提升整体模型的性能。
随机森林在投票机制上工作,对于分类问题,每棵树都会对样本进行预测,最终结果是基于多数票决定;对于回归问题,所有树的预测结果会被平均处理。这种组合策略使得随机森林能够处理高维度数据,减少过拟合,并提供特征重要性的估计。
随机森林通过构建多个决策树并结合它们的预测,提高了模型的稳定性和准确性。其随机性体现在特征选择和子样本抽取上,这些特性使得随机森林成为一种强大的机器学习工具,广泛应用在各种领域,如分类、回归、特征选择等。
通俗易懂的随机森林模型讲解通俗易懂的随机森林模型讲解
大家好,我是你们的好朋友小木。对于随机森林的模型,网上已经有灰常灰常多的讲解,大家讲的也非常的不错。但绝大多数
大神讲解都是注重于理论,把算数的地方都给忽略了,我这次要以举例子的方法来讲解,这样可以让大家更好的理解随机森林
模型。
首先我们来定义一下随机森林,啥叫随机森林呢,森林指的是有一堆大树的地方,随机指每棵大树种植的过程中施肥的种类是
随机地选择的。但是好好地一个模型怎么就变成大树了呢?当然不是啦,这里大树指的是决策树,而施肥指的是不同的限定条
件。接下来,又有小朋友问我啥叫决策树,好大的一棵树啊,不懂o(∩_∩)o ,那么我就来讲一下啥叫决策树。
顾名思义,决策就是评价的意思,我们用一颗大树评价一个事物,这样的大树就叫做决策树。那么我们决策啥?往后看就直到
了
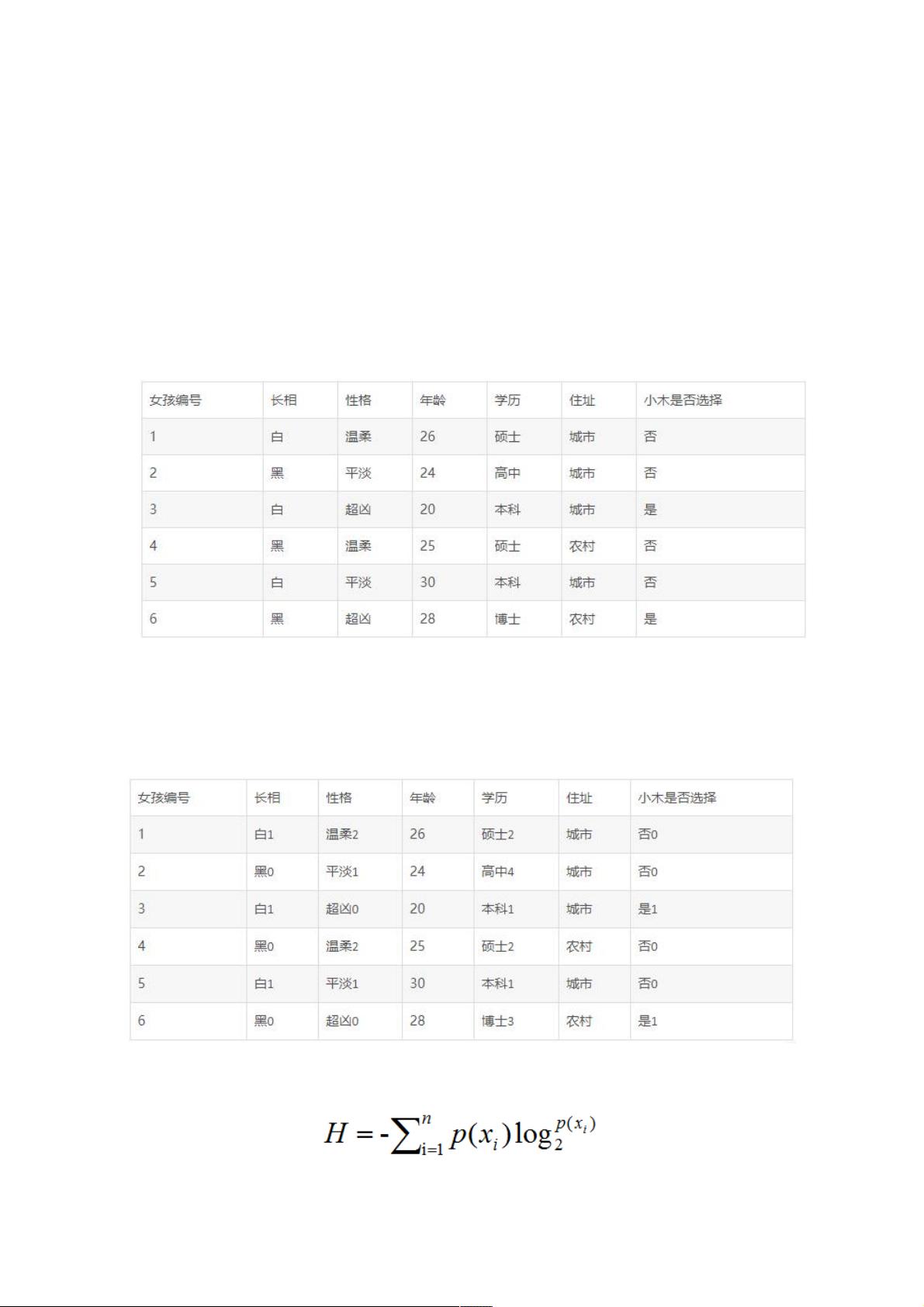
比如小木想要找女朋友,但他是个人,他有自己喜欢的类型,不是任何人都会同意的。我们现在有一个中介公司给小木介绍了
五个女孩,她们的条件、以及小木是否想见面分别如表1所示:
表1
我们要决策的就是小木是否选择见面,其中结果有两个,一个是是,一个是否。
这个表格中有长相、性格、年龄、学历、小木是否选择几项,除了年龄之外全都是文字,我们要建立数学模型这是不可以的,
那么我们必须给它们转换为数字形式,转换之后如表2所示:
表2
这个表格把各个变量都应用上了数字,例如性格中,分为了0,1,2三类。我们分完类别之后呢,下一步我们就要选择一个特
征,然后判断小木是否见面。特征怎么选?我们用一个叫做熵值公式,它的计算公式如下:
举个例子,比如分析小木是否选择见面,在表格2里面,选择“是”情况有两种,“否”情况有三种,共五个,所以选择“是”的概率
为2/6=0.33,选择否的概率为4/6=0.67。然后我们把0.4和0.6带入公式(1)中,得到:H0=-
(0.33*log20.33+0.67*log20.67)=0.92
下载后可阅读完整内容,剩余5页未读,立即下载
329 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
391 浏览量
点击了解资源详情
928 浏览量
2025-01-10 上传

weixin_38708105
- 粉丝: 9
- 资源: 865
 我的内容管理
展开
我的内容管理
展开







最新资源
- 轻轻松松集成PayPal.标准版+.Jan07.pdf
- The+Java+Language+Specification
- 综合布线相关标准介绍
- C++的STL的内容
- 练成Linux系统高手教程
- PCB Layout走线设计技巧.pdf
- GB-T 14912-2005
- OpenGL教程(大师版)
- Using as The gnu Assembler
- unix常用命令介绍
- 会声会影11超级快速入门教材(简体中文带彩图)
- Spring_Live[非常好].pdf
- Linux 使用技巧33条
- Oracle sql 性能优化调整
- jsp 的高级教程 讲解很好
- Computational Geometry: Algorithms and Applications Third Edition
