分布式缓存技术在插入密集型系统中的应用与实现
版权申诉
148 浏览量
更新于2024-07-02
收藏 1.18MB PDF 举报
"分布式缓存技术在插入密集型系统中应用的研究与实现"
随着互联网行业的飞速发展,分布式缓存技术已成为提升系统性能的关键组件。它主要用于缓解数据库压力,提高响应速度,尤其在查询密集型应用中表现突出。然而,尽管查询密集型场景是分布式缓存的常见应用场景,但其潜力并未被完全发掘。本研究旨在探索分布式缓存技术在插入密集型系统中的应用,以期进一步提升系统的吞吐率。
本论文基于国家信息产业部电子发展基金项目——高性能、高可靠入侵防御系统研发与产业化,针对项目对系统吞吐量的高要求,深入探讨了在插入密集型系统中引入分布式缓存的可能性和挑战。以下是本文的主要研究内容:
1) 系统架构设计:通过对插入密集型系统进行深入分析,设计出了一种在该类系统中集成分布式缓存的架构。这种架构旨在优化数据插入流程,同时保持系统稳定性和可扩展性。
2) 数据冗余技术:研究了一致性哈希算法和虚拟节点技术,并在此基础上提出了一种基于一致性哈希的数据冗余策略。通过将数据分散存储在多个缓存服务上,有效降低了因单点故障导致的数据丢失风险。
3) 缓存管理技术:在分析了现有的缓存管理方法后,提出了集中管理和本地询问相结合的方案。详述了管理数据的初始化和修改流程,确保了数据的一致性和高效访问。
4) 高性能实现:通过采用非阻塞通信技术、基于JSON的序列化和concurrent同步技术,实现了高速、高并发的分布式缓存系统。这些技术的选择和整合有助于提升系统的并发处理能力和数据处理速度。
本文的研究不仅拓宽了分布式缓存技术的应用边界,也为插入密集型系统的性能优化提供了新的思路。通过实际系统实现,证明了在插入密集型场景中应用分布式缓存技术的可行性与优越性,为相关领域的实践提供了理论支持和技术参考。关键词:缓存、分布式、数据冗余、缓存管理。

第二章 知识背景
9
2.2.3 按缓存使用范围分类
缓存按使用范围又可以分为进程缓存、单机缓存和分布式缓存。
1. 进程缓存
进程缓存指的是缓存的读取只能在同一个进程中进行。一般进程级缓存是由
进程本身创建的一块缓存区。该缓存只为该进程服务,其他进程没法共享该缓存
区。
2. 单机缓存
单机缓存指的是缓存的读取只能在本机内部进行访问。单机缓存在文件缓存
中经常出现。如前面提到的在浏览器中缓存的 css 文件、html 文件等。这些数据
只能本机访问,其他机器一般情况下是不能访问的。
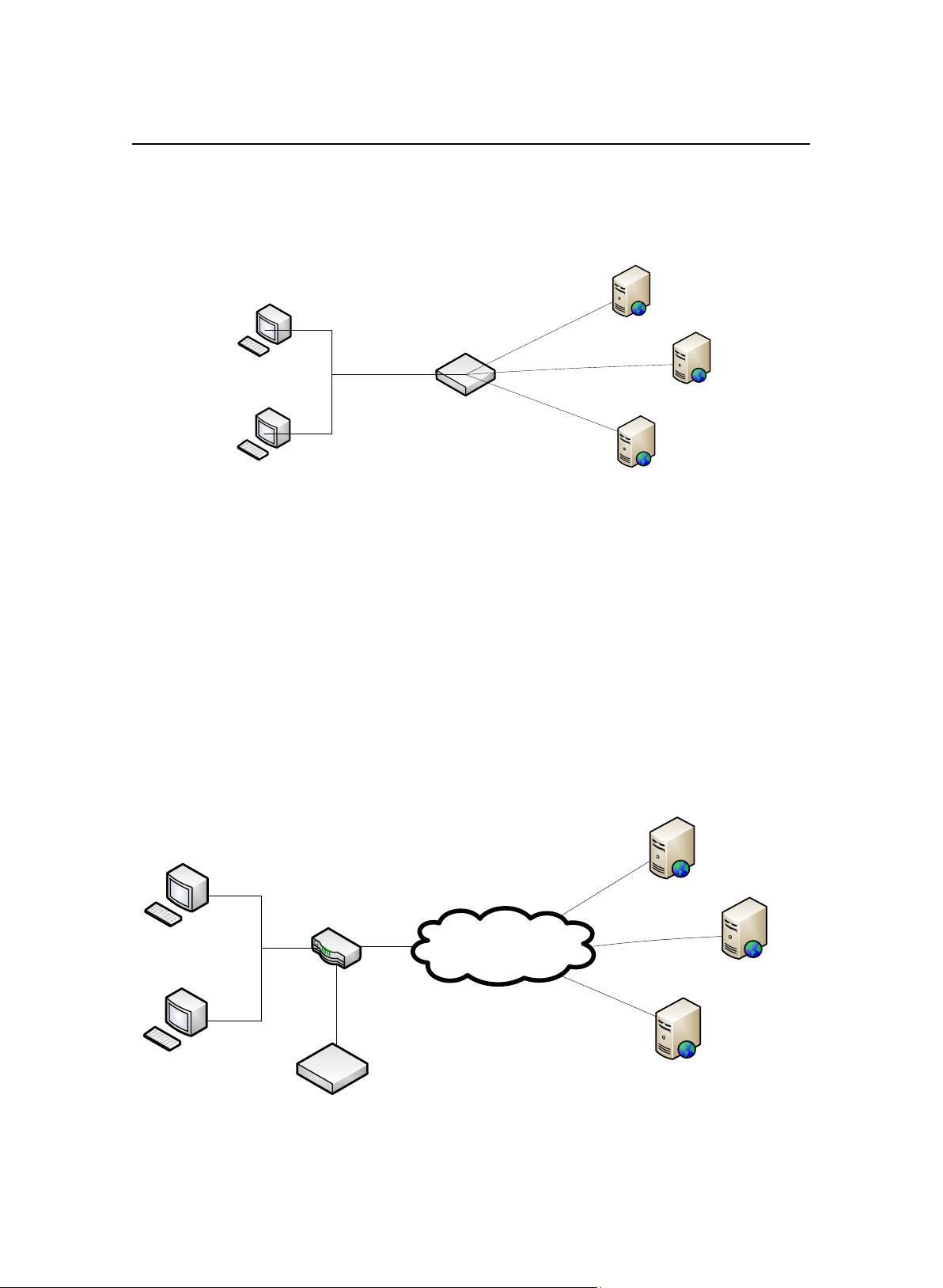
3. 分布式缓存
分布式缓存指的是数据分布在一个有多个缓存服务器构成的集群中,对缓存
的读写可用通过网络进行。分布式缓存系统会对外提供一个基于网络的调用接口,
这个接口可能是基于远程调用的,也能能基于基本的 Socket 通信的。
2.3 互联网中的缓存应用
为了提高网站访问的效率,缓存技术也被大量的应用到了互联网中
[14]
。在互
联网中的缓存的应用主要包括客户端缓存、代理缓存
[15]
和服务器缓存。
2.3.1 客户端缓存
客户端缓存一般属于单机缓存,它存在与客户端程序中,当然在 Web 环境下
客户端就是浏览器,所以 Web 客户端缓存也可以叫做浏览器缓存。用户访问互联
网的时候下载下来的数据,浏览器会把它保存在本地的磁盘中,当用户下一次访
问相同资源的时候,浏览器就可以不用访问网络去下载数据,而是直接从本地的
磁盘中取出,这样不仅可以减少网络的数据传输,而且可以提高浏览器的相应速
度,给用户很好的用户体验。
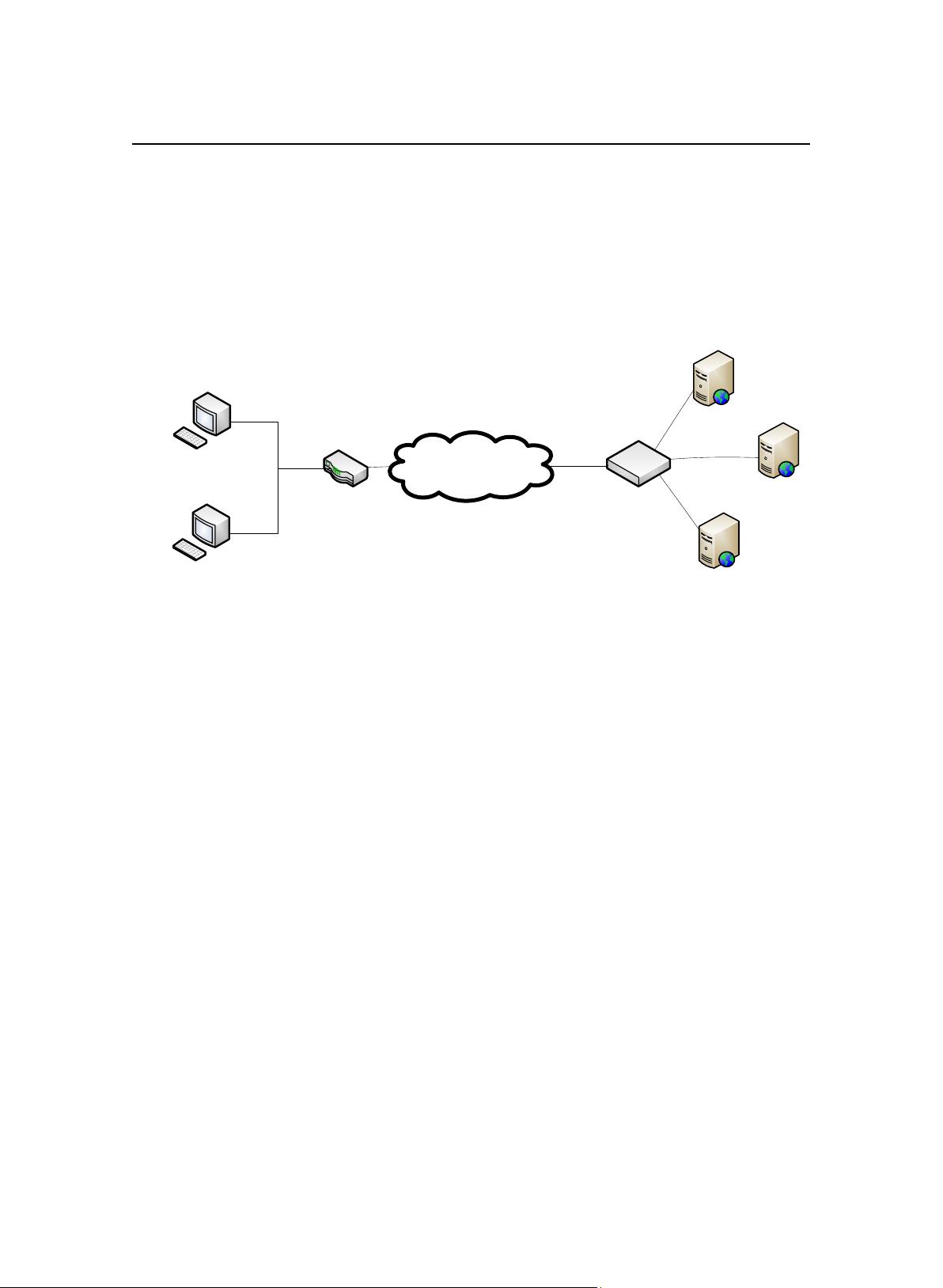
2.3.2 代理缓存
代理缓存指的是可以代理用户向服务器端发送请求的这样一种缓存服务器
[16]
。用户不需要直接与 Web 服务器进行通信。它先将数据发往代理缓存服务器查
万方数据

剩余93页未读,继续阅读
2021-08-08 上传
2021-09-14 上传
289 浏览量
2023-07-30 上传
2023-07-23 上传
2023-05-02 上传
2023-09-11 上传
2024-11-04 上传
2023-08-28 上传
2023-07-14 上传

programmh
- 粉丝: 4
- 资源: 2162
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
