SQL Server 2000下的存储过程自动化生成与模块化设计
版权申诉
61 浏览量
更新于2024-07-03
收藏 110KB DOC 举报
在数据库管理中,自动化存储过程的生成是一项关键的技术,特别是在大型SQL项目中,它能够显著提高开发效率并确保代码的一致性和可维护性。本文主要关注如何通过设计时的存储过程来自动化创建运行时的存储过程,特别是在SQL Server 2000及其后续版本中的应用。
在早期的一个多层客户/服务器项目中,开发团队面临着编写大量针对不同表的select、insert、update和delete操作存储过程的任务。由于每张表的独特性,比如唯一索引列的不同,手动编写这些存储过程既耗时又容易出错。为了解决这个问题,他们开发了一套设计时的核心存储过程,这些过程能根据数据库表的结构自动生成相应的运行时存储过程。这种方法不仅减少了重复劳动,节省了时间和成本,而且生成的代码质量高,符合一致的命名规范。
在SQL Server 2000引入用户定义函数(UDFs)之后,这些设计时存储过程进一步得到了升级。利用UDFs,代码变得更加模块化,使得处理复杂逻辑或通用任务更加灵活。存储过程的命名规则也变得标准化,例如prApp_TableName_Task的形式,其中Table是表名,Task指明操作类型(如Select、Insert、Update或Delete)。这种命名规范有助于快速识别存储过程的功能,提高了代码的可读性和可维护性。
例如,在实际应用中,对于Customers和Orders表,生成的存储过程名称分别为prApp_Customers_Delete、prApp_Customers_Insert等,这样的命名规则为数据库提供了清晰的层次结构和组织,极大地提升了数据库管理的效率和整洁度。
总结来说,数据库中存储过程的自动化生成是一种强大的工具,它通过设计时的存储过程模板,实现了运行时存储过程的快速生成,优化了编码流程,确保了代码一致性,并提高了整体项目的开发效率和代码质量。随着技术的发展,如SQL Server 2000引入的用户定义函数,自动化生成的过程变得更加灵活和高效。这一实践对于现代数据库运维和项目开发具有重要的指导意义。
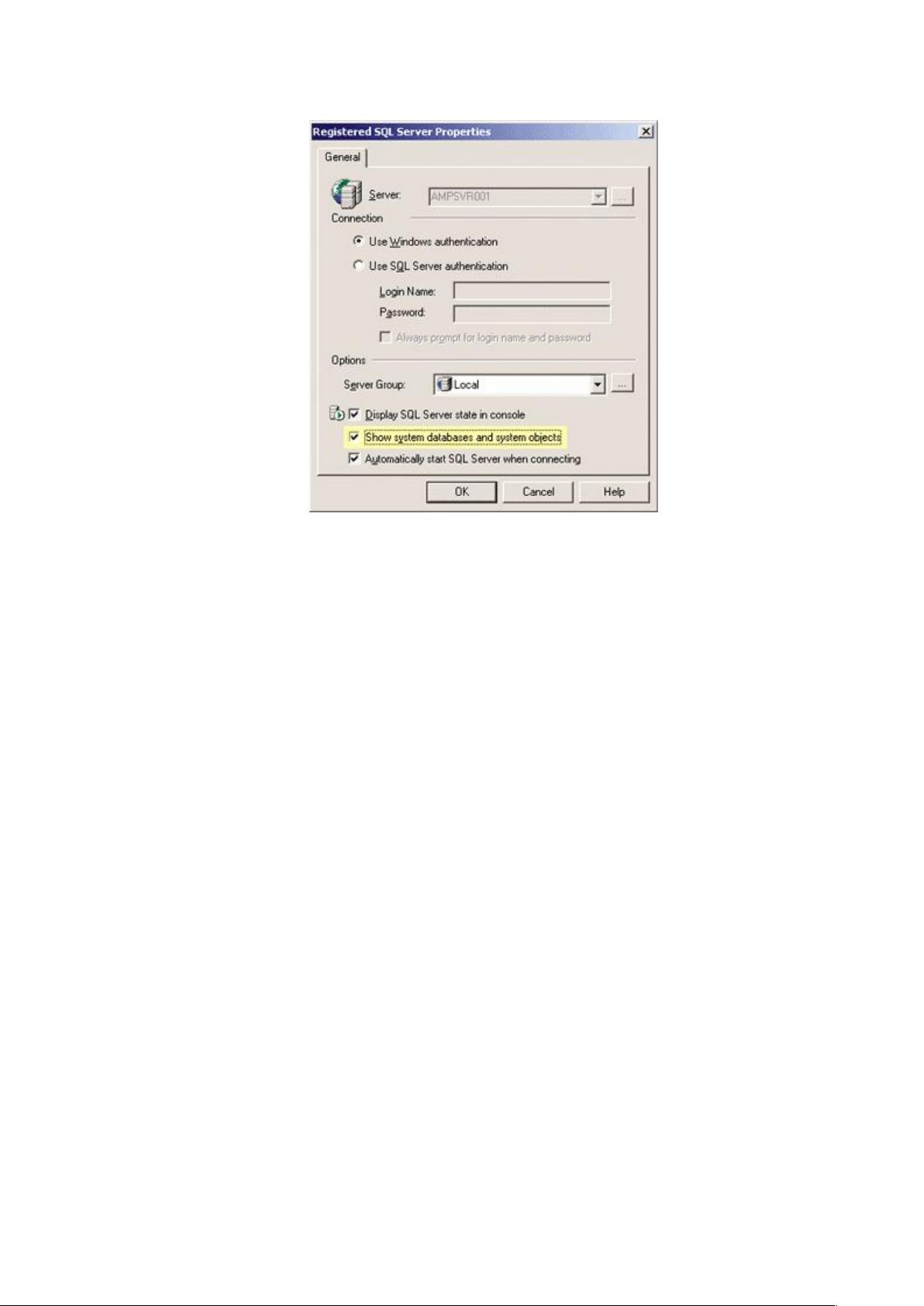
Figure 2 View System Tables
了解通过修改注册服务器的属性,SQL Server 企业管理器能使你查看系统表是非
常有用的,如 Figure 2 所示。如果你在企业管理器中右键单击服务器名字,并选择“Edit
SQL Server Registration properties”,将弹出一个对话框。在对话框的下面,你可以看
到一个标有“Show system databases and system objects” 的复选框。选中这个选项便打
开了系统对象视图,也可以选择关闭来使表的视图看起来更简单和更易读。
解析表列
Syscolumns 表提供了许多必须的元数据信息,例如列名、ID、长度和是否允许空
值。它还被用来连接 sysindexes 表来确定表的主键。同样可以通过
INFORMATION_SCHEMA.COLUMNS 视图获取列的默认值。
既然所有的存储过程都使用相同的元数据信息,那么出于模块化和可维护性考虑,
将其封装在独立的代码块中是件非常好的事情。SQL Server 的早期版本没有 UDF(用
户定义函数),使得模块化看起来很困难。但是 SQL Server 2000 具备了 UDF 特性,
我们决定进一步采用该代码并将四个设计时存储过程中的公共特性进行模块化。创建五
个新的 UDFs 来处理系统表和信息大纲视图,封装所有取得的元数据。
毫无疑问,为了创建新的运行时存储过程,我们需要知道下面的关于表的元数据列
信息:
列名
列的 ID 号
列的数据类型
4
剩余15页未读,继续阅读
2022-07-06 上传
2022-06-05 上传
2023-05-24 上传
2023-06-15 上传
2023-05-21 上传
2023-05-26 上传
2023-07-02 上传
2024-09-24 上传
2023-05-05 上传

老帽爬新坡
- 粉丝: 92
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 磁性吸附笔筒设计创新,行业文档精选
- Java Swing实现的俄罗斯方块游戏代码分享
- 骨折生长的二维与三维模型比较分析
- 水彩花卉与羽毛无缝背景矢量素材
- 设计一种高效的袋料分离装置
- 探索4.20图包.zip的奥秘
- RabbitMQ 3.7.x延时消息交换插件安装与操作指南
- 解决NLTK下载停用词失败的问题
- 多系统平台的并行处理技术研究
- Jekyll项目实战:网页设计作业的入门练习
- discord.js v13按钮分页包实现教程与应用
- SpringBoot与Uniapp结合开发短视频APP实战教程
- Tensorflow学习笔记深度解析:人工智能实践指南
- 无服务器部署管理器:防止错误部署AWS帐户
- 医疗图标矢量素材合集:扁平风格16图标(PNG/EPS/PSD)
- 人工智能基础课程汇报PPT模板下载
