58集团实战分享:Apache Kylin在大数据分析中的应用与权限管理
需积分: 9 53 浏览量
更新于2024-07-17
收藏 26.79MB PDF 举报
"《Apache Kylin在58集团的实践与应用》是一份PPT,介绍了该企业如何在日常运营中利用Kylin(一个开源的分布式数据仓库工具)进行数据处理和分析。Kylin在58集团的应用涉及到了多个关键组件和操作流程,包括Hadoop、Hive、YARN队列、HBase以及安全设置。
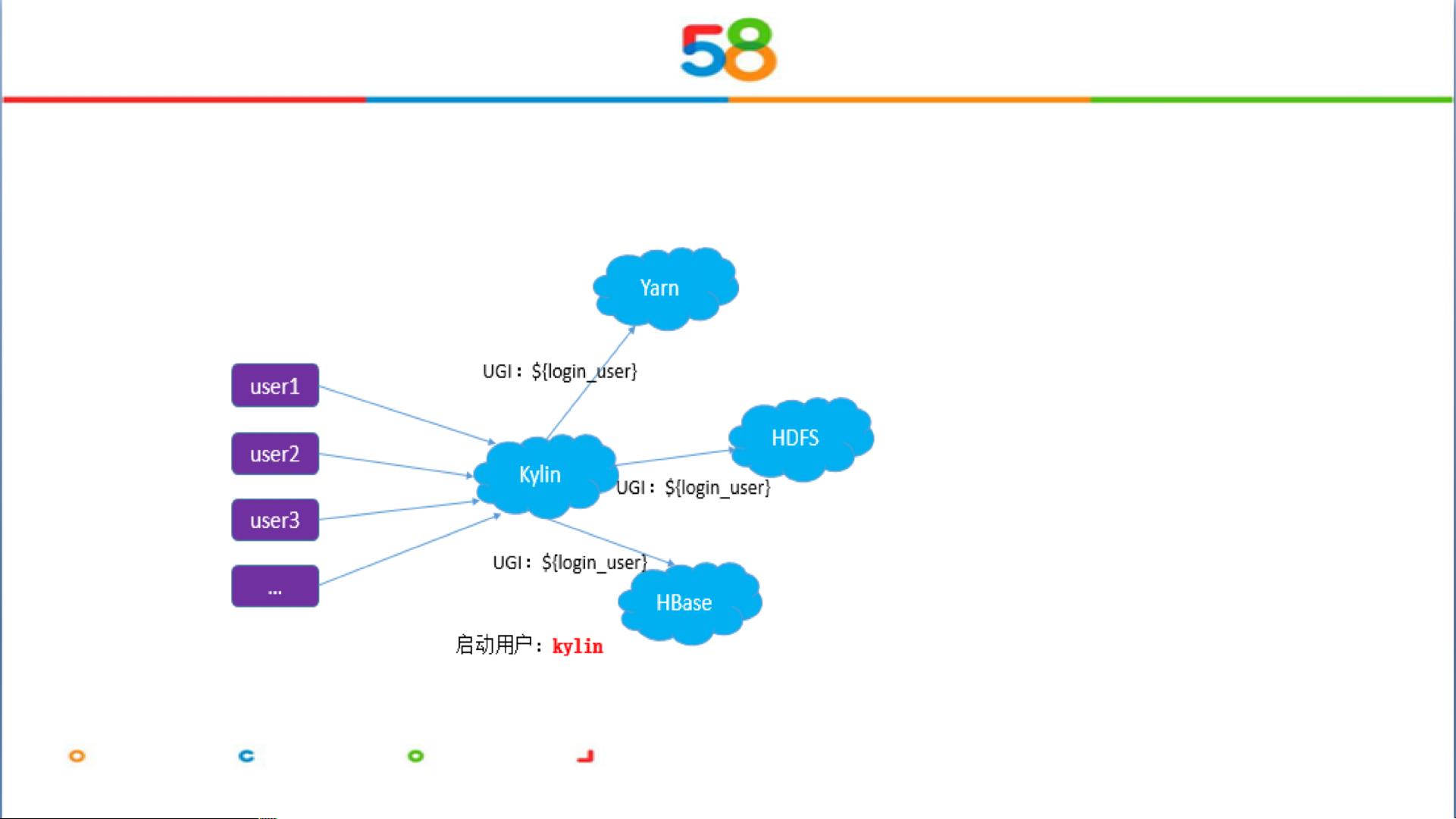
1. 实践背景:Kylin在58集团被用于支持大数据分析,提高决策支持的效率。通过创建命名空间和权限管理,如为Hadoop用户分配适当的读写权限,确保数据的安全性。
2. 数据集成:Kylin与Hive集成,通过HiveQL进行数据查询,同时通过YARN队列进行资源调度,实现了高效的数据处理。
3. 数据建模:Kylin立方体(Cube)的设计是核心环节,l
Kylin等步骤可能涉及到创建和维护这些预计算的数据结构,以便于快速查询。
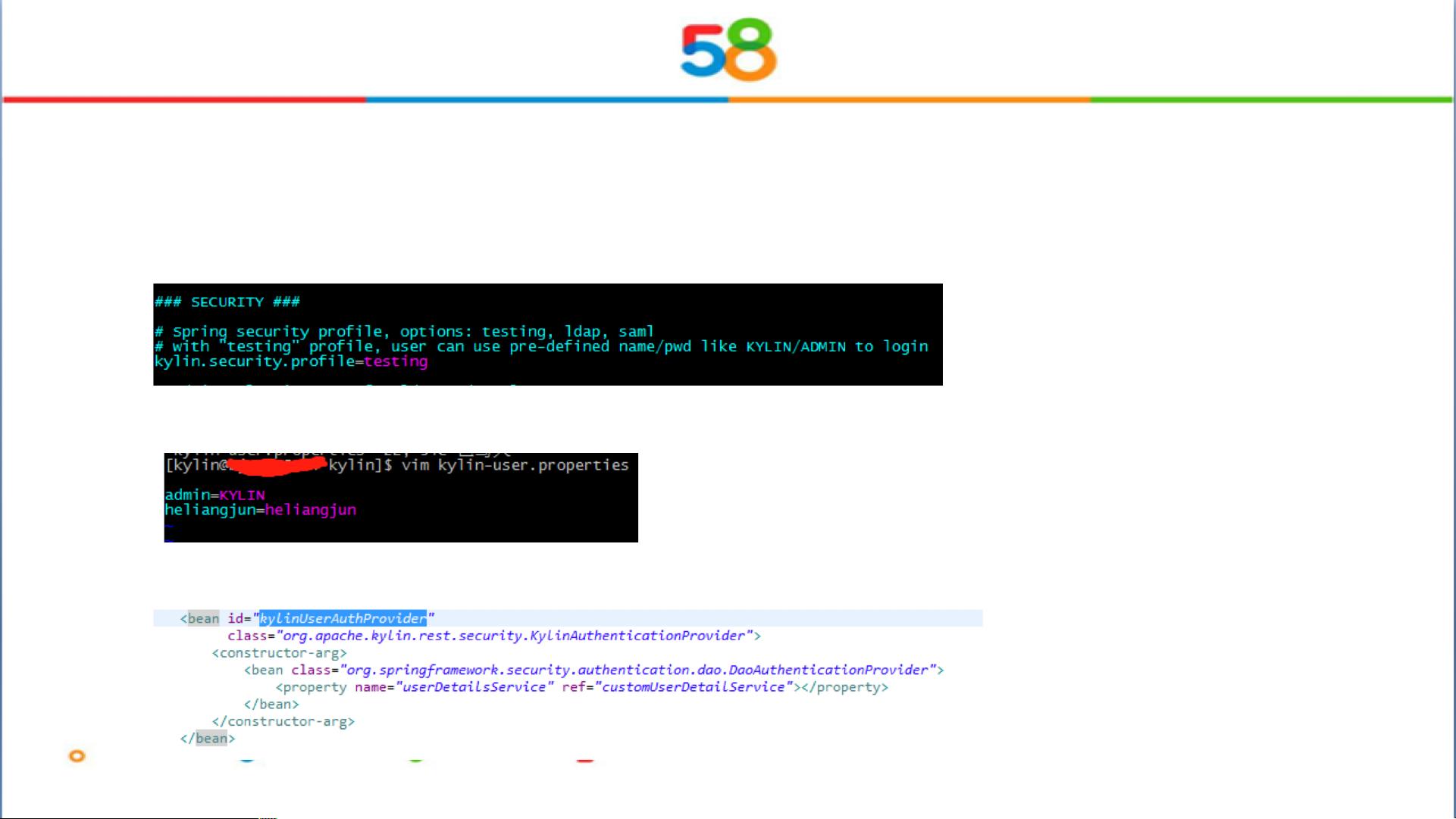
4. 安全性:文档提到设置测试模式的安全配置(`kylin.security.profile=testing`),并且强调了登录用户的权限管理和代理用户设置。
5. 其他组件:HBase作为NoSQL数据库,与Kylin一起构建了一个完整的数据架构,通过HBaseConnection的缓存和UGI对象实现连接管理。
6. 应用实例:文档还提到了具体的操作示例,如`l
cubeUbuild`可能是在构建和刷新立方体的过程,而`T@+TKylinhX`可能是与Kylin的API交互或数据导出。
7. 结合其他系统:Kylin不仅局限于数据仓库,还与其他系统如HDFS(存储)、HBase(存储)和MR(MapReduce)紧密协作,共同构建了一套完整的大数据处理环境。
通过这份PPT,读者可以了解到58集团如何将Apache Kylin融入其业务流程中,优化数据处理性能,支持关键业务决策。这份资料对于理解大型企业级数据分析平台的实践应用具有很高的参考价值。"
7
1
剩余37页未读,继续阅读
2022-02-25 上传
2019-07-17 上传
2019-07-18 上传
2023-10-24 上传
2018-11-20 上传
2020-06-04 上传
2021-11-16 上传


ZHAOYONG719
- 粉丝: 0
- 资源: 32
 我的内容管理
展开
我的内容管理
展开







最新资源
- Cree的管子模型CGH系列全套
- 测试ASP.NET应用程序
- Login,查看java源码,java数组
- TellkiAgent_OSXMemory
- Android *应用程序的性能评估
- love:爱心树表白网页原始码,jquery女神表白动画树特效
- 模块5解决方案
- kaguya-reread
- TESTSYM,java项目源码分享网,java运动
- algoritmos-caso3
- 法新社2
- ByWebView:WebView全方面使用,JS交互,进度条,上传图片,错误页面,视频全屏播放,唤起原生App,获取网页源代码,被作为第三方浏览器打开,DeepLink,[腾讯x5使用示例]
- Hibernate,java项目实例源码,javaweb大作业
- Soundloud - Soundcloud To Mp3-crx插件
- 大型高温浓硫酸液下泵的设计与使用.rar
- interesting-js:一些有趣的js
