Hadoop Hive性能优化深度解析
需积分: 9 182 浏览量
更新于2024-07-23
收藏 3.96MB PDF 举报
“王家林hive调优 - 本文由 Hortonworks, Inc. 创作,遵循 Creative Commons Attribution-ShareAlike 3.0 Unported 许可协议,内容涵盖Hive在大数据处理中的应用、Hive架构、性能优化、数据输入输出、安全性和Project Stinger等。”
在大数据处理领域,Hive作为一款基于Hadoop的数据仓库工具,被广泛用于对大规模数据集进行结构化查询和分析。王家林的文章详细探讨了如何进行Hive调优,使得在处理海量数据时能提升效率。以下是文章中涉及的关键知识点:
1. **Hive的作用**
Hive的主要目标是提供一种方法,使非编程背景的用户可以使用SQL语言对存储在Hadoop集群中的大量数据进行分析。它支持对各种类型的数据(如传感器数据、移动数据、网络日志和运营数据)进行处理,并且可以与现有的SQL工具和流程无缝集成。
2. **Hive的架构与SQL兼容性**
Hive通过将SQL查询转换为MapReduce任务来实现对Hadoop的分布式处理。它的架构设计允许扩展到非常大的规模,同时提供了与传统SQL的兼容性,使得用户无需学习新的查询语言即可操作大数据。
3. **Hive性能优化**
- **元数据管理**:优化元数据存储,减少元数据查找的时间。
- **分区和桶表**:通过对数据进行分区和桶划分,可以显著提高查询效率,尤其是针对有特定条件的过滤查询。
- **压缩**:使用适当的压缩算法可以减小数据存储量,加快读取速度。
- **减少数据倾斜**:避免数据分布不均导致某些节点负载过重。
- **选择合适的执行引擎**:Tez或Spark可以提供比MapReduce更高的性能。
- **JOIN操作优化**:避免全表JOIN,利用分区JOIN或Broadcast JOIN提升效率。
- **使用物化视图**:预先计算和存储复杂查询结果,提高查询速度。
4. **数据输入和输出**
Hive支持多种数据加载方式,如LOAD DATA、INSERT OVERWRITE等,以及使用Hive的外部表功能进行灵活的数据导入导出。同时,Hive还可以与其他数据源(如HDFS、HBase等)集成,实现数据的实时交换。
5. **Hive安全**
Hive支持多种安全机制,如Hadoop的HDFS权限控制、Hive的元数据权限管理以及Kerberos认证,确保数据的安全访问和操作。
6. **Project Stinger**
Project Stinger是Hive的一个改进计划,旨在将Hive的查询性能提升100倍,通过引入更高效的执行引擎、优化编译器和内存管理策略,以适应实时分析的需求。
7. **与流行工具的连接**
Hive可以与多种工具集成,如Hue、Tableau、Excel等,提供友好的交互界面,使得数据分析人员能够方便地进行数据探索和报表生成。
王家林的文章详细介绍了Hive在大数据环境下的工作原理、性能调优策略以及与Hadoop生态系统的整合,对于理解和提升Hive在实际项目中的使用效果具有很高的指导价值。
Deep Dive content by Hortonworks, Inc. is licensed under a
Creative Commons Attribution-ShareAlike 3.0 Unported License.
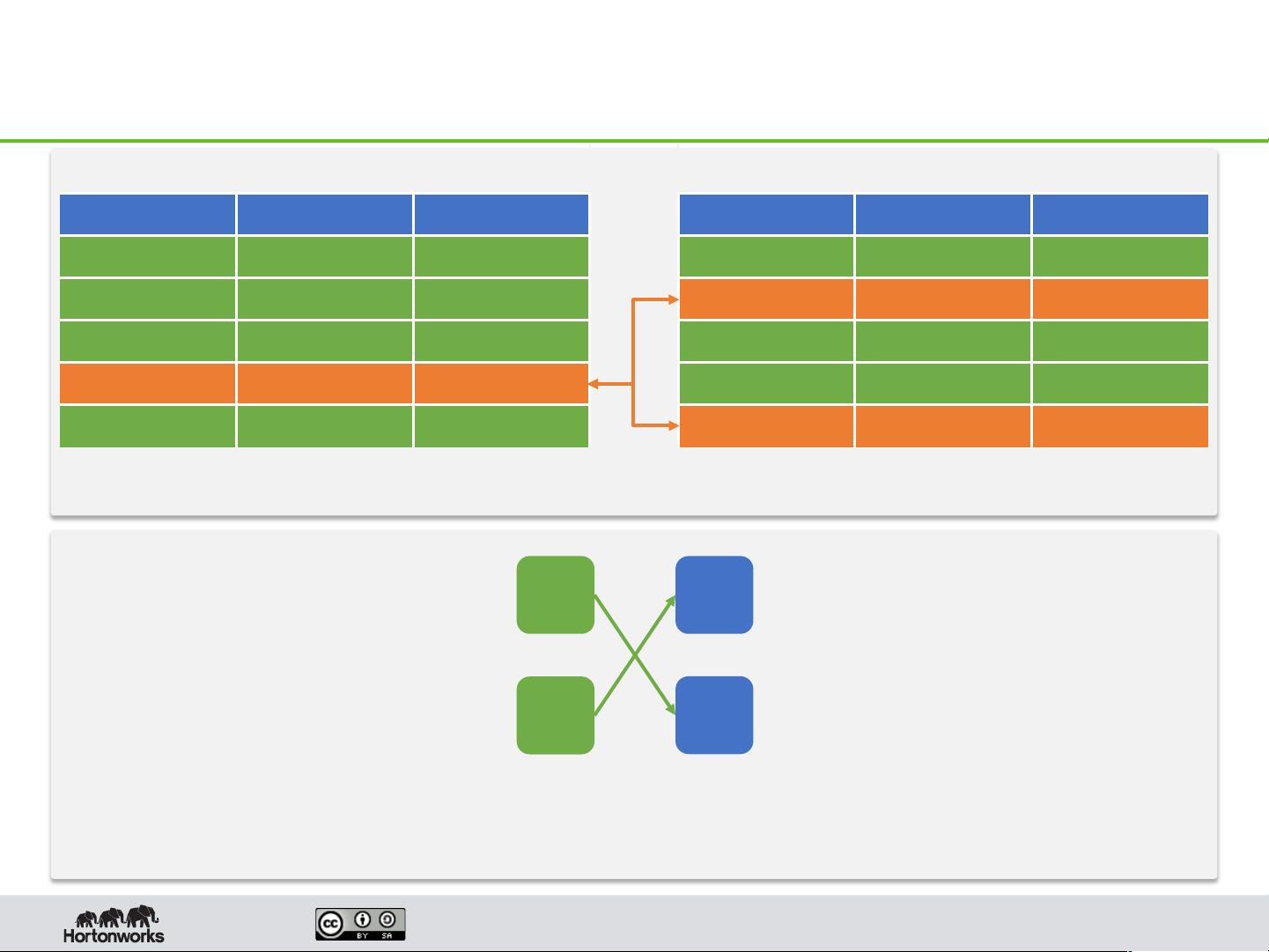
Shuffle Joins in Map Reduce
Page 15
;+3"#@%$& #$)%$&
A$3"& -'3"& /)& ;/)& ?$/;%& B+'(6",&
>*9_' ?%#"&' ^^`^^' a^bN' ^N:bN' c'
["$$*"' !*B%#@$' ^^`^M' ^^`^a' ^M:Mb' Md'
\0$*' 50B"&$' ^^`^c' ca`^' b:``' b'
D%@-"&' T+0=7%#' ^^`^a' M`ca' c`:``' MM'
Z"&%#0' Y%++"#' ^^`^b' ^^`^a' aN:bN' ^N'
SELECT&*&FROM&customer&join&order&ON#customer.id#=#order.cid;&
M
j'*@k'^^`^^A'j'h&$7k'>*9_A'+0$7k'?%#"&'ll'
j'*@k'^^`^aA'j'h&$7k'D%@-"&A'+0$7k'T+0=7%#'ll'
m'
M
j'9*@k'a^bNA'j'/&*9"k'^N:bNA'U<0#17=k'c'll'
j'9*@k'^^`^aA'j'/&*9"k'^M:MbA'U<0#17=k'Md'll'
m'
R
j'*@k'^^`^aA'j'h&$7k'D%@-"&A'+0$7k'T+0=7%#'ll'
j'9*@k'^^`^aA'j'/&*9"k'^M:MbA'U<0#17=k'Md'll'
R
j'*@k'^^`^^A'j'h&$7k'>*9_A'+0$7k'?%#"&'ll'
j'9*@k'a^bNA'j'/&*9"k'^N:bNA'U<0#17=k'c'll'
m'
6@"#190+'_"=$'$L<e"@'7%'7L"'$0B"'&"@<9"&:'[%*#'@%#"'&"@<9"E$*@":'
CX/"#$*F"'8&%B'0'#"7P%&_'<1+*g01%#'$70#@/%*#7:'



剩余90页未读,继续阅读
2017-12-19 上传
104 浏览量
440 浏览量
2023-07-27 上传
2023-05-27 上传
2023-05-05 上传
2013-03-20 上传
2013-03-20 上传









