深度跨模态对齐:多镜头行人重识别技术
135 浏览量
更新于2024-08-31
收藏 1.34MB PDF 举报
"深度跨模态对齐用于多镜头行人重识别"
在计算机视觉领域,行人重识别(Person Re-Identification,简称Re-ID)是一项重要的任务,它涉及到在不同摄像头视角下识别同一行人的能力。随着技术的发展,多镜头行人重识别(Multi-Shot Re-ID)越来越受到关注,因为它更贴近实际应用场景。相比于单镜头Re-ID,多镜头设置提供了更多的观察样本,有助于提高识别的准确性。
尽管已有大量单镜头Re-ID的人像图像数据集发布,但现有的多镜头Re-ID视频序列数据集却相对较小,通常只包含数百个行人实例。这种数据量的局限性限制了多镜头Re-ID性能的进一步提升。为解决这个问题,研究者们提出了一种深度跨模态对齐网络(Deep Cross-Modality Alignment Network),旨在同时利用人类序列对和图像对来促进更好的多镜头行人重识别模型的训练。
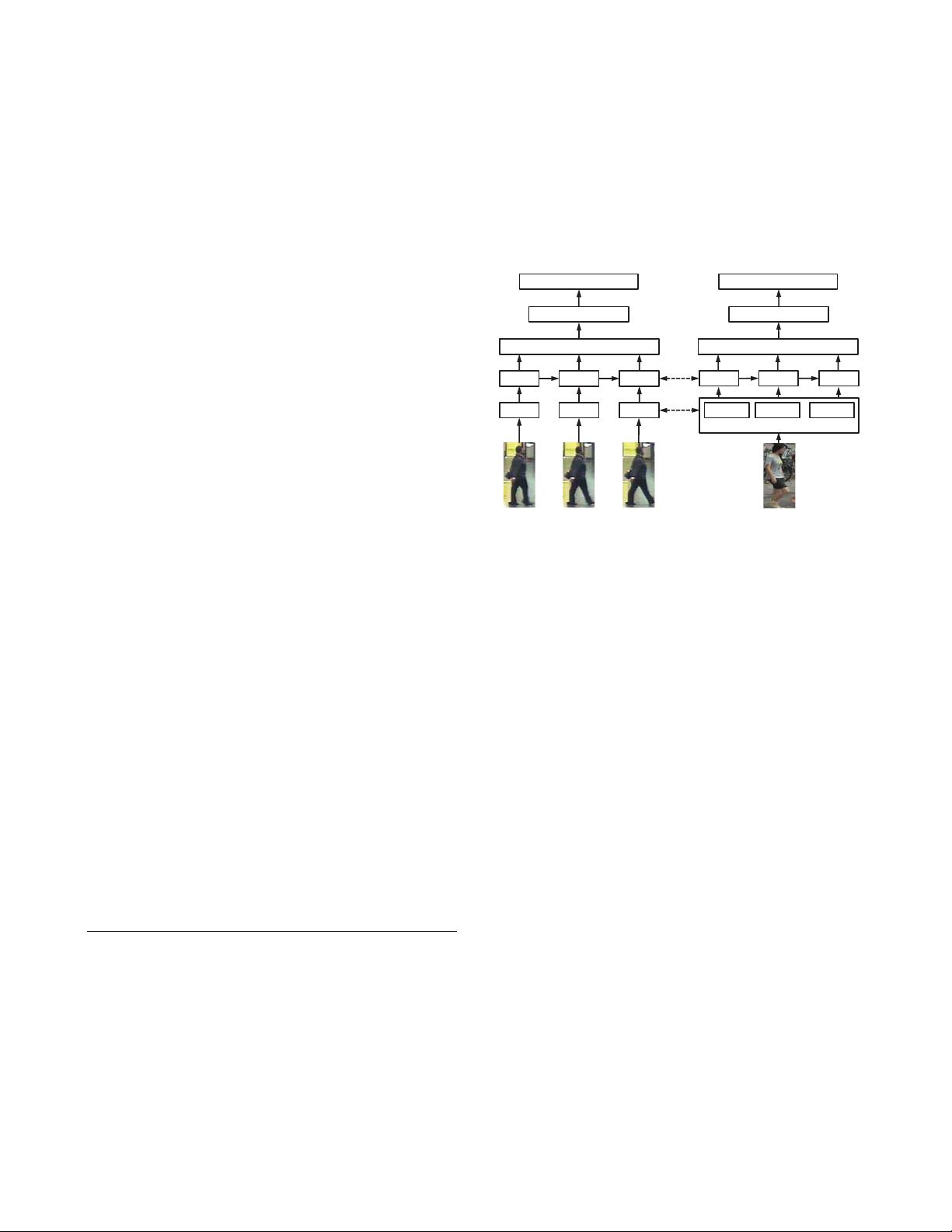
该网络的核心在于一个称为跨模态对齐子模块(Cross-Modality Alignment Sub-module)的图像到序列适应模块。这个模块主要针对图像数据与序列数据之间的模态不匹配问题。模态不匹配是由于图像数据和视频序列数据在表示方式上的差异,例如图像是一帧静态画面,而序列则包含连续的时间信息。通过这个子模块,网络能够学习如何在两种不同模态之间有效地转移知识,从而改善模型在处理多镜头数据时的性能。
具体来说,深度跨模态对齐网络首先通过提取图像和序列中的特征,然后通过跨模态对齐子模块进行对齐,使得来自不同模态的数据在特征空间中能有相似的表示。这有助于网络学习到更为通用且适应性强的特征,即使在面对新的或复杂的环境变化时,也能保持较高的识别准确率。
此外,为了优化模型训练,该网络可能采用了端到端的学习策略,结合了监督学习和无监督学习的元素,比如利用已知的行人配对信息进行有监督学习,同时通过无监督的方式让模型自行发现潜在的相关性。这样的设计可以充分利用有限的标注数据,同时挖掘出未标记数据的潜在价值。
这篇研究论文深入探讨了多镜头行人重识别的挑战,并提出了一种创新的解决方案——深度跨模态对齐网络。这种方法不仅解决了模态差异问题,还提升了模型在大规模多镜头数据集上的表现,为行人重识别技术的进步做出了重要贡献。未来的研究可能会在这个基础上进一步优化,例如探索更多模态的数据融合,或者改进对动态行为的理解,以实现更精确的行人识别。
Deep Cross-Modality Alignment for Multi-Shot Person
Re-IDentification
Zhichao Song, Bingbing Ni, Yichao Yan, Zhe Ren, Yi Xu, Xiaokang Yang
Shanghai Jiao Tong University
{5110309394,nibingbing,yanyichao,sunshinezhe,xuyi,xkyang}@sjtu.edu.cn
ABSTRACT
Multi-shot person Re-IDentification (Re-ID) has recently re-
ceived more research attention as its problem setting is more
realistic compared to single-shot Re-ID in terms of applica-
tion. While many large-scale single-shot Re-ID human image
datasets have been released, most existing multi-shot Re-ID
video sequence datasets contain only a few (i.e., several hun-
dreds) human instances, which hinders further improvement
of multi-shot Re-ID performance. To this end, we propose
a deep cross-modality alignment network, which jointly ex-
plores both human sequence pairs and image pairs to facili-
tate training better multi-shot human Re-ID models, i.e., via
transferring knowledge from image data to sequence data. To
mitigate modality-to-modality mismatch issue, the proposed
network is equipped with an image-to-sequence adaption
module called cross-modality alignment sub-network, which
successfully maps each human image into a pseudo human
sequence to facilitate knowledge transferring and joint train-
ing. Extensive experimental results on several multi-shot
person Re-ID benchmarks demonstrate great performance
gain brought up by the proposed network.
KEYWORDS
person Re-ID, cross-modality alignment network, knowledge
transferring
ACM Reference Format:
Zhichao Song, Bingbing Ni, Yichao Yan, Zhe Ren, Yi Xu, Xiaokang
Yang. 2017. Deep Cross-Mo dality Alignment for Multi-Shot Person
Re-IDentification. In Proceedings of MM ’17, Mountain View, CA,
USA, October 23–27, 2017, 9 pages.
https://doi.org/10.1145/3123266.3123324
1 INTRODUCTION
Multi-shot person Re-ID is an important problem in video
surveillance. Compared with traditional single-shot person
Re-ID, the problem setting of multi-shot person Re-ID is
closer to real-world application, i.e., in surveillance, usually a
Permission to make digital or hard copies of all or part of this work
for personal or classroom use is granted without fee provided that
copies are not made or distributed for profit or commercial advantage
and that copies bear this notice and the full citation on the first
page. Copyrights for components of this work owned by others than
ACM must be honored. Abstracting with credit is permitted. To copy
otherwise, or republish, to post on servers or to redistribute to lists,
requires prior specific permission and/or a fee. Request permissions
from permissions@acm.org.
MM ’17, October 23–27, 2017, Mountain View, CA, USA
© 2017 Association for Computing Machinery.
ACM ISBN 978-1-4503-4906-2/17/10. . . $15.00
https://doi.org/10.1145/3123266.3123324
CNN
Temporal Pooling
RNN
CNN
RNN
CNN
RNN
RNN
RNN
RNN
CGMCNN
Temporal Pooling
Sequence Feature Sequence Feature
Cross-Modality Alignment Network
Video Sequence Loss Pseudo Sequence Loss
Shared
Weights
MGM
Video Sequence
Single Image
Figure 1: Pipeline of our proposed network. The in-
put data includes two parts: the video sequence and
the single image. The single image gets though the
cross-modality alignment network to produce a pseu-
do sequence. Both types of data go through the par-
allel sub-network which contains CNNs and RNNs.
Finally, video sequence and pseudo sequence com-
pute their loss value independently.
video sequence of human is observable, instead of a snapshot
of this person. There exist several datasets for multi-shot
person Re-ID, however, most of them have only hundreds of
video sequences, which is far from sufficient for training a high
performance multi-shot person Re-ID model. For example,
the well-known iLIDS-VID dataset [
29
] contains 600 image
sequences for 300 people. The PRID 2011 dataset [
11
] includes
400 image sequences for 200 people.
While lack of multi-shot person Re-ID data, there exist
many large-scale single-shot person Re-ID datasets. For exam-
ple, the CUHK03 dataset [
15
] contains 1467 human identities.
Similarly, the Market-1501 dataset [
34
] contains 32668 bound-
ing boxes of 1501 human identities. Therefore, it is natural
to ask the following question: whether we can utilize these
rich image data to facilitate better sequence based multi-shot
person Re-ID algorithm training? In other words, whether
we can transfer the knowledge obtained from image dataset
to sequence dataset?
A typical way of performing cross-modality knowledge
transfer in deep learning is the DeepID face verification
pipeline [
28
]: first pre-train deep CNN model based on a
human classification dataset, which contains a large number
Session: Fast Forward 3
MM’17, October 23–27, 2017, Mountain View, CA, USA
645
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-06 上传
2019-08-17 上传
2023-03-30 上传
2020-12-05 上传
2022-02-05 上传
2021-01-23 上传

皮卡丘穿皮裤
- 粉丝: 187
- 资源: 955
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
