HBase架构与模式设计
需积分: 10 49 浏览量
更新于2024-07-21
收藏 13.61MB PDF 举报
“HBASE schema design - PPT by Lars George,探讨了HBase的架构和设计,适合NoSQL领域的学习者,由Cloudera主办。”
在深入理解HBase的架构和设计之前,首先需要知道HBase是什么。HBase是一个分布式的、基于列族的NoSQL数据库,它构建于Hadoop文件系统(HDFS)之上,提供了高并发、低延迟的数据存储。HBase的设计目标是支持大规模数据的实时查询,尤其适用于大数据分析场景。
**HBase架构**
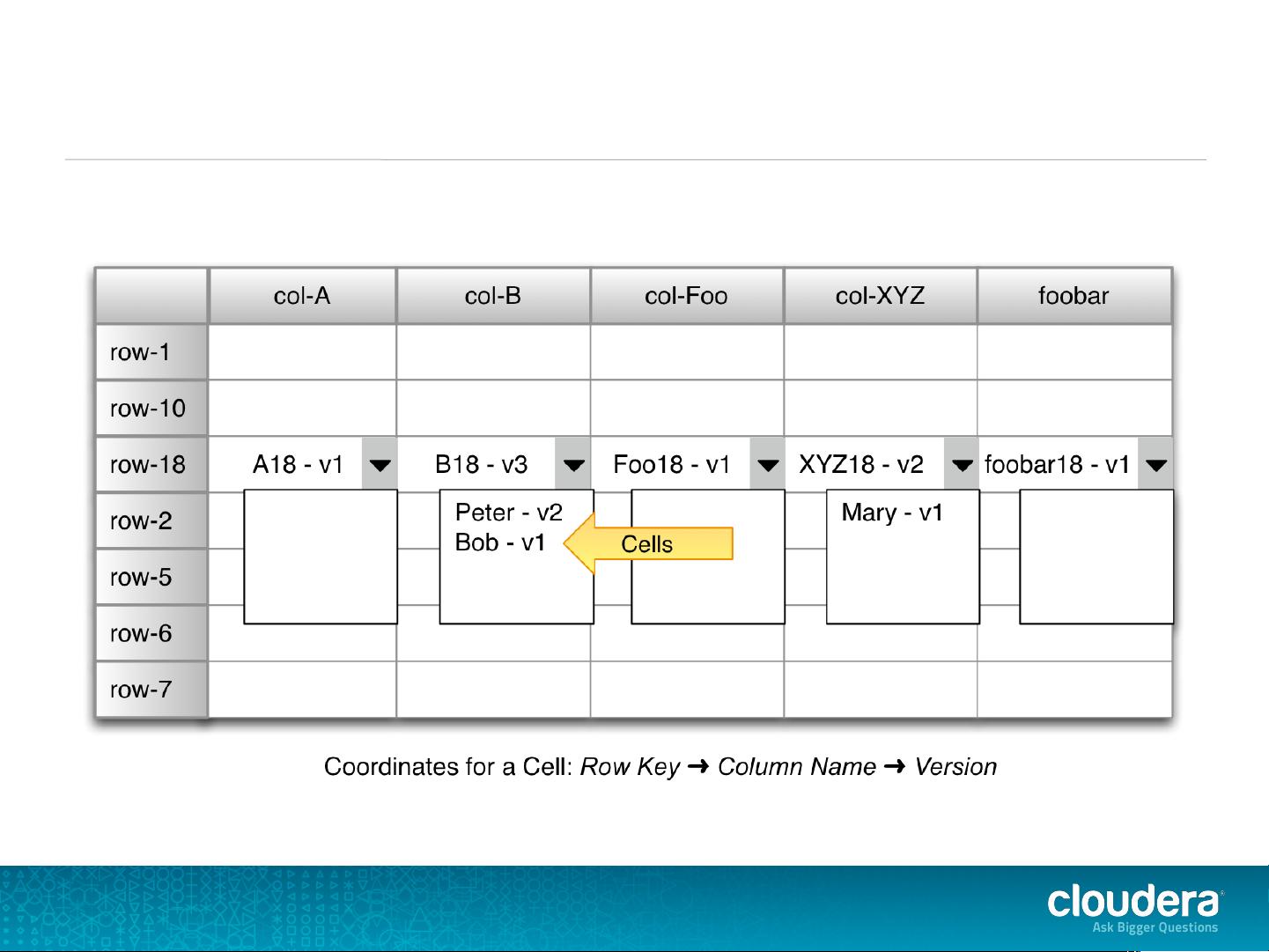
HBase的架构核心包括Master节点、RegionServer节点和表的Region。Master节点负责全局的表和Region管理,如分配和迁移Region,处理RegionServer的故障检测等。RegionServer则实际存储和处理数据,每个RegionServer可以管理多个Region。
- **Region**:是HBase数据存储的基本单位,一个表可以被划分为多个Region。Region由起始键(startKey)和结束键(endKey)定义,这些键是行键的一部分。Region会随着数据的增长而分裂,确保单个Region不会过大,以维持高效的服务。
- **Table**:表是由多个Region组成的,每个Region都有自己的startKey和endKey,使得数据可以根据行键有序地分布在不同的Region中。新插入的数据会自动被分配到合适的Region。
**HBase Schema Design**
HBase的模式设计不同于传统的关系型数据库。它主要关注列族(Column Family)和列(Column)的概念。列族是一组具有相同前缀的列集合,预先定义,而在列族内部,列可以在运行时动态添加。
- **列族**:列族是数据存储的主要容器,每个列族包含一组列,列族内的列可以是任意多的,列名由列族名和列限定符组成,如`cf:qualifier`。
- **列**:列是数据的最小存储单元,由列族和列限定符共同定义。列可以按需创建,无需预先定义,这为灵活性提供了支持。
在设计HBase schema时,需要考虑以下几点:
1. **列族选择**:根据数据的访问模式和大小选择合适的列族数量。如果数据是稀疏的,可能只需要一个列族;如果是密集的,可能需要多个列族来优化存储和访问。
2. **预分区**:通过预分区,可以提前规划Region的分布,避免数据不均匀分布导致的热点问题。
3. **时间戳**:所有HBase的写操作都会带有时间戳,允许存储多版本的数据,便于实现历史数据的追踪和查询。
4. **数据压缩**:启用列族级别的数据压缩,可以减少存储空间,提高读写性能。
5. **索引设计**:HBase原生不支持二级索引,但可以通过外部索引服务或自定义逻辑实现索引功能,以加速查询。
**总结**
HBase的架构设计和模式设计是其能够处理大规模数据并提供高性能的关键。理解这些概念对于有效地利用HBase进行大数据存储和查询至关重要。正确设计HBase的schema可以显著提高系统的效率和可扩展性,同时降低运维复杂性。在实践中,应根据具体业务需求进行灵活调整和优化。
!"#$%&Q#?8%$&

剩余41页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-05-09 上传
2009-12-30 上传
2014-08-25 上传
2017-12-03 上传
2013-11-19 上传
2019-04-08 上传

LifeBigData
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
