集成学习提升Amazon评论质量预测:实战 Bagging与AdaBoost.M1
需积分: 0 143 浏览量
更新于2024-06-26
收藏 1.63MB PDF 举报
"Exp6: 集成学习在Amazon用户评论质量预测中的应用探究"
在这个实验中,我们探讨了如何利用集成学习技术提升Amazon电商平台的用户评论质量评估准确性。随着电子商务的发展和消费者依赖度增强,保证评论的真实性和价值对于商家与消费者来说至关重要。案例的关键任务是通过两种集成学习方法——Bagging和AdaBoost.M1,结合SVM和决策树这两种基分类器,来预测评论的质量。实验的核心目标是对比这些组合的性能,使用AUC(Area Under the Curve)作为评估指标。
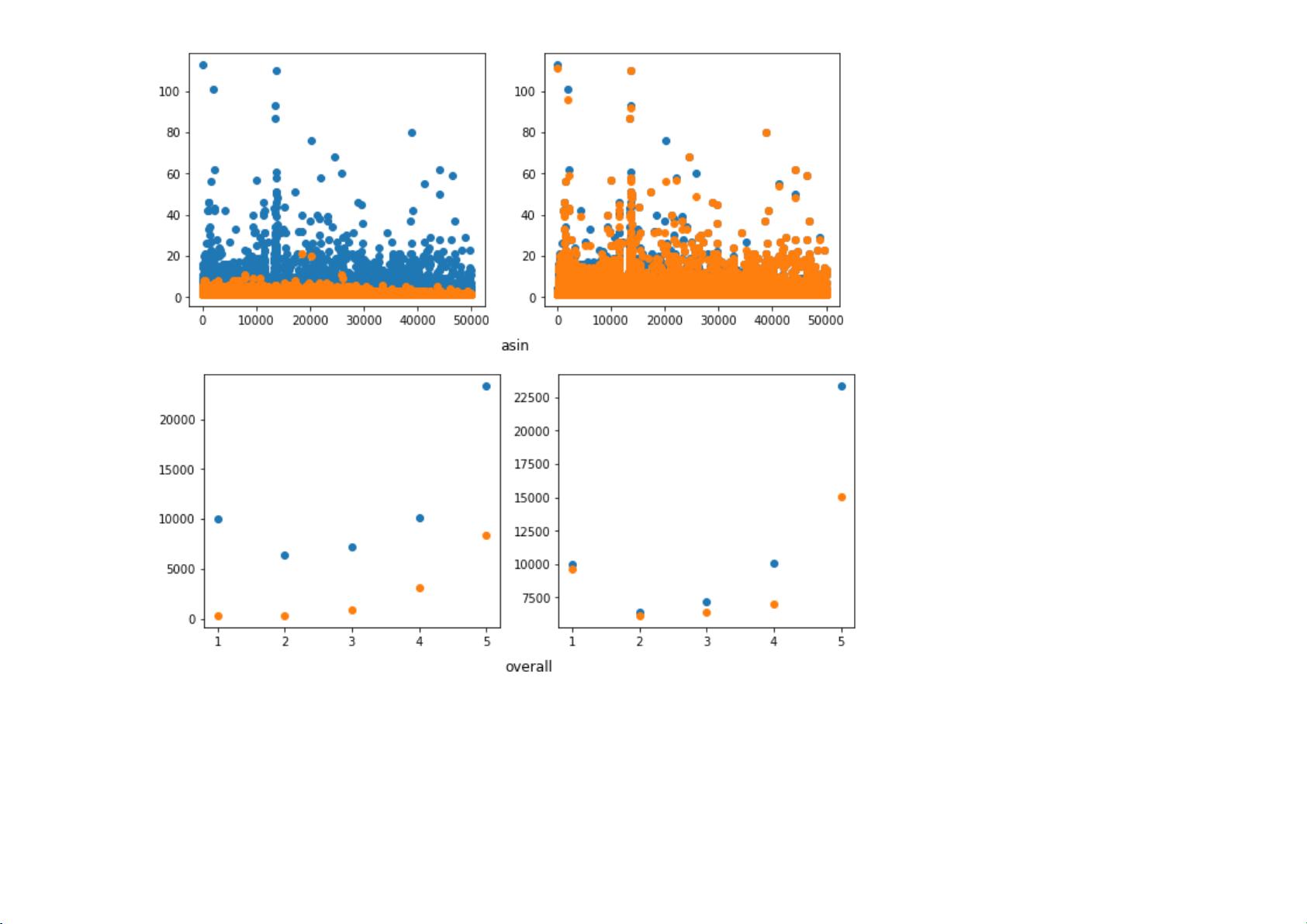
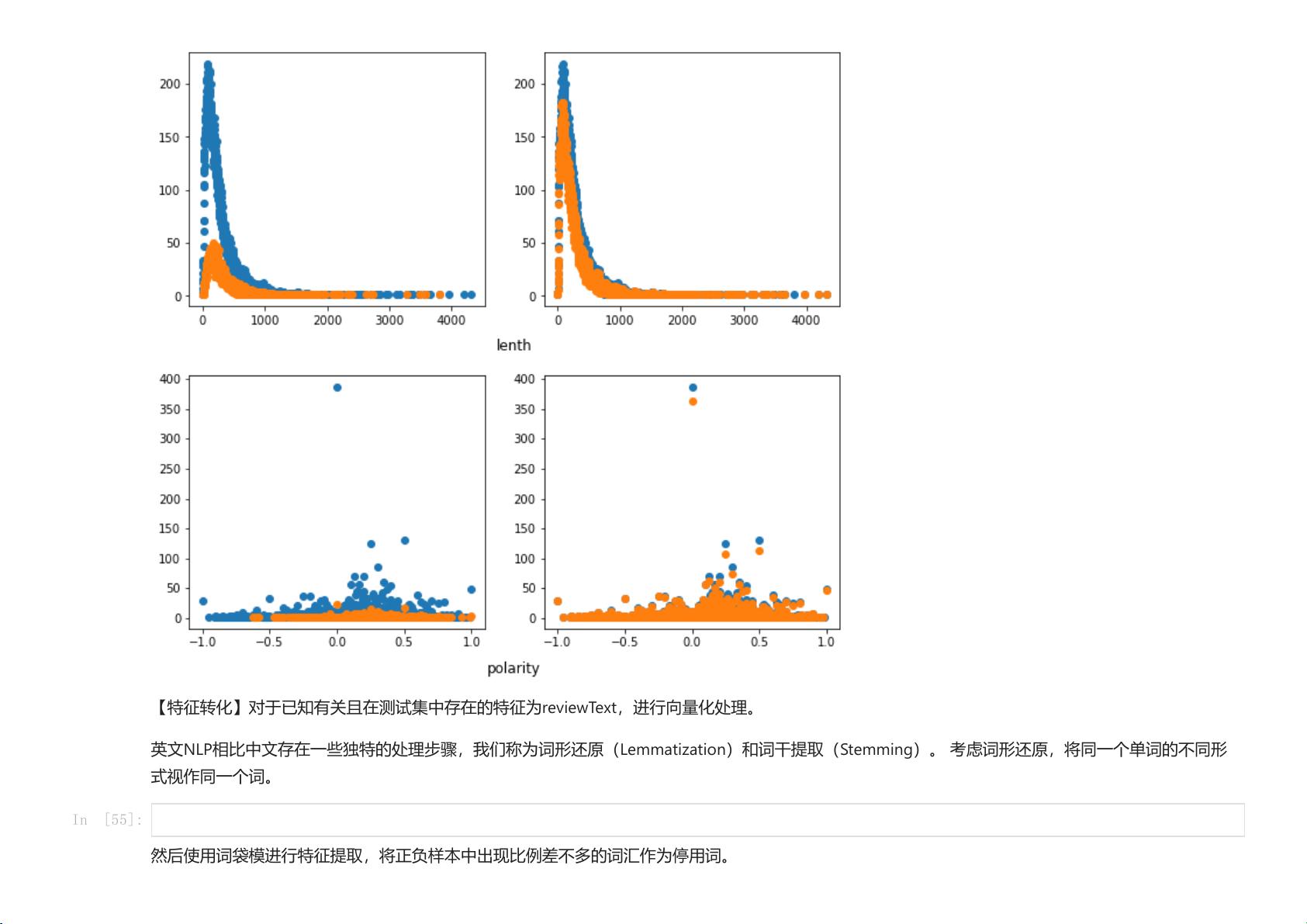
首先,参与者需要手动实现集成学习的核心算法,并设计适当的特征表示,以便捕捉评论的潜在质量和相关性。这可能涉及到文本预处理、词向量化或NLP特征工程。然后,他们需要报告每组模型在训练集上的AUC值,以及解释结果差异,这有助于理解不同算法和基分类器在处理这类问题上的优势和局限性。
除了基本要求,实验还鼓励扩展探索,例如使用k-NN和朴素贝叶斯等其他基分类器,来观察它们对预测性能的影响。这将有助于发现更全面的模型选择策略。此外,分析特征的重要性,比如评论文本的长度、情感倾向等,能够揭示哪些因素对评论质量的判断最具影响力。
同时,集成学习算法的参数调整也是一个关键环节,因为不同的参数设置可能会显著改变模型的表现。通过调整和优化参数,可以进一步提升预测精度并理解算法的稳定性。
最后,提交部分需要按照特定格式,提供测试集中的每条评论被预测为高质量评论的概率,这对于实际应用中的评论筛选和用户体验优化至关重要。整个过程不仅锻炼了对集成学习的理解,也提升了数据分析和模型构建的实际操作能力。"
剩余35页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-02 上传
2021-10-05 上传
2021-09-05 上传
2009-04-18 上传
2021-08-31 上传
2024-01-13 上传

周鸭子的单刀
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- CNTK-2-0-Windows-64bit-CPU-Only.zip
- shuffle-app:通过Spotify洗牌
- java毕设之餐饮管理系统的设计与实现源码(springboot+vue+mysql+说明文档+LW).zip
- is-set:轻松检查对象是否为ES6集的节点模块
- java毕设之在线考试系统源码(springboot+vue+mysql+说明文档+LW).zip
- Android Tab界面的切换效果.zip
- Tsunami UDP Protocol-开源
- java毕设之青年公寓服务平台源码(springboot+vue+mysql+说明文档+LW).zip
- terraform-aws-lambda-do-it-all:Terraform模块以提供具有完全权限的lambda
- 第一行代码Java源代码第13章课程代码Java类集框
- DaWeather---Project:DAWIN专业许可证的指导项目(波尔多)
- WCF的增删改查客户端和服务端源码
- ValentineRieb_3_24032021
- is-success:检查数字是否为HTTP成功状态代码
- java毕设之社区养老服务系统源码(springboot+vue+mysql+说明文档+LW).zip
- agreed:同意使用带有JSON模拟服务器的消费者驱动合同工具
