Cluster 3.0 教程:K-means与SOM算法扩展
"Cluster 3.0 是一个由迈克尔·艾森在斯坦福大学最初编写的聚类软件的手册。这个版本中,对k-均值聚类算法进行了修改,并扩展了自组织映射(SOM)算法,支持二维矩形网格。此外,它新增了欧氏距离和城市街区距离作为基因表达数据之间的新距离度量,并用开源软件替代了原版Cluster/TreeView中的专有Numerical Recipes程序。Cluster 3.0支持Windows、Mac OS X、Linux和Unix操作系统。"
集群分析是数据分析中的一个重要工具,用于将数据分组到相似的集合中。在这个手册中,重点讨论的是Cluster 3.0,它是一款强大的聚类软件,特别适用于处理基因表达数据。K-均值聚类是一种广泛应用的无监督学习方法,通过迭代寻找最佳的群组分配,使得同一群组内的数据点间距离最小,而不同群组间的距离最大。在Cluster 3.0中,这个算法被改进,可能会提供更高效或适应性更强的聚类结果。
自组织映射(Self-Organizing Maps, SOMs),又称为 Kohonen 网络,是一种人工神经网络,能将高维输入数据映射到低维空间,通常是一个二维网格。Cluster 3.0 对 SOM 进行了扩展,支持二维矩形网格,这可能意味着用户可以自定义网络布局,更好地适应复杂的数据结构。
在数据处理方面,手册中提到加载、过滤和调整数据是关键步骤。加载数据是指导入需要进行聚类分析的数据集。过滤数据允许用户根据某些条件(如阈值或特性)剔除不相关或噪声数据,以提高分析的准确性。调整数据可能涉及归一化、标准化等预处理步骤,确保不同尺度或范围的数据可以在同一平台上公平比较。
距离度量的选择对聚类结果有很大影响。欧氏距离是最常见的距离度量,考虑所有特征的平方差,而城市街区距离(曼哈顿距离)则计算各特征绝对差异的总和。在基因表达数据中,这些距离度量可以帮助捕捉不同类型的相似性。
替换专有Numerical Recipes程序为开源软件,这一改变可能降低了软件的使用成本,同时也提高了代码的透明度和可维护性,使得更多研究者能够理解和定制软件功能。
Cluster 3.0 手册详细介绍了如何使用这个软件进行有效的数据聚类,包括核心算法的改进、新的距离度量以及数据处理流程。这对于生物信息学、统计学、机器学习等领域研究者来说,是一个宝贵的资源,能够帮助他们更有效地分析和理解大规模数据集。
Chapter 2: Loading, filtering, and adjusting data 4
2.1 Loading Data
The first step in using Cluster is to imp ort data. Currently, Cluster only reads tab-delimited
text files in a particular format, described below. Such tab-delimited text files can be created
and exported in any standard spreadsheet program, such as Microsoft Excel. An example
datafile can be found under the File format help item in the Help menu. This contains all
the information you need for making a Cluster input file.
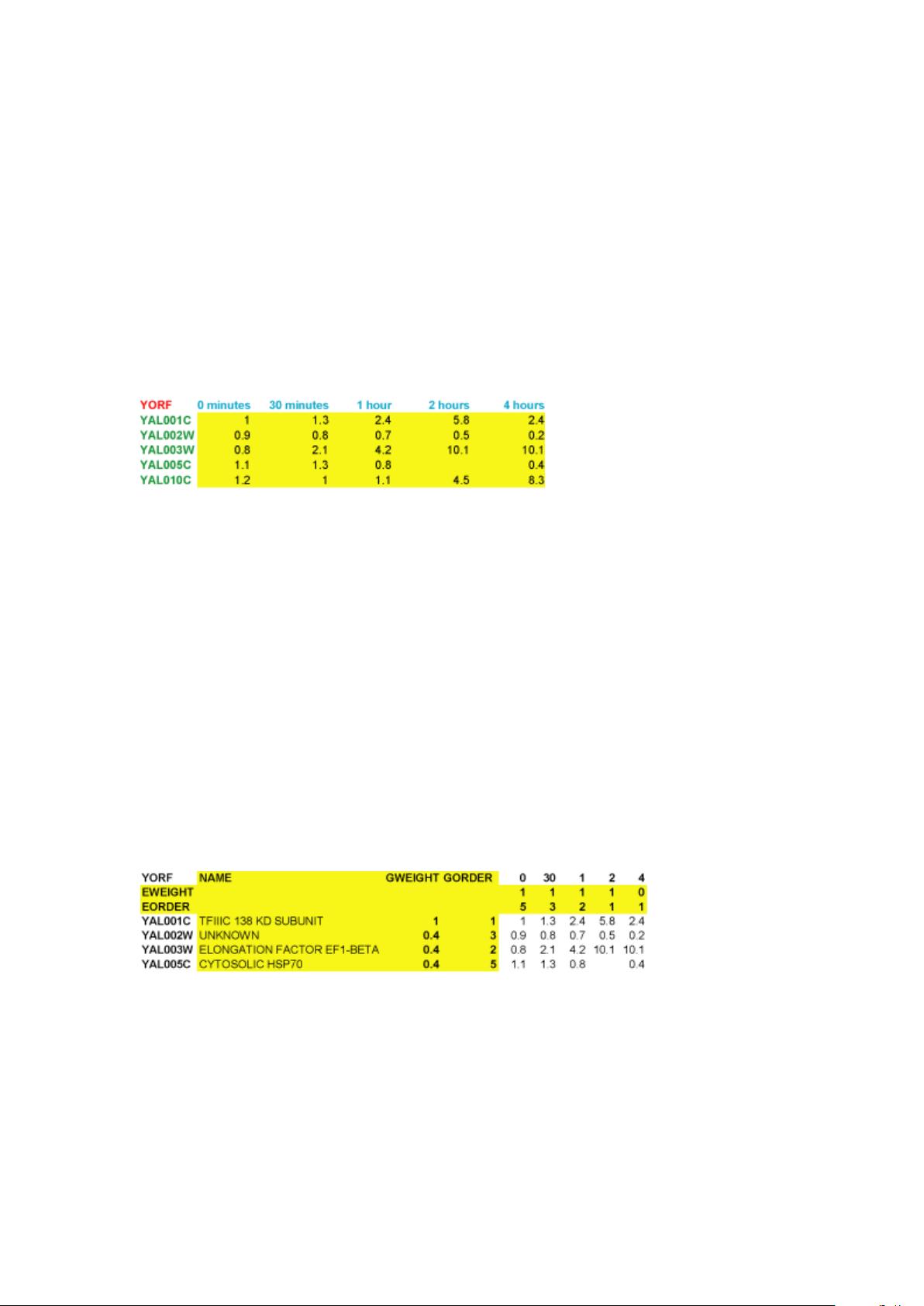
By convention, in Cluster input tables rows represent genes and columns represent sam-
ples or observations (e.g. a single microarray hybridization). For a simple timecourse, a
minimal Cluster input file would look like this:
Each row (gene) has an identifier (in green) that always goes in the first column. Here we
are using yeast open reading frame codes. Each column (sample) has a label (in blue) that
is always in the first row; here the labels describe the time at which a sample was taken.
The first column of the first row contains a special field (in red) that tells the program what
kind of objects are in each row. In this case, YORF stands for yeast open reading frame.
This field can be any alpha-numeric value. It is used in TreeView to specify how rows are
linked to external websites.
The remaining cells in the table contain data for the appropriate gene and sample. The
5.8 in row 2 column 4 means that the observed data value for gene YAL001C at 2 hours
was 5.8. Missing values are acceptable and are designated by empty cells (e.g. YAL005C
at 2 hours).
It is possible to have additional information in the input file. A maximal Cluster input
file would look like this:
The yellow columns and rows are optional. By default, TreeView uses the ID in column 1
as a label for each gene. The NAME column allows you to specify a label for each gene that
is distinct from the ID in column 1. The other rows and columns will be described later in
this text.
剩余33页未读,继续阅读
2011-02-10 上传
229 浏览量
2015-08-12 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

jiwt
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
