Druid Rollup详解:数据压缩与位图索引应用
需积分: 0 29 浏览量
更新于2024-08-04
收藏 276KB PDF 举报
Apache Druid 是一个流行的开源时序数据库,特别适用于大数据处理,其Rollup功能在数据摄取阶段起着关键作用。Rollup是一种数据聚合技术,通过对选定列的聚合操作,如计数、求和等,降低存储数据的复杂性和大小,从而提高查询性能。本文主要介绍Druid的Rollup过程及其在位图索引构建中的应用。
首先,Rollup的基本概念是将原始数据按照特定的时间粒度(如毫秒级别queryGranularity)进行聚合,例如,将每天的数据合并成一个条目,这样在存储时就不需要保留每一毫秒的具体数值,而是保存每个维度组合的汇总结果。这大大减少了存储需求,特别是当数据量巨大时,能够有效降低存储压力。
在Druid中,Rollup的过程包括以下几个步骤:
1. **数据摄入阶段的汇总**:Druid在数据注入时即执行Rollup操作,确保数据在进入数据库时已经是预处理过的,这有利于后续的查询性能提升。
2. **示例数据展示**:作者提供了一个具体的例子,原始数据包含时间、Appkey和area维度列,以及value metric。Rollup前的数据详细展示原始存储情况,而Rollup后的数据则是按照一天为单位的聚合结果。
3. **位图索引的应用**:Druid利用位图索引来加速数据查找。位图索引类似于一个哈希映射,其中键是维度值,值是一个二进制位图,用于表示对应行是否包含该维度。这样,在查询时,只需要比较位图即可快速定位到满足条件的行,提高了查询效率。
4. **查询过程示例**:查询过程涉及定位特定时间段内的数据,通过指定的Appkey和area范围,Druid能够快速从索引中找出相关位图,然后通过逻辑运算(如OR)确定哪些行匹配查询条件。
总结来说,Apache Druid通过Rollup功能和位图索引技术,优化了数据的存储和查询效率,使得时序数据在大规模环境下也能高效处理。掌握这些原理和示例,有助于开发人员更好地利用Druid进行数据分析和性能调优。
Apache Druid 系列文章
1、Druid(Imply-3.0.4)介绍及部署(centos6.10)、验证
2、Druid的入门示例(使用三种不同的方式摄入数据和提交任务)
3、Druid的load data 示例(实时kafka数据和离线-本地或hdfs数据)
4、java操作druid api
5、Druid配置文件详细介绍以及示例
6、Druid的Roll up详细介绍及示例
@TOC
本文介绍了druid 的 rool-up过程以及位图索引构建过程、实际的应用过程。
本文分为1个部分,即介绍与示例。
一、介绍及示例
1、介绍
Apache Druid可以通过roll-up在数据摄取阶段对原始数据进行汇总。
Roll-up是对选定列集的一级聚合操作,它可以减小存储数据的大小。
本文将讨论在一个示例数据集上进行roll-up的结果。
Druid通过一个roll-up的处理,将原始数据在注入的时候就进行汇总处理
roll-up可以压缩我们需要保存的数据量
Druid会把选定的相同维度的数据进行聚合操作,可减少存储的大小
Druid可以通过 queryGranularity 来控制注入数据的粒度。 最小的queryGranularity 是
millisecond(毫秒级)
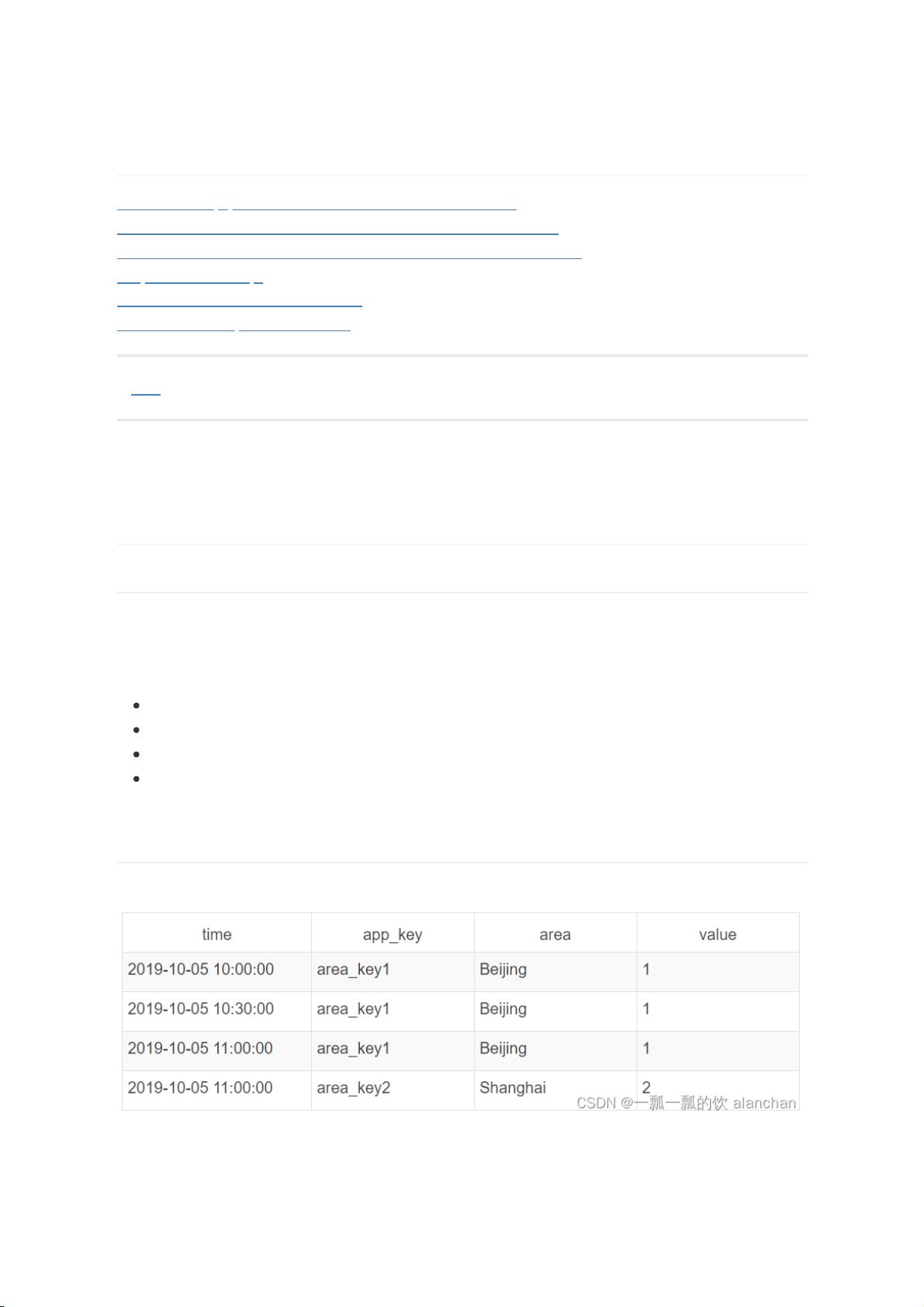
2、示例数据
Roll-up聚合前
下载后可阅读完整内容,剩余3页未读,立即下载
2023-05-24 上传
2023-05-24 上传
2023-05-24 上传
2023-12-23 上传
2023-02-06 上传
2023-08-31 上传
2023-07-20 上传
2023-03-25 上传
2023-05-21 上传

一瓢一瓢的饮alanchanchn
- 粉丝: 7598
- 资源: 69
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
