强化学习:4x4网格DP问题分析与实现
需积分: 0 29 浏览量
更新于2024-08-05
收藏 552KB PDF 举报
在本资源中,我们探讨了一个基于《强化学习:一个介绍》(Reinforcement Learning: An Introduction)第4章例4.1的问题,这是一个关于动态规划(DP)的小型网格问题。网格图是一个4x4的非终止状态空间,状态可以通过四种动作进行转移:向上、向下、向左和向右。然而,如果动作导致智能体离开网格,状态不会改变。任务是无折扣的分幕式,目标是在未达到终止状态前获取最大累积回报,所有动作的即时奖励都是-1。
问题的核心是计算在采取等概率随机策略下的价值函数序列在迭代策略评估中的收敛情况。环境设置包括以下关键部分:
1. **环境定义**:
- 导入必要的库函数,如`matplotlib`和`numpy`,用于可视化和数值计算。
- 定义网格世界大小为4x4,动作包括四个基本移动方向。
- 动作选择的概率均匀分配为0.25,表示智能体在选择动作时等概率执行。
- 设定终止状态为左上角(0,0)和右下角(WORLD_SIZE-1, WORLD_SIZE-1)。
2. **动作执行过程**:
- `is_terminal`函数判断当前状态是否为终止状态。
- `step`函数模拟智能体执行动作并更新状态,如果动作导致离开网格,状态保持不变。
3. **辅助函数**:
- 用于画图和可视化网格,帮助理解智能体的行为和状态变化。
- 用户策略描述辅助函数可能涉及到策略迭代或值迭代过程中的策略评估和更新。
在解决这个问题时,主要步骤可能涉及构建价值函数表格,初始化所有状态的价值估计,然后根据动作选择概率和环境动态更新这些估计值。通过重复这个过程(例如,使用γ(折扣因子)和ε-greedy策略),我们可以观察价值函数在每次迭代后的收敛趋势,以及智能体如何逐渐学习到最优路径以最大化累积回报。最后,这将有助于深入理解强化学习中的动态规划应用,特别是在没有明确最优策略的情况下,如何通过迭代优化来寻找近似解决方案。
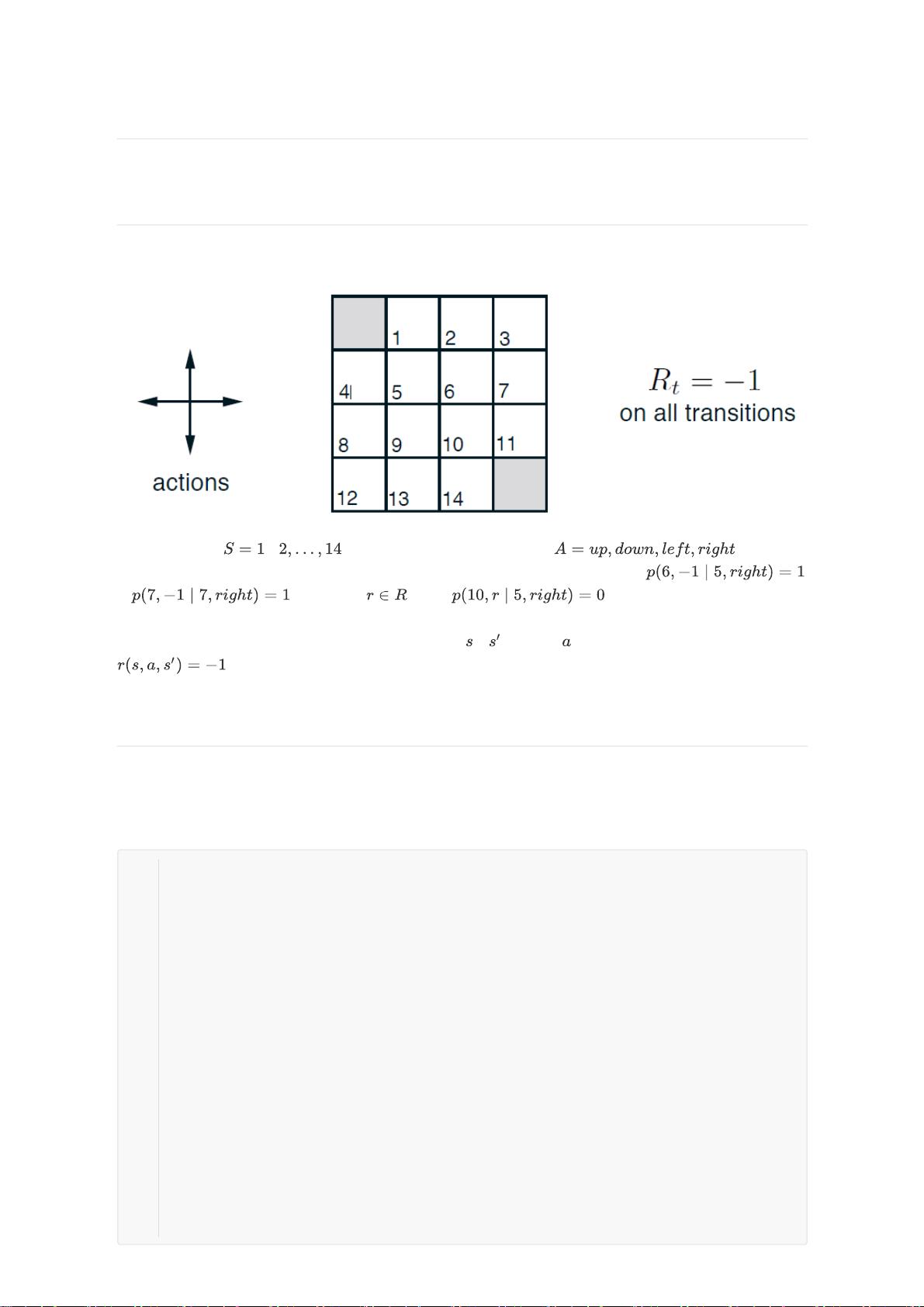
强化学习基础篇(二十二)DP小型网格问题
该问题基于《Reinforcement Learning: An Introduction》在第四章的例4.1。
1、问题描述
考虑下面的这个4*4的网格图
非终止状态集合
,
。每个状态有四种可能的动作, 。每个动
作会导致状态转移,但当动作会导致智能体移出网格时,状态保持不变。比如,
, 和对于任意 ,都有 。这是一个无折扣的分幕式任
务。在到达终止状态之前,所有动作的收益均为-1。终止状态在图中以阴影显示(尽管图中显示了两个
格子,但实际仅有一个终止状态)。对于所有的状态 , 以及动作 ,期望的收益函数均为
。假设智能体采取等概率随机策略(所有动作等可能执行),我们需要计算在迭代策略
评估中价值函数序列的收敛情况。
2、实现过程
2.1、环境定义
首先导入库函数以及定义环境信息:
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.table import Table
# 定义网格世界大小
WORLD_SIZE = 4
# 把动作定义为对x,y坐标的增减改变
# left, up, right, down
ACTIONS = [np.array([0, -1]), # 向上
np.array([-1, 0]), # 向左
np.array([0, 1]), # 向下
np.array([1, 0])] # 向右
# 该问题中每个动作选择的概率为0.25
ACTION_PROB = 0.25
# 定义画图会用到的动作
ACTIONS_FIGS=[ '←', '↑', '→', '↓']
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
下载后可阅读完整内容,剩余7页未读,立即下载
2021-10-02 上传
355 浏览量
2021-06-29 上传
2021-02-09 上传
2013-03-18 上传
2022-08-03 上传
2014-04-01 上传
2021-06-30 上传
点击了解资源详情

KerstinTongxi
- 粉丝: 26
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
