Python实现布隆过滤器:原理与应用解析
38 浏览量
更新于2024-08-31
收藏 384KB PDF 举报
"这篇文章除了介绍Python实现布隆过滤器外,还涉及了布隆过滤器的基本概念、工作原理及其在解决缓存击穿问题中的应用。文章通过实例展示了如何利用位数组和多个哈希函数来实现插入和查询操作,同时也探讨了布隆过滤器的误判率和空间效率之间的平衡。"
布隆过滤器是一种非常实用的数据结构,尤其在处理大规模数据集时,其高效性和空间节省成为主要优势。在Python中实现布隆过滤器,通常会利用位数组和几个独立的哈希函数。位数组是一系列未初始化的二进制位,初始状态全部为0。哈希函数则用于将输入数据映射到位数组的不同位置。
当插入一个元素时,这个元素会通过预先设定的多个哈希函数得到不同的哈希值,这些哈希值作为索引将位数组的对应位置设置为1。例如,插入"baidu"这个URL,其哈希值可能会指向位数组的1、4和7号位置,将这三个位置设为1。如果后续插入的元素与已有元素有相同的哈希值,就会出现“碰撞”,这是布隆过滤器可能出现误判的原因。
在查询阶段,若要检查一个元素是否存在,同样用哈希函数计算其在位数组中的位置。如果所有位置都是1,那么该元素可能存在;但如果存在任何0,就可以肯定这个元素不在集合中。这种设计使得布隆过滤器能够快速排除大量不存在的元素,但无法保证完全准确,因为它可能会把不存在的元素误判为可能存在。
布隆过滤器的误判率与位数组的大小和使用的哈希函数数量有关。更大的位数组可以降低误判率,但也会占用更多存储空间。因此,在实际应用中,需要根据预期的数据量和可接受的误判率来调整这两个参数。
在缓存击穿问题中,布隆过滤器可以作为一种解决方案。当大量请求集中在某个不存在的键上,可能会导致缓存系统不堪重负。此时,使用布隆过滤器先过滤掉这些不可能存在的键,可以减轻缓存的压力。
Python实现的布隆过滤器结合了理论和实践,是一种强大的工具,尤其适用于需要快速过滤大量数据且对精确性有一定容忍度的场景,如防止垃圾邮件、URL去重、数据库查询优化等。不过,由于其内在的误判特性,不适用于那些误判可能导致严重后果的场合。
python实现布隆过滤器及原理解析实现布隆过滤器及原理解析
布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和
查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。这篇文章主要介绍了python实现布隆过滤器 ,需要的朋友可以参
考下
在学习redis过程中提到一个缓存击穿的问题, 书中参考的解决方案之一是使用布隆过滤器, 那么就有必要来了解一下什么是布隆过滤器。在
参考了许多博客之后, 写个总结记录一下。
一、布隆过滤器简介一、布隆过滤器简介
什么是布隆过滤器?什么是布隆过滤器?
本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可
以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器原理布隆过滤器原理
布隆过滤器内部维护一个bitArray(位数组), 开始所有数据全部置 0 。当一个元素过来时,能过多个哈希函数(hash1,hash2,hash3....)计算不
同的在哈希值,并通过哈希值找到对应的bitArray下标处,将里面的值 0 置为 1 。 需要说明的是,布隆过滤器有一个误判率的概念,误判率越
低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。
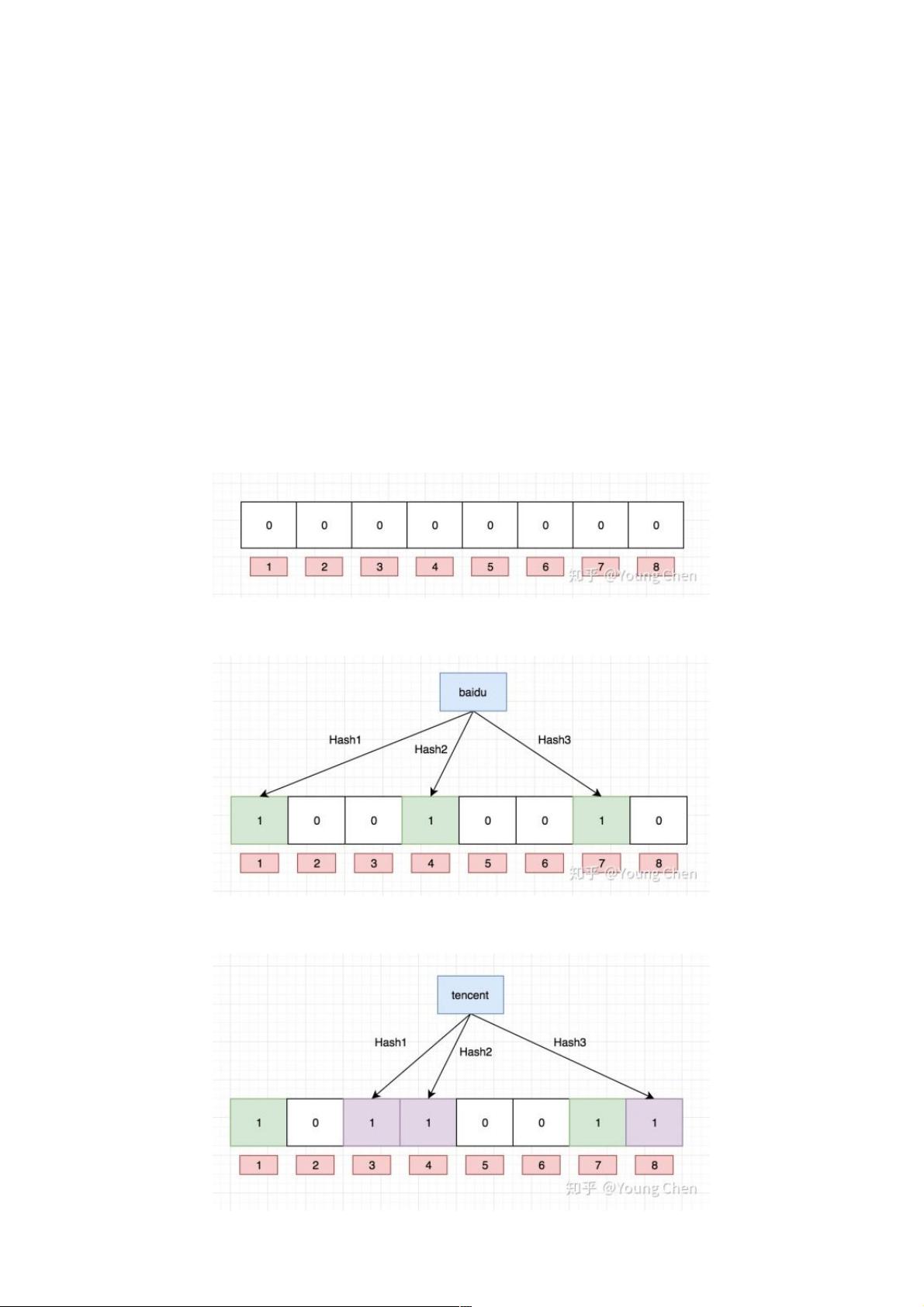
下面以网址为例来进行说明, 例如布隆过滤器的初始情况如下图所示:
现在我们需要往布隆过滤里中插入baidu这个url,经过3个哈希函数的计算,hash值分别为1,4,7,那么我们就需要对布隆过滤器的对应的bit
位置1, 就如图下所示:
接下来,需要继续往布隆过滤器中添加tencent这个url,然后它计算出来的hash值分别3,4,8,继续往对应的bit位置1。这里就需要注意一个
点, 上面两个url最后计算出来的hash值都有4,这个现象也是布隆不能确认某个元素一定存在的原因,最后如下图所示:
布隆过滤器的查询也很简单,例如我们需要查找python,只需要计算出它的hash值, 如果该值为2,4,7,那么因为对应bit位上的数据有一个
不为1, 那么一定可以断言python不存在,但是如果它计算的hash值是1,3,7,那么就只能判断出python可能存在,这个例子就可以看出来,
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-12 上传
2024-11-12 上传
2021-03-20 上传
2022-05-31 上传
点击了解资源详情

weixin_38677648
- 粉丝: 5
- 资源: 886
 我的内容管理
展开
我的内容管理
展开







最新资源
- NASM中文手册.......
- PIC8位单片机汇编语言常用指令的识读.doc
- 车牌识别系统算法的研究与实现
- 从MySpace的六次重构经历,来认识分布式系统到底该如何创建
- 软件测试面试题(白盒、黑盒测试)
- 从LiveJournal后台发展看大规模网站性能优化方法
- 2009年上半年网络工程师下午题
- 2009年网络工程师上午题
- 嵌入式c c++集锦
- ajax技术资料 PDF
- ofdm_carrier_sync\A consistent OFDM carrier frequency offset estimator based on distinctively spaced pilot tones.pdf
- jsp+源码+学生成绩管理系统 jsp源代码
- 9F概论(第四版)课后习题的参考答案[1].doc
- linux内核情景分析
- 基于VB的参数化绘图.pdf
- Java设计模式中文版
