基于Hownet的词汇语义相似度计算方法详解
需积分: 34 114 浏览量
更新于2024-09-11
2
收藏 600KB PPTX 举报
本篇文章《基于知网的词汇语义相似度计算方法研究》由葛斌、李芳芳、郭丝路和汤大权在2010年发表于《计算机应用研究》期刊中,主要探讨了如何利用中国知网(Hownet)进行词汇语义相似度的计算。知网是一个大型的汉语知识库,它以四元组形式存储词汇,包括词语、词例、词性和概念定义。义原是描述概念的最小意义单位,而义项则是词汇的多种含义的表达,通过义原层次树来体现词与义原的关系。
文章的核心内容围绕以下几个方面展开:
1. 义原和义项的定义:
- 义原是描述一个概念的基础元素,不可再分,是构建词汇意义的关键。
- 义项是对词汇的多维度描述,是通过义原的知识描述语言(KDML)来表达的,其结构体现了词汇的意义和关系。
2. 语义相似度计算方法:
- 基于知网的词典,计算过程中主要依赖于义原间的上下位关系和路径。
- 计算过程包括以下步骤:
- 提取义项中的义原表达式。
- 计算义原间的语义距离,这个距离考虑了义原在层次树中的路径长度、深度和密度。
- 通过权重函数调整,如递减的权重随层数增加,反映了深度因素。
- 最小公共节点(LCN)的概念被引入,用于衡量两个义原的共享信息量,这涉及到密度因素。
3. 公式设计:
- 公式2定义了两个义原间的距离,考虑了路径长度和权重。
- 公式3给出了权重函数的具体形式,随着层次递增而递减。
- 公式4利用LCN和节点占比f(w)来综合考虑密度影响,从而计算出最终的词汇相似度。
总结来说,这篇文章提供了一种基于Hownet的细致而系统的方法,通过深度、密度等多维度考量,准确计算出词汇之间的语义相似度,这对于文本挖掘、信息检索等领域具有重要的实际应用价值。
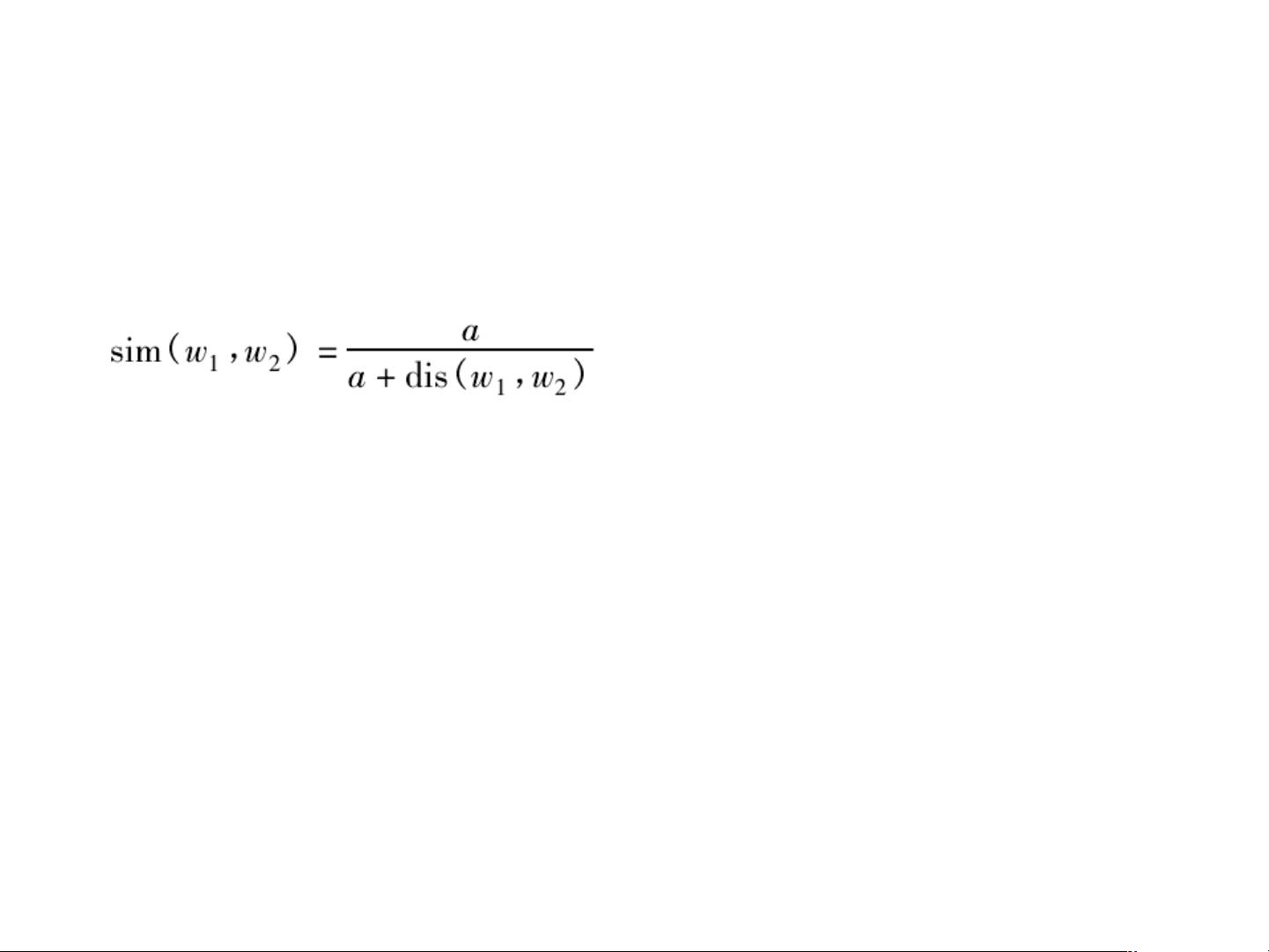
1. 相关知识
公式 1
其中 : ɑ 是一个可调节的参数,表示相似度为 0.5 时的语义距离值。
1.1 语义距离和语义相似度的关系见公式 1
1.2 知网
a) 义项:它是对词汇语义的一种描述,每一个词可以表达为几个义项,义项
是用一种知识表示语言来描述的,这种知识表示语言所用的词汇叫做义原。
b) 义原:它是用于描述一个概念的最小意义单位,从所有词汇中提炼出的可
以用来描述其他词汇的不可再分的基本元素。
知网的汉语知识库中每个词汇由一个四元组表示 :
W_X= 词语 E_X = 词语例子 G_X= 词语词性 DEF= 概念
定义
DEF 部分是表示词与义原的关系,也是词汇描述中最重要的部分,可以
简单地认为词是由义原通过某种关系构成的 .
剩余11页未读,继续阅读
2019-08-10 上传
2021-01-02 上传
2018-12-21 上传
2021-04-05 上传
123 浏览量
2024-10-01 上传
2022-08-03 上传
点击了解资源详情
点击了解资源详情

knoeledge_zhangdidi
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
