Linux下grep正则表达式总结:文本匹配与应用实战
PDF格式 | 1.39MB |
更新于2024-09-02
| 112 浏览量 | 举报
正则表达式在Linux下的grep工具中扮演着关键角色,它是一种强大的文本匹配工具,用于描述一组字符串特征的模式,帮助用户在大量文本中精准定位符合特定模式的字符串。通过结合特殊字符和普通字符,正则表达式能够实现复杂的文本匹配,其功能类似于生活中的寻人启示,通过描述特征来搜索和筛选目标。
在实际应用中,正则表达式的用途广泛。例如,在表单提交验证中,可以用来检查用户名和密码是否符合规则;在数据处理中,可以快速从大量信息中提取特定内容,或者在URL列表中查找指定格式的链接;此外,还可以利用正则表达式进行文本替换,如在vim等文本编辑器中,根据匹配到的模式进行替换操作。
字符类是构成正则表达式的基础,包括通用字符如`.`匹配任意字符、字符集`[]`匹配括号内的任意字符、连字符`-`表示字符范围,以及预定义的命名字符类如`[[:digit:]],[[:alpha:], [[:lower:]]`分别匹配数字、字母和小写字母等。使用这些字符类,可以更精确地定义匹配条件。
数量限定符`?`和`+`也非常重要,`?`表示前面的字符或子表达式出现0次或1次,而`+`则表示出现1次或多次。例如,邮箱地址的正则表达式`[a-zA-Z0-9_.-]+@[a-zA-Z0-9_.-]+\.[a-zA-Z0-9_.-]+`就是利用这些限定符来匹配邮件地址的各个部分。
在Linux环境下,`grep`命令提供了丰富的功能,如颜色高亮显示匹配结果,可以通过`--color`选项实现。同时,命令的执行结果可以通过`echo $?`获取退出码,0表示成功,1表示失败,这对于监控和调试脚本执行非常有用。
正则表达式在Linux下是强大的文本处理工具,熟练掌握其语法和用法对于提高工作效率和解决复杂问题至关重要。通过理解字符类、数量限定符和grep的特性,可以更好地利用正则表达式在实际工作场景中实现高效的数据搜索和处理。
linux下关于正则表达式下关于正则表达式grep的一点总结的一点总结
正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到
文本匹配目的工具
正则表达式(正则表达式(Regular Expression))是用于描述一组字符串特征的模式,用来匹配特定的字符串。通过特殊字符+普通字符来进行模式描述,从而达到文本匹配目的工
具。类似于生活中常见的寻人启示,通过描述一个人的特征来进行“搜索匹配”
如今正则已经被我们广泛应用,目前被集成到了各种文本编辑器/文本处理工具当中
应用场景**验证: **表单提交时,进行用户名密码验证。**查找: **从大量信息中快速提取指定内容。在一批url中,查找指定url替换替换: 将指定格式的文本,进行正则匹配查
找,找到之后进行特定替换,(vim文本替换等)
在很多技术领域(比如,自然语言处理,数据存储等),正则表达式可以很方便的提取出我们想要的信息,所以这部分必不可少构成基本要素字符类字符类数量限定符数量限定符位置限定位置限定
符符特殊符号特殊符号
1. 字符类:字符类:
字符字符 说明说明 举例举例
. 匹配任意的一个一个字符 abc. 可以匹配abcd、abc0等
[] 匹配 [] 内的任意一个字符 [012]a可以匹配0a、1a、2a
- 在括号内表示字符范围 如[0-9]可以匹配任何一个数字
^ 放在[]内前面表示匹配除括号中字符外的任意一个字符 [^ab]c可以匹配1c、dc,但是不能匹配ac、bc
[[:xxx:]] grep工具预定义的一些命名字符类 [[:digit:]]可以匹配一个数字,[[:alpha:]]匹配一个字符,[[:lower:]]匹配任何一个小写字母等
应用:应用:
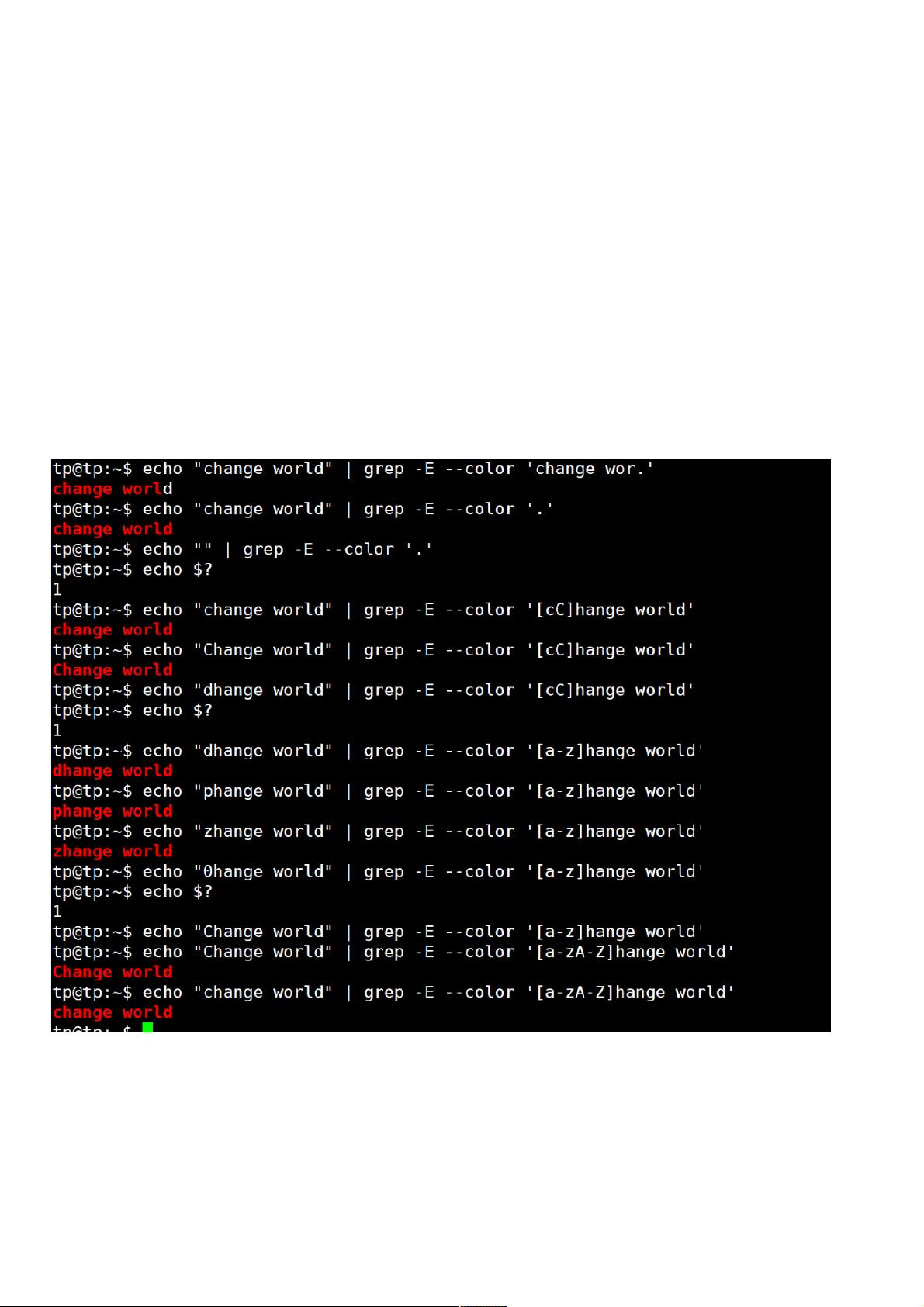
grep使用使用--color选项将匹配的字符串以红色标注出来选项将匹配的字符串以红色标注出来Linux下可以用下可以用echo $?来打印上一条命令执行的退出码,为来打印上一条命令执行的退出码,为0表示执行成功,表示执行成功,1表示失败。表示失败。
实验如下:
注意:注意:使用 . 默认为贪心匹配,和后面的正则匹配方式相关,后面再述。
下载后可阅读完整内容,剩余5页未读,立即下载
相关推荐





weixin_38605538
- 粉丝: 4
- 资源: 991
 我的内容管理
展开
我的内容管理
展开







最新资源
- webwork2guide.pdf
- 身份认证技术分析(论文)
- birt报表参数使用
- 高质量的c++c编程指南
- Flex 3 Cookbook
- BCM5228 10/100BASE-TX/FX Transceiver
- ActionScript 3.0 Cookbook 中文版
- The International Reference Alphabet
- 你必须知道的495个C语言问题(内含完整章节,PDF格式)
- SQL Server 使用方法
- 清华大学信号与系统课件
- lingoziliao
- Advanced 3D Game Programming With Directx 9.0.pdf
- C程序设计 谭浩强 清华大学出版社
- eclipse插件开发指南
- javaeye月刊2008年6月 总第4期.pdf
