深度学习模型解析:RNN结构与应用
6 浏览量
更新于2024-08-28
收藏 2.74MB PDF 举报
"本文主要介绍了深度学习模型的基本结构,特别是循环神经网络(RNN)的原理和应用。文章深入浅出地阐述了RNN的工作机制,以及它在解决序列数据问题上的优势。"
深度学习是一种模仿人脑神经网络的机器学习技术,其基本步骤包括定义模型、定义损失函数和选择优化方法。在处理序列数据时,传统的Feedforward Network可能由于参数过多而导致过拟合。因此,循环神经网络(RNN)应运而生,它的核心思想是一个函数的反复迭代,这使得RNN能够处理任意长度的输入序列,同时减少了参数数量,降低了过拟合的风险。
RNN的主要特点是其内部状态(或称记忆单元)能够捕获前一时刻的信息,并将其传递到下一时刻,形成一种时间依赖性。在训练过程中,尽管RNN可能较为困难,但一旦在训练数据上得到良好表现,其在测试数据上的性能通常也会不错。在实际应用中,需要注意的是,当连接多个RNN层时,如在Deep RNN中,各层输出的维度需要保持一致,以便于信息的传递。
双向RNN是RNN的一种扩展,它包含两个方向的RNN,分别处理序列的正向和反向信息,从而能够更好地捕捉序列中的前后依赖关系。这种结构在许多任务中,如语音识别,能够提供更丰富的上下文信息。
在语音识别的应用中,常常采用双向RNN的多层次结构。第一层通常是双向的,随后的层将上一层的多个输出组合为新的输入,这种结构既增加了模型的表达能力,也利于并行计算的加速。RNN的并行化是一个挑战,因为其顺序计算特性,但在Pyramidal RNN或类似的结构中,通过减少序列长度,可以在高层实现一定程度的并行计算。
RNN的基本运算单元通常包括输入门、遗忘门和细胞状态,这些门控机制允许模型动态地控制信息的流动和存储,例如LSTM(长短时记忆网络)和GRU(门控循环单元)。这些门控机制的引入有助于解决RNN中的梯度消失和梯度爆炸问题。
在简化版的语音识别任务中,RNN可以通过一个技巧——Target Delay来提高性能。这个技巧是在原始声音信号的右侧添加零填充,使得标签的识别延后开始,这种方法对于多分类问题特别有效。实验结果显示,RNN在不同方法中展现出良好的分类准确率。
RNN是处理序列数据的强大工具,其结构和变体如LSTM、GRU等在自然语言处理、语音识别、时间序列预测等领域有广泛应用。理解RNN的工作原理和应用场景,对于深度学习实践者来说至关重要。
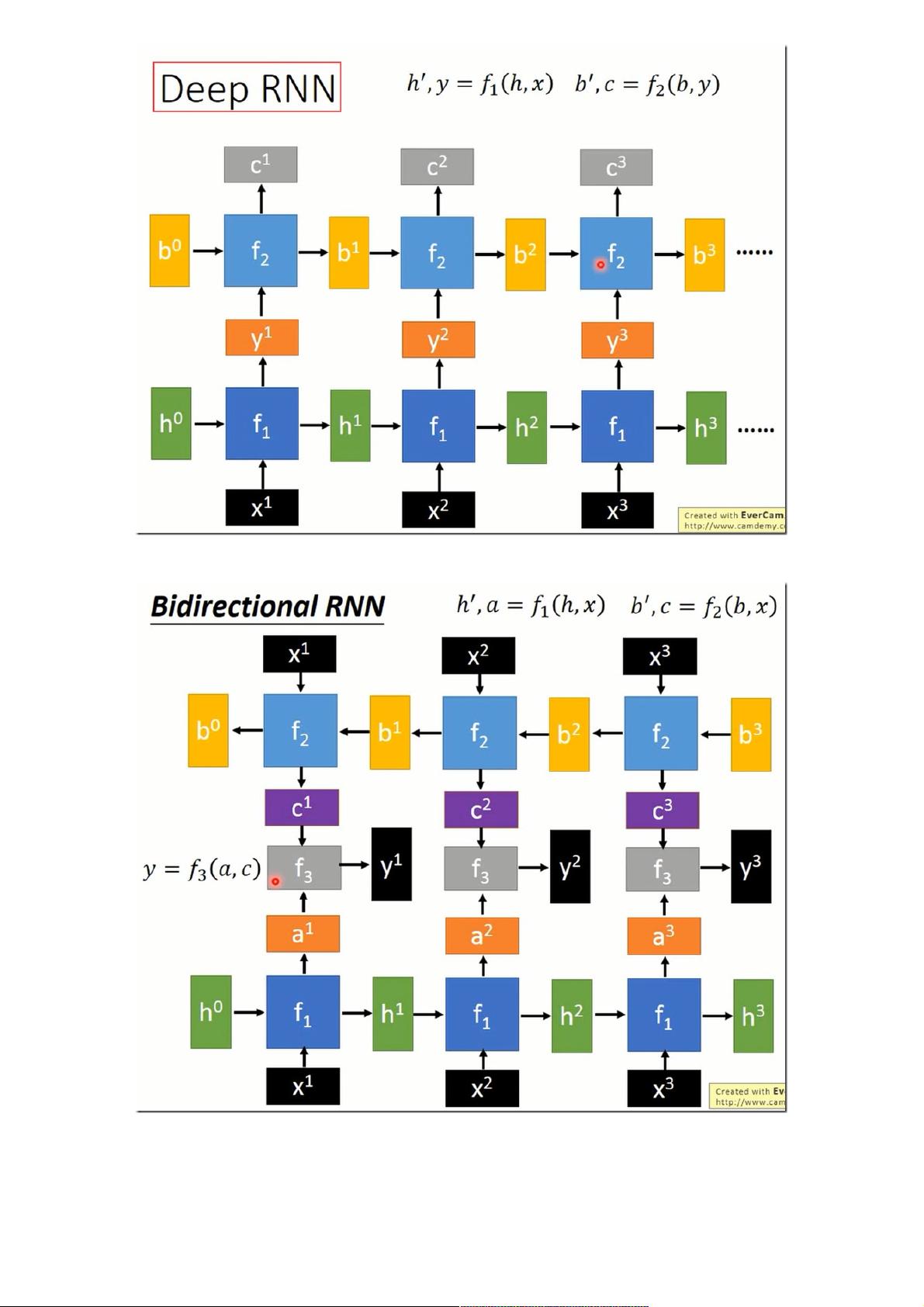
Deep RNN要注意到一点是 f1的输出和f2的输入的维度必须一致,这样才好拼接到一起。
双向RNN。就是要加入一个f3,将f1的输出和f2的输出整合在一起。至于f1和f2不必一样,你可以随便设计。
下面介绍一些具体的应用
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-12-21 上传
2021-01-20 上传
2024-09-22 上传
2021-06-06 上传
2018-09-23 上传
2021-08-19 上传

weixin_38553791
- 粉丝: 3
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- Credit_Risk_Analysis:使用机器学习算法进行分析以使用LendingClub的数据集识别信用卡风险
- Audio:project project这个项目是使用https制作的
- 智能果蔬水培系统
- stock-analysis
- MySalesCarProject
- sheql:调度查询语言
- 【地产资料】XX地产店长管理核心大纲.zip
- P2P-draw:点对点绘图应用程序
- CEUB-PPW:计划网络的动产仓库
- Shopping-Application-Java-:具有文本文件数据库的购物应用程序
- CS441_Proj6:自己设计的游戏
- Excel模板外币贷款明细表.zip
- npm-why:标识为什么安装了软件包。 等同于npm软件包的“ yarn why”
- R-code
- PTT-18Plus:主流浏览器附加元件,用来略过PTT 的「电脑网路内容分级处理办法」确认画面
- 一个基于hadoop的大数据实战.zip
