异构依赖解析:联合还是独立训练?
69 浏览量
更新于2024-08-28
收藏 188KB PDF 举报
在"Jointly or Separately: Which is Better for Parsing Heterogeneous Dependencies?"这篇于2014年COLING(第25届国际计算语言学会议)上发表的研究论文中,作者Meishan Zhang、Wanxiang Che、Yanqiu Shao和Ting Liu探讨了在处理像英语这样的多类型依赖关系时,联合训练与单独训练哪种方法更为有效的问题。语言中存在多种从短语结构(constituency)到依赖关系(dependency)的转换方法,如不同的分析视角导致了构建不同类型的依赖性语料库。这些转换方式通常被独立地用于训练依赖性解析器,忽略了它们之间的潜在关联。
传统的做法是针对每种特定的转换方法分别训练独立的解析器,这种方法可能忽视了不同转换之间存在的共性和互补性,这些共性可以提升解析器的整体性能。论文的核心贡献在于提出了一种联合模型,旨在充分利用不同转换方法之间的相互影响,通过整合这些异质依赖关系的训练数据,试图提高最终的依赖性解析精度。
通过实验,研究人员探究了这种联合模型在处理复杂语言结构时的效果,以及它如何改进传统分开训练的局限。他们可能采用了统计机器学习或深度学习技术,比如条件随机场(CRF)、递归神经网络(RNN)或Transformer架构,来设计并优化这个联合模型。论文不仅关注模型的性能提升,还可能涉及对模型复杂度、泛化能力以及在不同语言和领域中的适用性的讨论。
这篇论文深入研究了在依赖性解析任务中,如何利用不同转换方法之间的关系来提升模型的性能,挑战了传统上单一视角训练的方法,为跨视角依赖关系解析的优化策略提供了新的见解。其研究结果对于依赖性解析领域的实践者和技术开发者来说具有重要的参考价值。
S
1
· · ·
· · ·
S
0
· · ·
S
AR(l)
AL(l)
PR
Q
0
Q
1
· · ·
Q
SH
(a) Arc-standard dependency parsing model for a single dependency tree
S
a
1
· · ·
· · ·
S
a
0
· · ·
S
a
AR
a
(l)
AL
a
(l)
PR
a
Q
a
0
Q
a
1
· · ·
Q
a
SH
a
S
b
1
· · ·
· · ·
S
b
0
· · ·
S
b
AR
b
(l)
AL
b
(l)
PR
b
Q
b
0
Q
b
1
· · ·
Q
b
SH
b
Guided
a
Guided
b
(b) The joint model based on arc-standard dependency parsing for two dependency trees
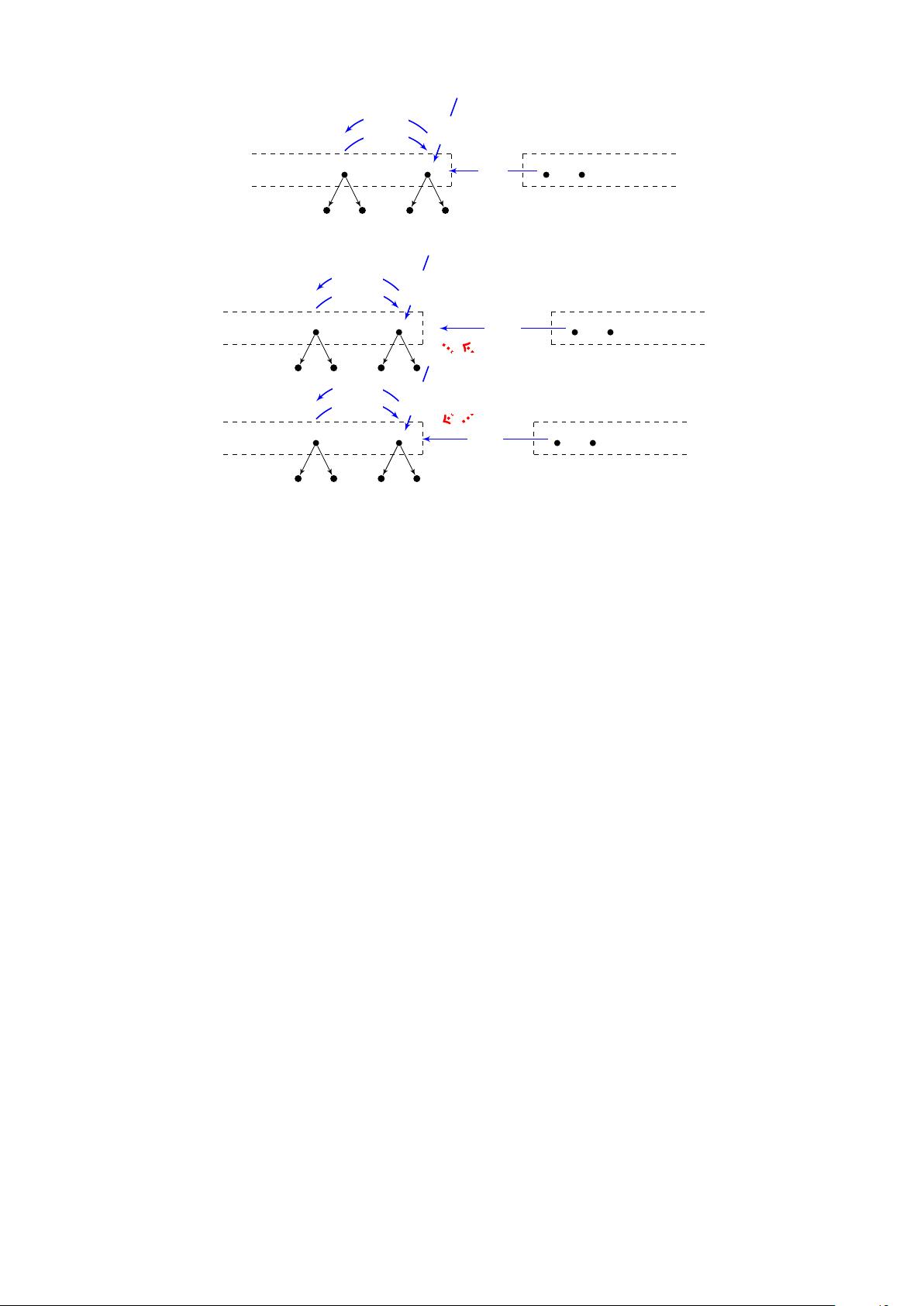
Figure 2: Illustrations for the baseline dependency parsing model and our proposed joint model.
In the baseline arc-standard transition system, we define four kinds of actions, as shown in Figure 2(a).
They are shift (SH), arc-left with dependency label l (AL(l)), arc-right with dependency label l (AR(l))
and pop-root (PR), respectively. The shift action shifts the first element Q
0
of the queue onto the stack;
the action arc-left with dependency label l builds a left arc between the top element S
0
and the second
top element S
1
on the stack, with the dependency label being specified by l; the action arc-right with
dependency label l builds a right arc between the top element S
0
and the second top element S
1
on the
stack, with the dependency label being specified by l; and the pop-root action defines the root node of a
dependency tree when there is only one element on the stack and no element in the queue.
During decoding, each state may have several actions. We employ a fixed beam to reduce the search
space. The low-score states are pruned from the beam when it is full. The feature templates in our
baseline are shown by Table 1, referring to baseline feature templates. We learn the feature weights by
the averaged percepron algorithm with early-update (Collins and Roark, 2004; Zhang and Clark, 2011).
3 The Proposed Joint Model
The aforementioned baseline model can only handle a single dependency tree. In order to parse multiple
dependency trees for a sentence, we usually use individual dependency parsers. This method is not
able to exploit the correlations across different dependency schemes. The joint model to parse multiple
dependency trees with a single model is an elegant way to exploit these correlations fully. Inspired by
this, we make a novel extension to the baseline arc-standard transition system, arriving at a joint model
to parse two heterogeneous dependency trees for a sentence simultaneously.
In the new transition system, we double the original transition state of one stack and one queue into
two stacks and two queues, as shown by Figure 2(b). We use stacks S
a
and S
b
and queues Q
a
and Q
b
to save partial-parsed dependency trees and unprocessed words for two schemes a and b, respectively.
Similarly, the transition actions are doubled as well. We have eight transition actions, where four of them
are aimed for scheme a, and the other four are aimed for scheme b. The concrete action definitions are
similar to the original actions, except an additional constraint that actions should be operated over the
corresponding stack and queue of scheme a or b.
We assume that the actions to build a specific tree of scheme a are A
a
1
A
a
2
· · · A
a
n
, and the actions to
532
剩余10页未读,继续阅读
2008-11-09 上传
2021-02-21 上传
2021-02-21 上传
2019-08-09 上传
2021-05-13 上传
2016-04-13 上传
2011-06-30 上传
2020-03-12 上传
2021-05-14 上传

weixin_38570296
- 粉丝: 5
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
