深度学习基石:CS231n神经网络笔记2-数据预处理与模型设定
需积分: 0 42 浏览量
更新于2024-08-05
收藏 1.43MB PDF 举报
"这篇是斯坦福大学CS231n课程关于神经网络的笔记第二部分,主要涵盖了数据预处理、权重初始化、批量归一化、正则化、损失函数等关键概念。译者对原文进行了翻译和校对,旨在帮助读者深入理解神经网络的构建和优化方法。"
在神经网络的学习中,数据预处理是一个至关重要的步骤,因为它能显著影响模型的训练效果和收敛速度。预处理通常包括三个主要方法:
1. **均值减法**:这是最常见的数据预处理方式,通过减去每个特征的平均值,使数据集的均值为零。这有助于减少数据的中心偏移,使得数据云更接近原点。在Python的numpy库中,可以使用`X -= np.mean(X, axis=0)`来实现这一操作。对于图像数据,通常会全局减去图像的平均像素值,或者按颜色通道分别减去。
2. **归一化**:归一化的目标是让数据的各个维度具有相似的尺度。有两种常见的方法:
- **零中心化后标准化**:首先进行均值减法,然后除以标准差,使得每个维度的数据分布接近标准正态分布。代码实现为`X /= np.std(X, axis=0)`。
- **范围归一化**:将每个特征的值缩放到[1, -1]之间,适用于不同特征具有不同数值范围的情况。这种归一化可能在图像数据中不那么必要,因为像素值通常在0-255之间。
数据预处理的重要性在于,合适的预处理可以提高模型的泛化能力,降低训练难度,以及帮助优化算法更快地找到全局最优解。此外,笔记还提到了其他与模型设计相关的技术:
- **权重初始化**:初始化权重对于神经网络的训练至关重要,因为不当的初始权重可能导致梯度消失或梯度爆炸。不同的初始化策略如Xavier初始化或He初始化可以根据激活函数的性质来选择。
- **批量归一化(Batch Normalization)**:批量归一化在每一层的激活函数之后进行,通过规范化内部层的输出,加速训练并提高模型的稳定性和性能。
- **正则化**:正则化是防止过拟合的手段,包括L1和L2正则化、最大范数限制以及Dropout。这些方法在损失函数中添加惩罚项,限制模型复杂度,促进泛化能力。
- **损失函数**:损失函数衡量模型预测与实际标签之间的差异,如交叉熵损失用于多类分类,均方误差用于回归问题。选择适当的损失函数对模型优化至关重要。
这些技术和方法构成了神经网络训练的核心组成部分,理解和应用它们是构建高效、稳健的神经网络模型的关键。
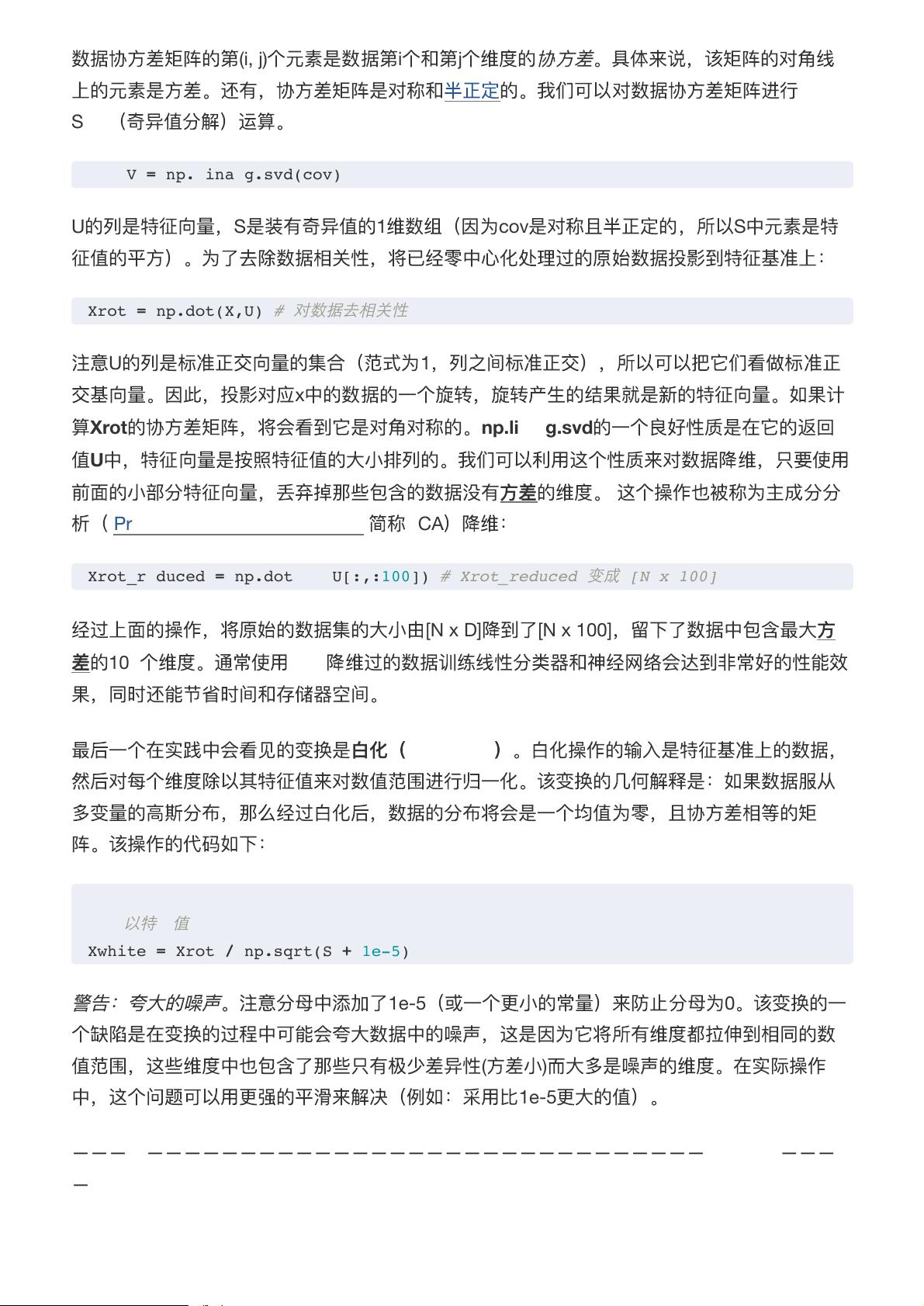
数据
协
方
差
矩
阵
的
第
(i, j)
个
元
素
是
数据
第
i
个
和
第
j
个
维
度
的
协
方
差
。
具
体
来
说
,
该
矩
阵
的
对
角
线
上
的
元
素
是
方
差
。
还
有
,
协
方
差
矩
阵
是
对
称
和半
正
定
的
。
我
们
可
以
对
数据
协
方
差
矩
阵
进
行
SVD
(
奇
异
值
分
解
)
运
算
。
U,S,V = np.linalg.svd(cov)
U
的
列
是
特
征
向
量
,
S
是
装
有
奇
异
值
的
1
维
数
组
(
因
为
cov
是
对
称
且
半
正
定
的
,
所
以
S
中
元
素
是
特
征
值
的
平
方
)
。
为了
去
除
数据
相
关
性
,
将已
经
零
中
心
化
处
理
过
的
原
始
数据
投
影
到
特
征
基
准
上:
Xrot = np.dot(X,U) #
对数据去相关性
注
意
U
的
列
是标
准
正
交
向
量
的
集
合
(
范
式
为
1
,
列
之
间
标
准
正
交
),
所
以
可
以
把
它
们
看
做
标
准
正
交
基
向
量
。
因
此
,
投
影
对
应
x
中
的
数据
的
一个
旋
转
,
旋
转
产
生
的
结
果
就
是
新
的
特
征
向
量
。
如
果
计
算
Xrot
的
协
方
差
矩
阵
,
将
会
看
到
它
是
对
角
对
称
的
。
np.linalg.svd
的
一个
良
好
性
质
是
在
它
的
返
回
值
U
中
,
特
征
向
量
是
按
照特
征
值
的
大
小
排
列
的
。
我
们
可
以
利
用
这
个
性
质
来
对
数据
降
维
,
只
要
使
用
前
面
的
小
部
分
特
征
向
量
,丢
弃
掉
那
些
包
含
的
数据
没
有
方
差
的
维
度
。
这
个
操
作也
被
称
为主
成
分分
析
(
Principal Component Analysis
简称
PCA
)
降
维
:
Xrot_reduced = np.dot(X, U[:,:100]) # Xrot_reduced
变成
[N x 100]
经
过
上
面
的
操
作
,
将
原
始
的
数据
集
的
大
小
由
[N x D]
降
到
了
[N x 100]
,
留
下
了
数据
中
包
含
最
大
方
差
的
100
个
维
度
。
通
常
使
用
PCA
降
维
过
的
数据
训
练线
性
分
类
器
和
神
经网络
会
达
到
非
常
好
的
性
能
效
果
,
同
时
还
能
节
省
时
间
和
存
储
器
空
间
。
最
后
一个
在
实
践
中会
看
见
的
变
换
是
白
化
(
whitening
)
。
白
化
操
作
的
输
入
是
特
征
基
准
上
的
数据
,
然
后
对
每
个
维
度
除
以
其
特
征
值
来
对
数
值
范
围
进
行
归
一
化
。
该
变
换
的
几
何
解
释
是
:
如
果
数据
服
从
多
变
量
的
高
斯
分
布
,
那
么
经
过
白
化
后
,
数据
的
分
布将
会
是
一个
均
值
为
零
,且
协
方
差
相
等
的矩
阵
。
该
操
作
的
代
码
如
下:
#
对数据进行白化操作
:
#
除以特征值
Xwhite = Xrot / np.sqrt(S + 1e-5)
警
告
:
夸大
的
噪
声
。
注
意
分
母
中
添
加
了
1e-5
(
或
一个
更
小
的
常
量
)
来
防
止
分
母
为
0
。
该
变
换
的
一
个
缺
陷
是
在
变
换
的
过
程
中
可
能
会
夸大
数据
中
的
噪
声
,
这
是
因
为
它将
所
有
维
度
都
拉
伸
到
相
同
的
数
值
范
围
,
这
些
维
度
中也
包
含
了
那
些
只
有极
少差
异性
(
方
差小
)
而
大多
是
噪
声
的
维
度
。
在
实
际
操
作
中
,
这
个
问题
可
以
用
更
强
的
平
滑
来
解
决
(
例
如
:
采
用
比
1e-5
更
大
的
值
)
。
—————————————————————————————————————————
—
剩余13页未读,继续阅读
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传

高中化学孙环宇
- 粉丝: 15
- 资源: 338
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
