"云平台并行数据挖掘算法研究与应用:基于密度的聚类算法的并行化改进"
版权申诉
38 浏览量
更新于2024-03-04
收藏 2.54MB PDF 举报
随着信息技术的不断创新,数据已然呈现出爆炸式增长的态势,互联网产业正面临着从 IT 到 DT 的巨大转变。如何提高挖掘海量数据背后所隐藏知识的能力,成为现阶段的一个难题。分布式计算架构的出现为海量数据挖掘提供了新的解决方案,将传统的数据挖掘算法迁移到云平台进行并行化改进,可使得处理数据的效率大大提高。本文从传统的数据挖掘算法无法应对海量数据挖掘的缺陷出发,研究了现阶段较为热门的开源分布式并行计算框架如 Hadoop、Spark 等,然后将传统的数据挖掘算法进行并行化改进,并将其移植到云平台上,利用云平台提升数据挖掘算法的计算能力,使之具有良好的可扩展性。
主要工作有以下几个方面:首先,基于密度的聚类算法 DBSCAN 的并行化改进。现有的并行 DBSCAN 算法在进行数据分区时,通常是将原始数据库划分为若干个互不相交的子空间,随着数据维度的增加,对高维空间的切分与合并将消耗大量的时间。针对这一问题,本文提出了改进的并行基于密度的聚类算法(S_DBSCAN),并在 Spark 上进行具体实现。经实验表明,改进的 S_DBSCAN 算法在保证一定正确聚类结果的同时,具有较高的计算效率和速度。其次,本文还探讨了基于云平台的数据挖掘并行算法在实际应用中的效果。
在实际应用中,基于云平台的数据挖掘并行算法可以应用于各种领域,例如金融、医疗、电商等。通过并行化改进,可以更加高效地挖掘海量数据中的信息,为企业决策提供更加准确的数据支持。同时,基于云平台的数据挖掘算法还具有良好的扩展性和灵活性,可以根据不同的需求进行定制化开发,满足不同行业的需求。
总的来说,基于云平台的数据挖掘并行算法是在当前信息技术快速发展的背景下应运而生的一种解决方案。通过将传统的数据挖掘算法与分布式计算框架相结合,可以有效提高数据挖掘的效率和精确度,为企业提供更好的数据分析和决策支持。未来随着云计算和大数据技术的不断发展,基于云平台的数据挖掘并行算法将会得到更广泛的应用和进一步的优化,为各行各业带来更多的创新和发展机遇。
第二章
相关知识介绍
7
第二章 相关知识介绍
2.1
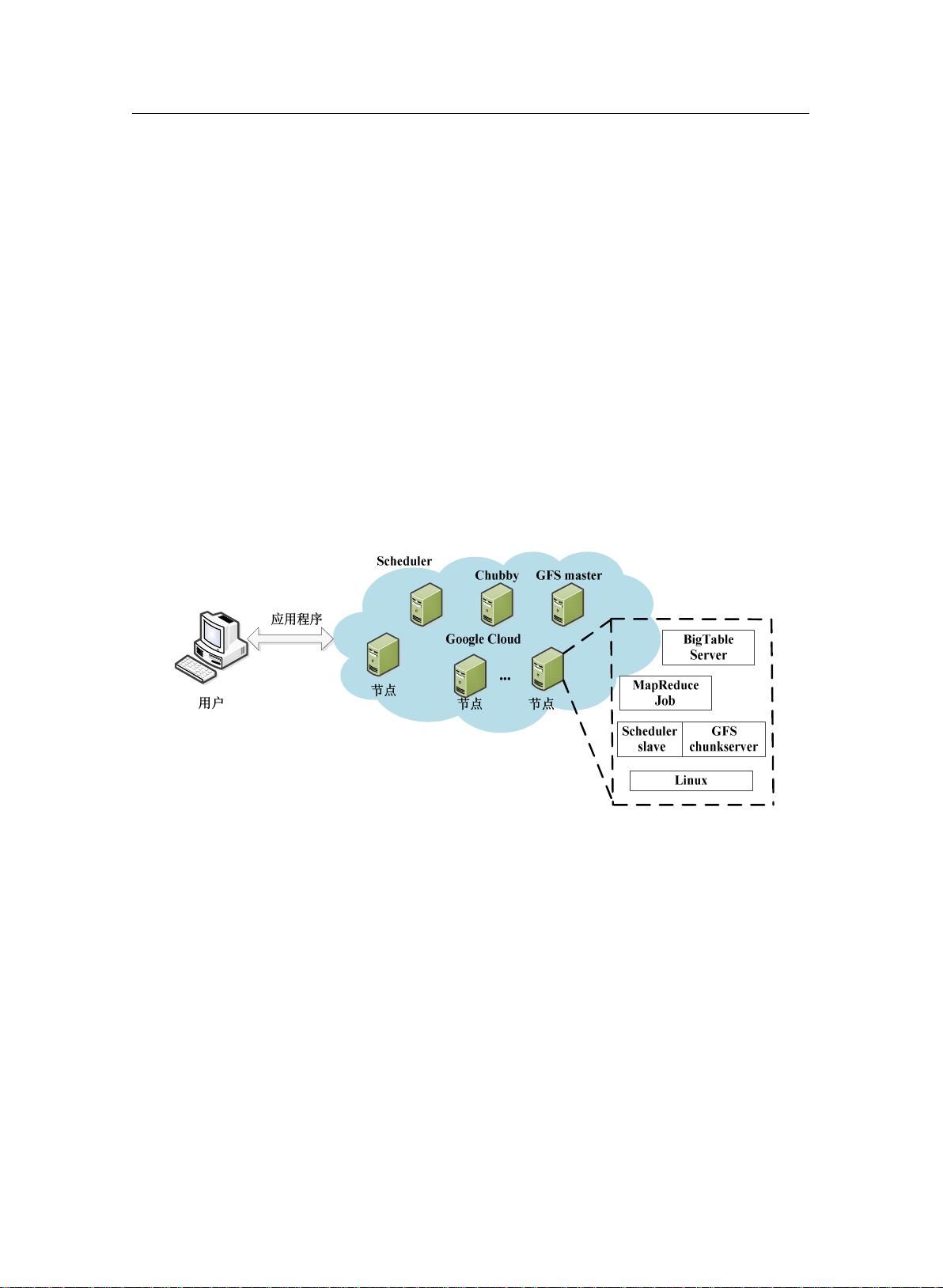
现有云平台概述
云计算
[3][4]
为用户提供海量数据的存储与计算服务,同时,用户可以在不了解
云计算底层实现、没有相关知识储备、没有设备操作能力的条件下,通过互联网
按需获取服务。云计算提供了从基础设施、平台服务到软件服务的三层服务类型,
分别为
IaaS
、
PaaS
以及
SaaS
。随着云计算技术的广泛应用,各大型互联网公司
也相继推出自主研发的云平台产品,比如
IBM
蓝云计算平台、亚马逊云计算平台、
Google
云平台等。此外,本节还将介绍由
Apache
基金会所开发的开源分布式计算
架构
Hadoop
,以及介绍基于云平台的
Hadoop
。
2.1.1
亚马逊云平台
亚马逊
[8]
是互联网上最大的在线零售商,每日在线交易量不计其数。因此,亚
马逊为独立开发人员以及开发商提供了云计算服务平台,并将其命名为弹性计算
云(
EC2
)。它最早为用户提供了远程云计算服务,用户能够通过
Elastic Compute
Cloud
的
Network UI
去操作每个实例,收费的方式是按使用量收费。用户数据的
安全一般是通过
HTTPS
协议来保障的,内部实例的交互可以通过客户端使用
SOAP over HTTPS
协议来确保。以用户的角度来看,
Elastic Compute Cloud
为用户
提供了基于虚拟机的灵活的集群环境,将用户从繁重的平台维护工作中解放了出
来。
Elastic Compute Cloud
架构如图
2-1
所示。
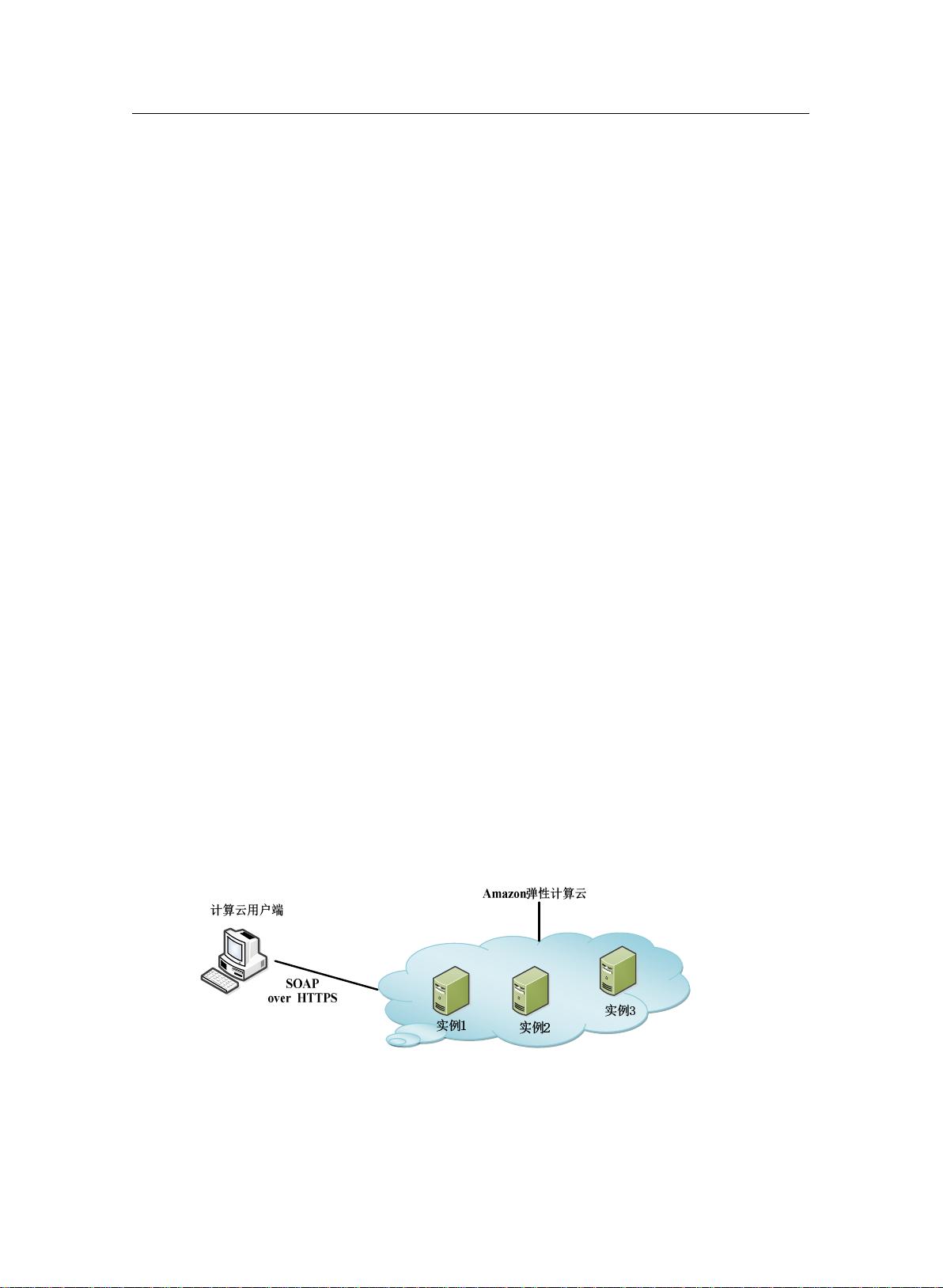
图
2-1
亚马逊弹性计算架构图
由图
2-1
所示,
Elastic Compute Cloud
中,在云端运行着的每台虚拟机都代表
万方数据

剩余81页未读,继续阅读
2021-07-14 上传
115 浏览量
2021-07-14 上传
2021-07-14 上传
126 浏览量
2021-07-14 上传

programyp
- 粉丝: 90
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
