Impala与HDFS交互:数据访问与优化揭秘
112 浏览量
更新于2024-08-28
收藏 510KB PDF 举报
"Impala是一个面向大规模数据分析的高性能OLAP引擎,它不直接存储数据,而是通过与HDFS、HBase、Kudu等第三方存储引擎交互来处理数据。Impala支持多种文件格式,如Parquet、TEXT、avro和sequencefile,但对HDFS文件的更新操作支持有限。本文重点探讨了Impala访问HDFS的三个主要方面:数据查询、数据插入和数据操作,并深入分析了Impala在查询执行过程中如何从HDFS获取数据,特别是HdfsScanNode的实现。
数据分区在Impala的高效运行中起着关键作用。在查询执行的前端,查询会被解析并转化为物理执行计划,然后分割成多个Fragment。这些Fragment会根据数据的本地性原则被分配到与DataNode相同机器上的Impalad节点执行,以最大化I/O效率。Impala需要知道每个文件的具体存储位置,以便正确地分配任务。这一过程涉及到Catalogd节点,它维护整个系统的元数据,包括表、分区和文件位置等信息。
Impala的元数据结构层次分明,每个表包含分区信息,而分区又包含了具体的文件信息。当Impala执行查询时,它首先通过Catalogd获取表和分区的元数据,然后根据这些信息确定数据的分布情况,将Fragment有效地分配到各个后端Impalad节点。每个节点会负责处理一部分数据分片,实现并行计算。
在数据查询阶段,Impala的HdfsScanNode是数据读取的关键组件。HdfsScanNode直接与HDFS交互,读取特定文件格式的数据。对于Parquet这种列式存储格式,Impala能充分利用其特性,如列存压缩和预过滤,从而大大提高查询性能。此外,Impala还利用数据的局部性,尽可能让数据读取发生在数据实际存储的节点上,减少网络传输,进一步提升查询速度。
在数据写入(插入)方面,Impala支持向HDFS上的表插入新数据,但这通常涉及全表扫描或基于分区的插入操作,因为HDFS的更新操作不支持直接修改已有数据块。因此,Impala通常采用批量插入或者在新的数据文件中追加数据。
至于数据操作,如重命名和移动文件,Impala提供了相应的DML语句来支持这些操作,但需要注意的是,这些操作可能会影响到查询计划和元数据的一致性,因此需要谨慎使用。
Impala的高性能主要得益于其优化的查询执行策略、对数据分区的智能利用以及对高效文件格式(如Parquet)的支持。通过对HDFS数据访问的精细控制,Impala能够提供快速的在线分析处理能力,满足大规模数据分析的需求。
Impala高性能探秘之高性能探秘之HDFS数据访问数据访问
Impala是一个高性能的OLAP引擎,Impala本身只是一个OLAP-SQL引擎,它访问的数据存储在第三方引擎中,第三方引擎包
括HDFS、Hbase、kudu。对于HDFS上的数据,Impala支持多种文件格式,目前可以访问Parquet、TEXT、avro、sequence
file等。对于HDFS文件格式,Impala不支持更新操作,这主要限制于HDFS对于更新操作的支持比较弱。本文主要介绍Impala
是如何访问HDFS数据的,Impala访问HDFS包括如下几种类型:1、数据访问(查询);2、数据写入(插入);3、数据操
作(重命名、移动文件等)。底层存储引擎的处理性能直接决定着SQL查询的速度快慢,目前Impala+Parquet格式文件存储
的查询性能做到很好,肯定是有其独特的实现原理的。本文将详细介绍Impala是如何在查询执行过程中从HDFS获取数据,也就
是Impala中HdfsScanNode的实现细节。
数据分区
Impala执行查询的时首先在FE端进行查询解析,生成物理执行计划,进而分隔成多个Fragment(子查询),然后交由
Coordinator处理任务分发,Coordinator在做任务分发的时候需要考虑到数据的本地性,它需要依赖于每一个文件所在的存储
位置(在哪个DataNode上),这也就是为什么通常将Impalad节点部署在DataNode同一批机器上的原因,为了揭开Impala访
问HDFS的面纱需要先从Impala如何分配扫描任务说起。
众所周知,无论是MapReduce任务还是Spark任务,它们执行的之前都需要在客户端将输入文件进行分割,然后每一个Task
处理一段数据分片,从而达到并行处理的目的。Impala的实现也是类似的原理,在生成物理执行计划的时候,Impala根据数据
所在的位置将Fragment分配到多个Backend Impalad节点上执行,那么这里存在两个核心的问题:
Impala如何获取每一个文件的位置?
如何根据数据位置分配子任务?
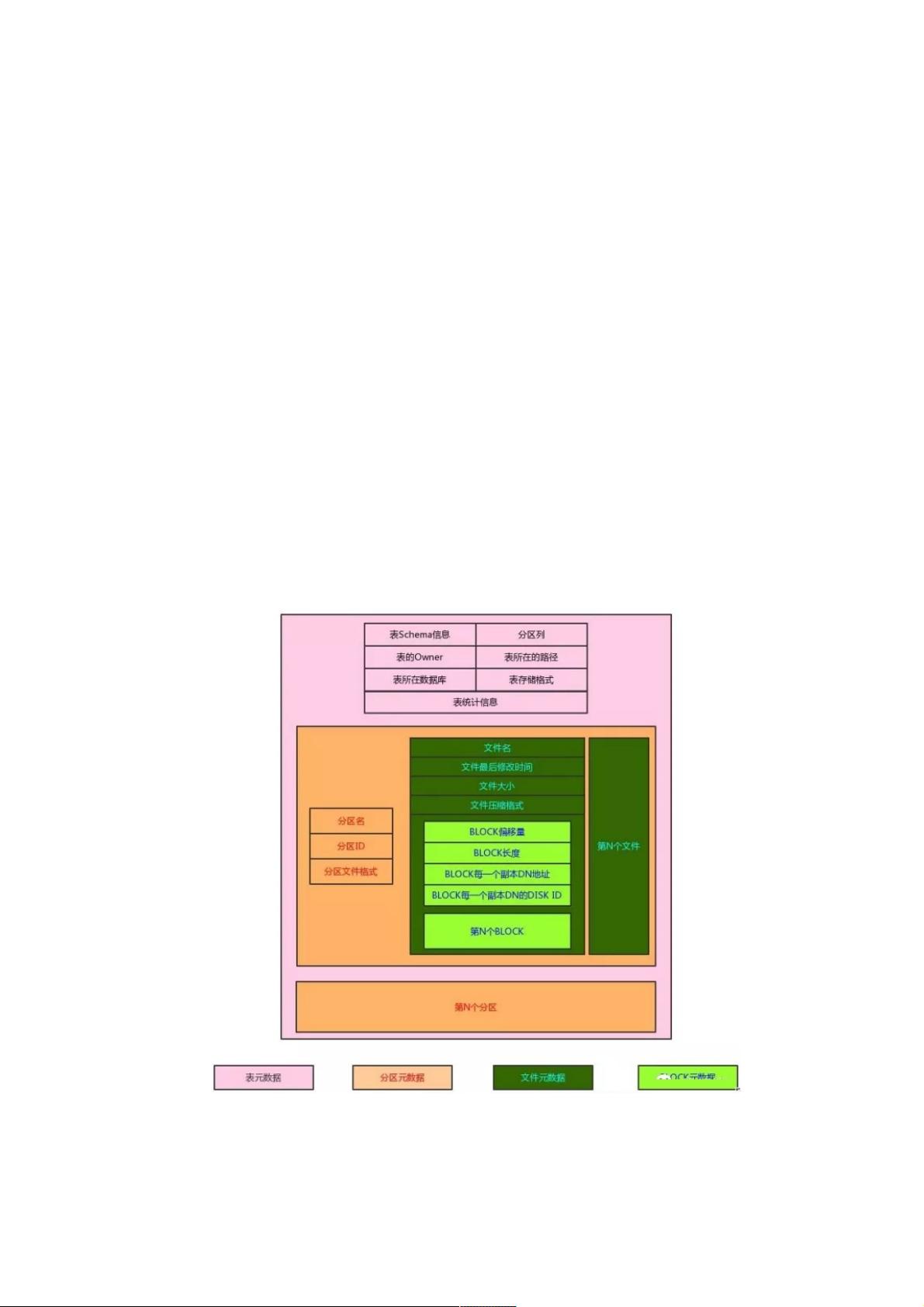
在之前介绍的Impala的总体架构可以看到,Catalogd节点负责整个系统的元数据,元数据是以表为单位的,这些元数据具有一
个层级的关系,如下图所示
Impala表元数据结构
每一个表包含如下元数据(只选取本文需要用到的):
1.schema信息:该表中包含哪些列,每一列的类型是什么等
2.表属性信息:拥有者、数据库名、分区列、表的根路径、表存储格式。
3.表统计信息:主要包括表中总的记录数、所有文件总大小。
下载后可阅读完整内容,剩余5页未读,立即下载

weixin_38557670
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- React.js实现的简单HTML5文件拖放上传组件
- iReport:强大的开源可视化报表设计器
- 提升代码整洁性:Eclipse虚线对齐插件指南
- 迷你时间秀:个性化系统时间显示与管理工具
- 使用ruby-install一次性安装多种Ruby版本
- Logality:灵活自定义的JSON日志记录器
- Mogre3D游戏开发实践教程免费分享
- PHP+MySQL实现的简单权限账号管理小程序
- 微信支付统一下单签名错误排查与解决指南
- 虚幻引擎4实现的多边形地图生成器
- TouchJoy:专为触摸屏Windows设备打造的屏幕游戏手柄
- 全方位嵌入式开发工具包:ARM平台必备资源
- Java开发必备:30个实用工具类全解析
- IBM475课程资料深度解析
- Java聊天室程序:全技术栈源码支持与学习指南
- 探索虚拟房屋世界:house-tour-VR应用体验
