TensorFlow自然语言处理:词向量模型Word2vec详解
需积分: 0 81 浏览量
更新于2024-08-05
收藏 2.21MB DOCX 举报
神经网络Tensorflow基础(七)
本篇文章主要讲解了自然语言处理中词向量模型Word2vec的基础知识,包括滑动窗口、CBOW和Skip-gram模型的介绍,以及负采样模型的应用。
1. 自然语言处理
自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,旨在让计算机能够理解、处理和生成人类语言。自然语言处理的应用非常广泛,包括文本分类、语言翻译、情感分析等。
2. 词向量模型Word2vec
词向量模型Word2vec是自然语言处理中的一种重要技术,旨在将词语转换为向量形式,以便计算机能够更好地理解和处理语言。Word2vec模型可以将词语转换为高维向量,从而捕捉到词语之间的语义关系。
词向量模型的优点是可以捕捉到词语之间的语义关系,从而提高自然语言处理的准确性。词向量模型的维度通常在50~300维之间,越高的维度可以提供更多的信息,但也增加了计算复杂度。
3. 滑动窗口
滑动窗口是一个非常重要的概念,在词向量模型中,滑动窗口可以用来构建训练数据。滑动窗口的大小可以自己指定,通常取值为5~10。滑动窗口可以将文本数据分割成固定长度的窗口,从而生成训练数据。
4. 不同模型:CBOW与Skip-gram
CBOW(Continuous Bag-of-Words)模型和Skip-gram模型是两种常见的词向量模型。CBOW模型根据上下文来推断单个词,而Skip-gram模型根据所给词来推断上下文。两种模型都可以用来训练词向量模型,但它们的应用场景和优缺点不同。
CBOW模型可以捕捉到词语之间的上下文关系,适合用于文本分类、语言翻译等应用场景。但是,CBOW模型的计算复杂度较高,训练时间较长。
Skip-gram模型可以捕捉到词语之间的语义关系,适合用于信息检索、文本summarization等应用场景。但是,Skip-gram模型的计算复杂度较高,需要大量的训练数据。
5. 负采样模型
负采样模型是词向量模型的改进版本,旨在提高词向量模型的训练速度和准确性。负采样模型可以通过添加一些标签为0的数据集来改进词向量模型的训练过程。
在词向量模型的训练过程中,需要初始化词向量矩阵,然后通过神经网络反向传递来计算并更新参数。在递归神经网络的反向传播过程中,既要更新权重参数,又要更新输入数据。
词向量模型的训练过程可以分为两步:第一步是初始化词向量矩阵,第二步是通过神经网络反向传递来计算并更新参数。在训练过程中,可以添加一些标签为0的数据集来改进词向量模型的训练速度和准确性。
本篇文章主要讲解了自然语言处理中词向量模型Word2vec的基础知识,包括滑动窗口、CBOW和Skip-gram模型的介绍,以及负采样模型的应用。这些技术可以用于各种自然语言处理应用场景,例如文本分类、语言翻译等。
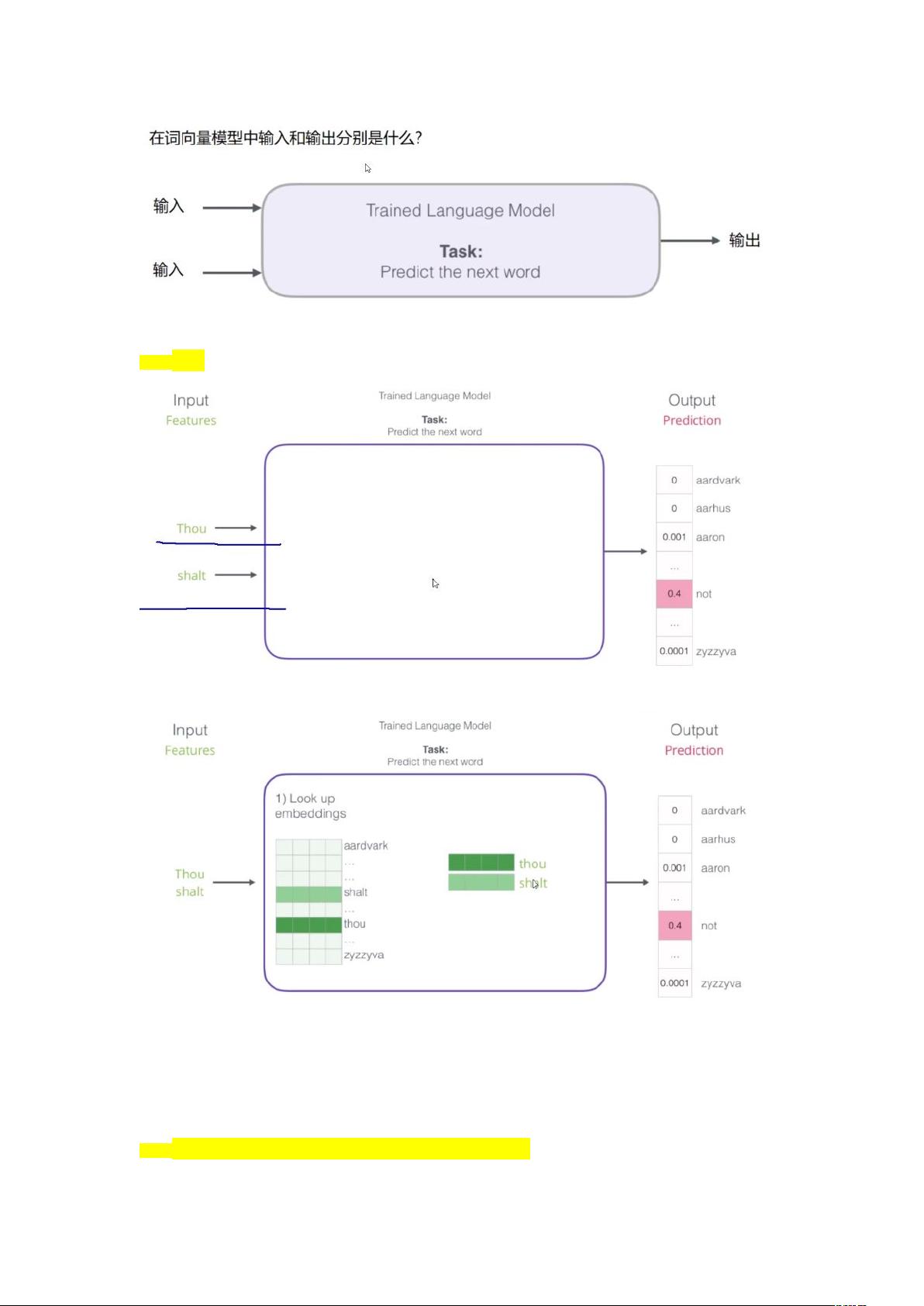
模型
其中 embeddings look up 为一个词表。
在词表更新时,与其相关的权重参数矩阵会发生改变,同时输入也会改变。、
数据的来源(跨区域、跨文本):语序正常的文本
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-02-03 上传
2022-03-27 上传
2022-01-29 上传
2022-01-30 上传
2022-01-28 上传

LCH
- 粉丝: 102
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
