Linux下Hadoop 2.0集群搭建详解及关键配置
需积分: 14 161 浏览量
更新于2024-07-20
收藏 5.1MB PDF 举报
本文档详细介绍了如何在Linux环境下搭建Hadoop集群,并辅以VMware Workstation进行虚拟机操作。整个过程分为六个章节,依次为:
1. **Hadoop 2.0 安装准备**:首先介绍了在VMware Workstation 10上安装CentOS 6.10系统,包括系统安装、常见问题解决,以及在Windows中安装SSH客户端用于远程连接。
2. **CentOS 6.10系统配置**:在虚拟机中进行具体配置,如软件包和数据包安装,确保时钟同步、主机名设置、网络环境配置、防火墙管理、hosts文件调整、JDK安装、免密钥登录配置等。
3. **Hadoop 配置与部署**:详细讲解了Hadoop核心组件的安装和配置过程,包括hadoop-env.sh和yarn-env.sh环境变量的配置,以及core-site.xml、hdfs-site.xml、yarn-site.xml和mapred-site.xml等关键配置文件的编辑。还涉及在master节点设置slaves文件,以及在从节点复制配置和启动集群。
4. **Hive 安装与配置**:介绍Hive的安装步骤,包括解压安装、MySQL的配合安装与配置,以及Hive本身的配置和启动验证。
5. **HBase 配置与安装**:同样是从解压安装开始,重点在于环境变量和配置文件的修改,如hbase-env.sh和hbase-site.xml,以及设置regionservers。此外,还有HBase服务的启动和验证。
6. **Mahout 安装部署**:虽然文档没有详细列出Mahout的安装步骤,但可以推测这部分内容可能会介绍Mahout(一个基于Hadoop的数据挖掘工具)的安装和配置,作为整个大数据处理平台的扩展。
在整个过程中,作者强调了每一步骤的重要性,并提供了具体的指导,以确保读者能够成功搭建出一个功能完整的Hadoop集群,同时具备Hive和HBase这样的数据处理和存储能力。对于想要学习或从事大数据分析的人来说,这是一份非常实用的教程。
第 2 章 VMware 10 安装 CentOS 6
13
直接等待安装完成,系统自动重启
输入密码 zkpk 登录进系统
至此,CentOS 系统安装完毕。
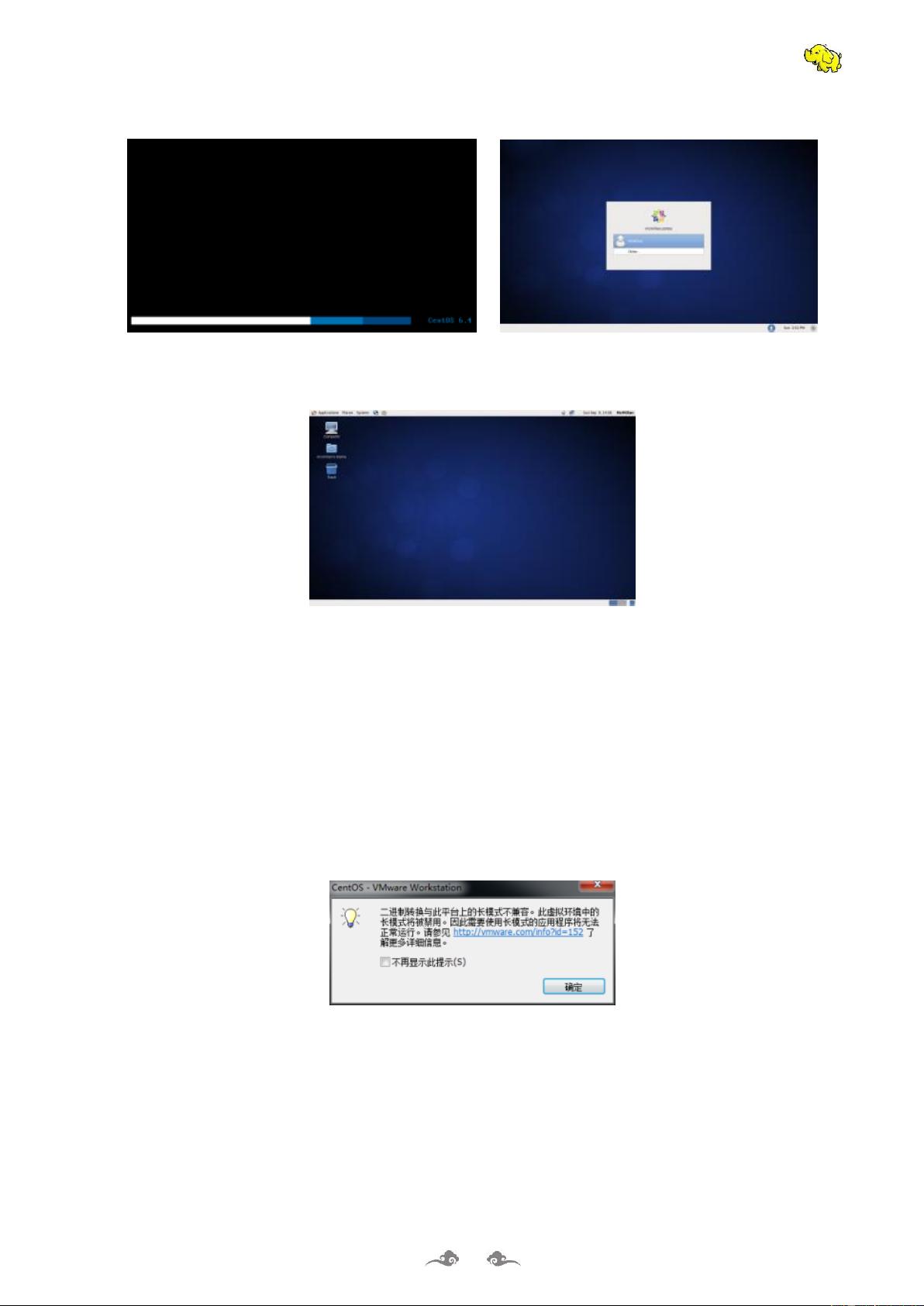
2.2 安装中的关键问题
如果出现下面的界面,说明 BIOS 中没有打开 VT-x 功能,所以就不能用 VT-x 进行加速。
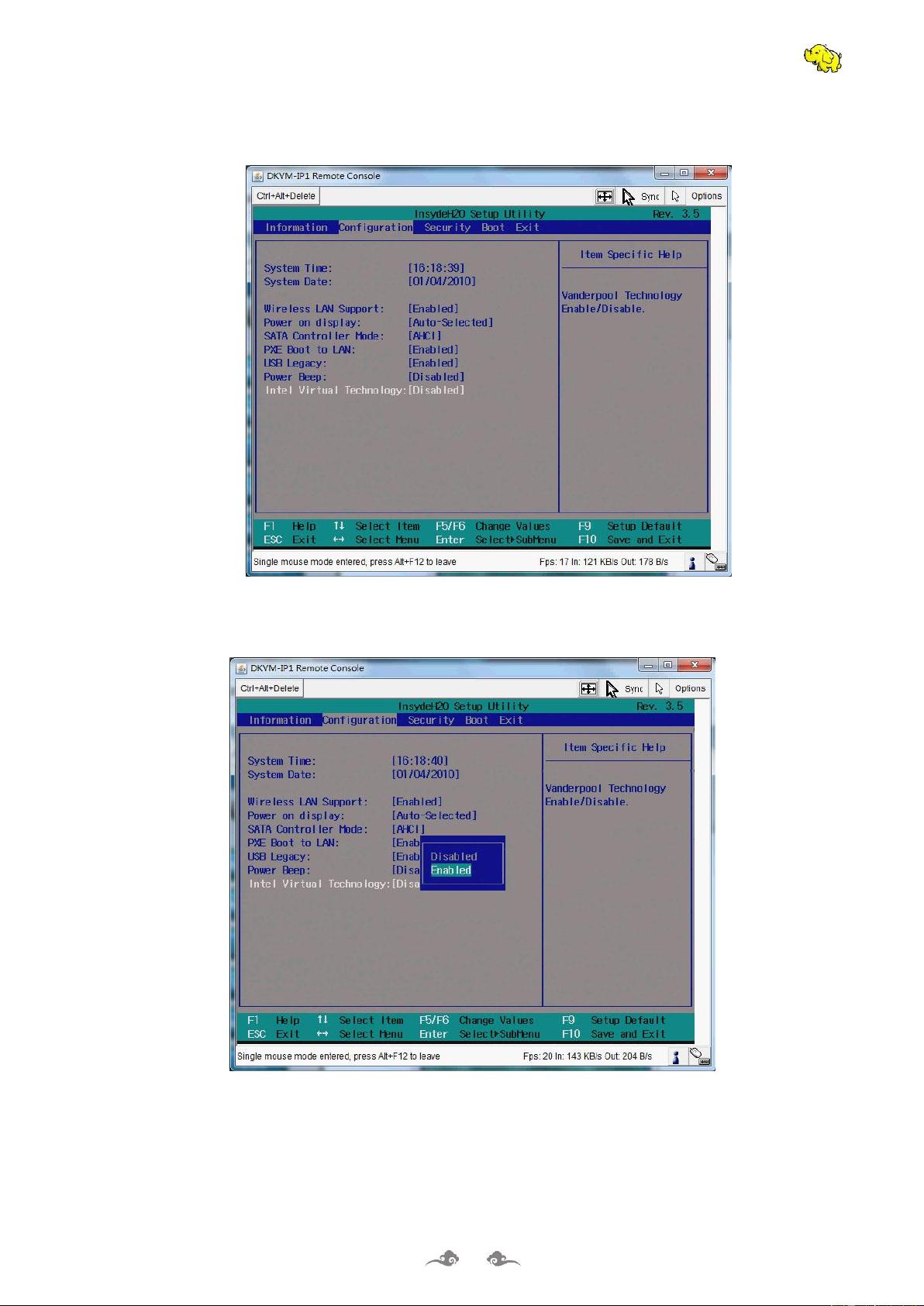
打开 BIOS 中的 VT-x 功能的操作如下:
首先在开机自检 Logo 处按 F2 热键(不同品牌的电脑进入 BIOS 的热键不同,有的电脑是 F1\F8\F12)
进入 BIOS,选择 Configuration 选项,选择 Intel Virtual Technology 并回车,如下图:

剩余73页未读,继续阅读
361 浏览量
199 浏览量
250 浏览量
239 浏览量
188 浏览量
111 浏览量
2024-10-12 上传

傲娇的芒果冰激凌
- 粉丝: 4
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Docker的Vue应用部署指南
- 仿北京三甲医院wap网站模板开发教程与源码
- 实用基业长青管理资源深度解读
- cwver:使用日历周版本格式的命令行版本控制工具
- Python实现本地文件高效搜索整理技术解析
- oVirt VM Portal:轻量级UI实现标准用户虚拟机管理
- 货币单位mu:标准化与计算新规范
- Linux平台C/C++编程基础及源码调试指南
- 王永庆商战实录:21世纪商业管理的实践指南
- 中国万方B2B商务系统v3.0全技术栈源码分享
- MERN Stack电子商务平台开发详解:WonderSoft应用案例
- FPGA开发板ACM8211与AC609摄像头数据传输实验指南
- Apollo平台构建VIP应用平台解决方案指南
- STM32F407数字信号发生器设计与实现
- 21世纪实用能力素质的13条必备法则
- 纯JavaScript计时器网络应用实现指南
