深入理解Apache Kafka:分布式消息系统详解
需积分: 0 182 浏览量
更新于2024-08-05
收藏 2.31MB PDF 举报
"Kafka知识汇总 18道1"
Apache Kafka 是一个高性能、分布式的发布-订阅消息系统,同时也是一种强大的消息队列。它设计用于处理大规模的数据流,并有效地在不同系统之间传递消息。Kafka 的核心特性包括其持久化消息存储、数据复制以确保高可用性,以及与ZooKeeper的集成以实现集群管理和协调。
Kafka 的关键依赖是ZooKeeper,这是一个分布式协调服务,它帮助Kafka管理集群状态和选举控制器。控制器是Kafka集群中的主节点,负责监控和管理其他从节点。当Kafka服务器启动时,它们会在ZooKeeper中注册,控制器则通过ZooKeeper的监听机制获取集群的元数据信息,并广播给其他服务器。
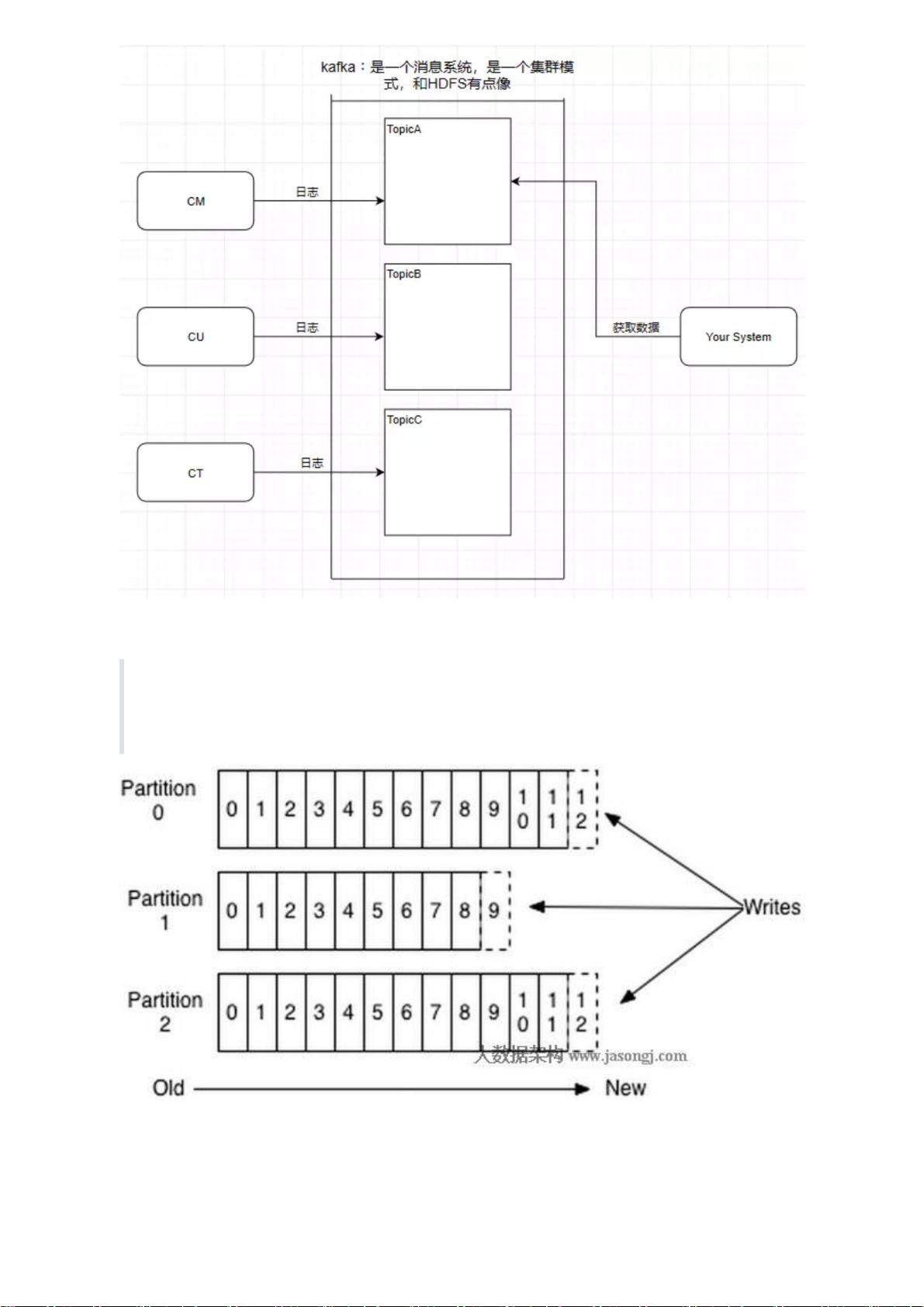
在Kafka的架构中,Topic是消息的基本单位,类似于传统消息队列中的Queue。一个Topic可以被分割成多个Partition,这些Partition分布在不同的Broker上,以实现负载均衡和高可用性。Partition内部的消息是有序的,这意味着在同一分区内的消息消费是按照顺序进行的。
Producer负责发送消息到Kafka,它会根据消息的key和Partition数量进行哈希计算,决定消息投递到哪个Partition。而Consumer则从Kafka的Leader Partition中消费消息。每个Partition有一个Leader和多个Follower Replica,其中Leader接收生产和读取请求,Follower则负责复制Leader的数据。
Replica是Partition的备份,确保在Leader故障时能够接管。每个Partition的Replica集合中,有一个是Leader,其余是Follower。Leader维护一个叫做ISR (In-Sync Replicas) 的列表,包含那些与它保持同步的Follower。如果Leader失效,ZooKeeper会协助选举一个新的Leader,通常是ISR列表中的一个Follower。
Kafka还支持Consumer Group的概念,允许多个Consumer协同工作,共同消费一个Partition中的消息。但是,一个Partition只能被同一组内的一个Consumer消费,确保了分区内消息的顺序性。
Kafka特别适合离线和在线消息处理,与Apache Storm和Spark等实时数据处理框架集成良好,可以用于实时流式数据分析。由于其日志顺序写入的特性,Kafka提供了高效的消息回溯和高性能的读写操作。
Kafka是一个强大且灵活的工具,适用于大数据传输、实时流处理和系统间通信,尤其在需要处理大量实时数据的场景下表现出色。其设计的高可扩展性和容错性使得它成为现代大数据生态系统中的重要组成部分。
剩余13页未读,继续阅读
2023-04-20 上传
2023-04-08 上传
2021-01-07 上传
2023-04-24 上传
2020-05-13 上传
2021-05-14 上传
2023-06-15 上传
2021-08-18 上传

邢小鹏
- 粉丝: 33
- 资源: 327
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
