数据挖掘算法全览:Python实现与案例分析
需积分: 37 106 浏览量
更新于2024-07-17
6
收藏 4.64MB PDF 举报
"常用数据挖掘算法总结及Python实现"
这篇文档是关于数据挖掘算法的全面总结,适合初学者,特别是对Python实现有兴趣的学习者。它分为八大部分,涵盖了从数学基础到实际应用的广泛主题。
在第一部分,文档介绍了数据挖掘与机器学习的数学基础,包括统计学的基本概念,如样本空间、事件、概率论定义,这些都是理解机器学习算法的基础。此外,还讨论了探索性数据分析(EDA),这对于理解数据和发现模式至关重要。
第二部分概述了机器学习,进一步深入探讨了机器学习的基本概念。
第三部分专注于监督学习,详细讲解了几种常见的分类和回归算法。KNN(k-最近邻)是一种基于实例的学习,通过找到训练集中最接近新样本的k个点来进行分类或回归。决策树是一种直观的算法,通过构建树状模型来做出决策。朴素贝叶斯分类利用贝叶斯定理,假设特征之间相互独立。Logistic回归用于二分类问题,通过Sigmoid函数将连续值转换为概率。SVM(支持向量机)是另一种分类器,通过找到最大边距超平面将数据分开。集成学习,如AdaBoost、Random Forest等,通过组合多个弱分类器形成强分类器。
第四部分涉及非监督学习,讲解了聚类和关联分析。K-means是一种常用的聚类算法,用于将数据分配到k个不同的群组。Apriori算法则用于关联规则学习,发现项集之间的频繁模式。
第五部分介绍了Python数据预处理,包括数据分析基础和数据清洗技术,这是实际项目中非常关键的步骤。
第六部分涉及数据结构与算法,简要讨论了二叉树的遍历和基本排序方法,这对于理解算法效率至关重要。
第七部分涵盖了SQL基础知识,这对于从数据库中提取和操作数据是必要的。
最后,第八部分提供了四个实际的数据挖掘案例,包括泰坦尼克号生存率分析、飞机坠毁分析、贷款预测问题和使用KNN算法预测葡萄酒价格,这些案例帮助读者将理论知识应用于实践中。
整个文档提供了丰富的知识,不仅涵盖了理论,还提供了Python实现,对于希望在数据挖掘领域深入学习的人来说是一份宝贵的资源。
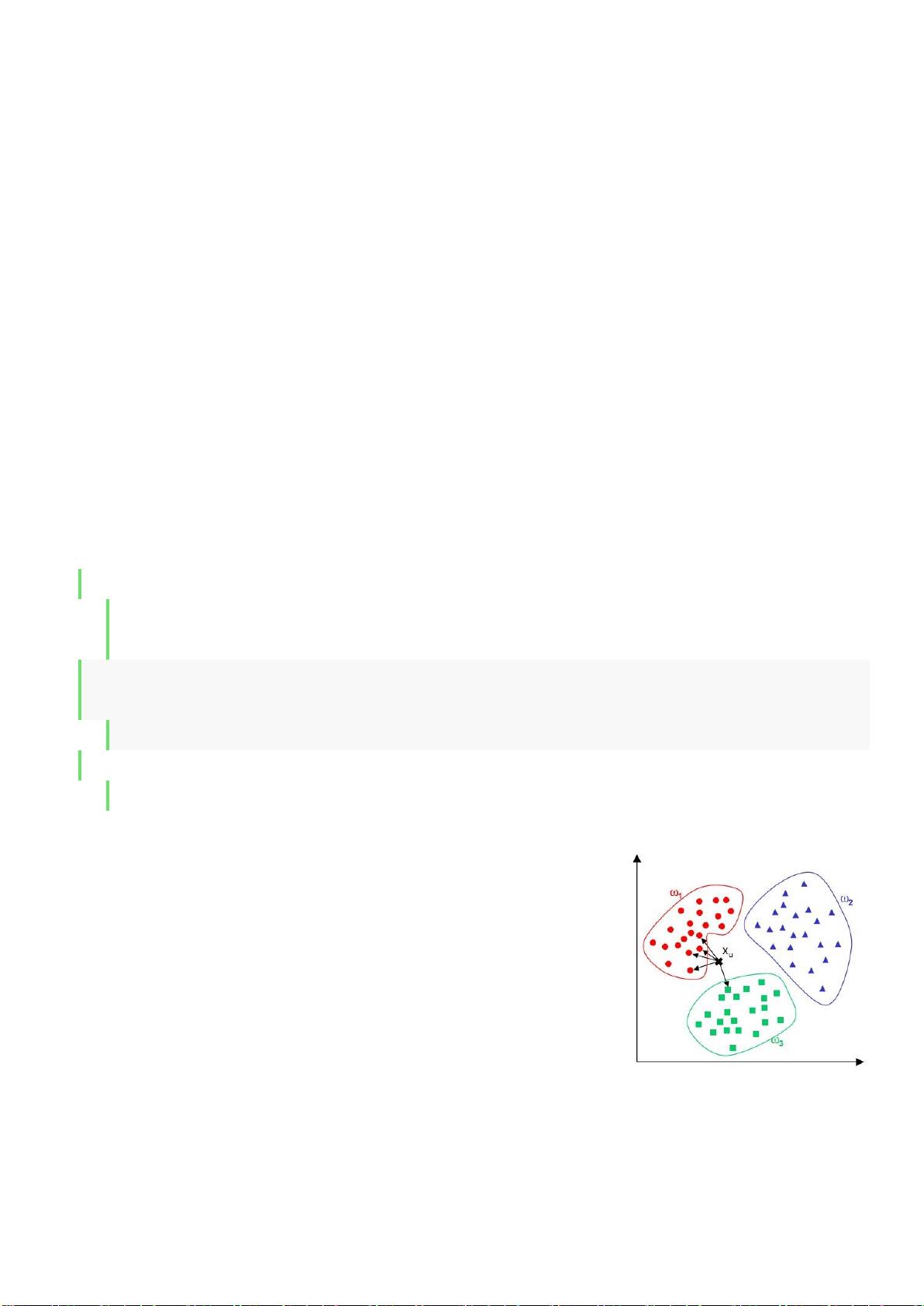
第三部分 监督学习---分类与回归
有监督就是给的样本都有标签,分类的训练样本必须有标签,所以分类算法都是有监督算法。监
督机器学习无非就是“minimize your error while regularizing your parameters”,也就是在规则化参数的
同时最小化误差。最小化误差是为了让我们的训练数据,而规则化参数是防止我们的模型过分拟合我
们的训练数据,提高泛化能力
第四章 KNN(k 最邻近分类算法)
1.算法思路
通过计算每个训练样例到待分类样品的距离,取和待分类样品距离最近的 K 个训练样例,K 个
样品中哪个类别的训练样例占多数,则待分类样品就属于哪个类别
核心思想:如果一个样本在特征空间中的 k 个最相邻的样本中的大多数属于某一个类别,则该样本
也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或
者几个样本的类别来决定待分样本所属的类别。 kNN 方法在类别决策时,只与极少量的相邻样本
有关。由于 kNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,
因此对于类域的交叉或重叠较多的待分样本集来说,kNN 方法较其他方法更为适合。
2.算法描述
1. 算距离:给定测试对象,计算它与训练集中的每个对象的距离
依公式计算 Item 与 D1、D2 … …、Dj 之相似度。得到 Sim(Item, D1)、Sim(Item, D2)… …、
Sim(Item, Dj)。
2. 将 Sim(Item, D1)、Sim(Item, D2)… …、Sim(Item, Dj)排序,若是超过相似度阈值 t 则放入邻居
案例集合 NN。
找邻居:圈定距离最近的 k 个训练对象,作为测试对象的近邻
3. 自邻居案例集合 NN 中取出前 k 名,依多数决,得到 Item 可能类别。
做分类:根据这 k 个近邻归属的主要类别,来对测试对象分类
3.算法步骤
• step.1---初始化距离为最大值
• step.2---计算未知样本和每个训练样本的距离 dist
• step.3---得到目前 K 个最临近样本中的最大距离 maxdist
• step.4---如果 dist 小于 maxdist,则将该训练样本作为 K-最近邻样本
• step.5---重复步骤 2、3、4,直到未知样本和所有训练样本的距离都算完
• step.6---统计 K-最近邻样本中每个类标号出现的次数
• step.7---选择出现频率最大的类标号作为未知样本的类标号
该算法涉及 3 个主要因素:训练集、距离或相似的衡量、k 的大小。
4. k 邻近模型三个基本要素
三个基本要素为
距离度量、
k
值的选择和分类决策规则
距离度量:
设特征空间是 n 维实数向量空间
,
,
,
欢迎加入非盈利Python编程学习交流QQ群783462347,群里免费提供500+本Python书籍!




剩余111页未读,继续阅读
2018-01-23 上传
2018-12-08 上传
2019-05-16 上传
2020-05-30 上传
2018-08-29 上传
159 浏览量
246 浏览量

weixin_44523404
- 粉丝: 1
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- TrabalhoFinalRedesNeurais:Projeto final do resoso reredes neuris e aprendizagemquénecée执行器模型执行YOLOv4和nvidia jetson nano e no colab。 比较结果
- barcode-scanner:用matlab编写的条形码扫描仪,可检测和识别EAN-13条形码
- Chrome NPAPI Replacement-crx插件
- DuckDuckGo Android App:适用于Android的隐私浏览器-开源
- p2p-gui:基于BitTorrent的JavaFX GUI对等系统
- 交换书
- staticdhcpd:用Python编写的快速,轻便,可高度自定义的DHCP服务器
- magento2-theme-frontend-blank:在制品
- dealers-choice-react
- SQLiteLearningProject:这个项目是让我熟悉SQLite集成到Android
- EPSON L380L383L385L485清零软件.rar
- 攻城
- semico Framework:加速构建应用-开源
- Live CSS Editor-crx插件
- termux-botnet
- selenium-sandbox:使用 Selenium Webdriver 执行特定任务的一组类。 用于教育、帮助、记住我以前做过的事情等
